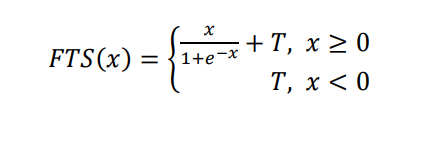I found a very interesting paper last night about a new activation function called LiSHT. The authors show superior performance over ReLU, Swish, etc. and thanks to this course, I was able to get up and jump into putting it into code and start doing some initial testing.
Short summary = impressive so far, but just used MNIST so far…ImageNette coming up.
Details - here’s the link to the paper:
What is it?
In math, it’s this:

Which I coded up as:
x = x *torch.tanh(x)
It behaves like a symmetric parabola:
I tested it initially with one of our intial notebooks and promptly got NaN gradients…possibly using BN will suppress this but to keep testing with the low level framework I modifed the GeneralRelu to add a mean shift and clamping. I called it LightRelu b/c
a)typing Lisht felt odd, light was easier and
b)concatenating relu on the end made it clears it’s an activation function.
class LightRelu(nn.Module):
#.46 was found to shift the mean to 0 on a random distribution test
# maxv of 7.5 was from initial testing on MNIST.
#Important - cut your learning rates in half with this…def __init__(self,sub=.46,maxv=7.5): super().__init__() self.sub=sub self.maxv=maxv def forward(self,x): #change to lisht x = x *torch.tanh(x) if self.sub is not None: x.sub_(self.sub) if self.maxv is not None: x.clamp_max_(self.maxv) return x
Similar to Relu, it shifts the mean and I found .46 adjustment drives to an ideal state. I put the clamping in for now b/c it explodes 5-8 runs in if you don’t.
The other big thing is to cut the learning rate in half vs normal. It does learn quite fast!
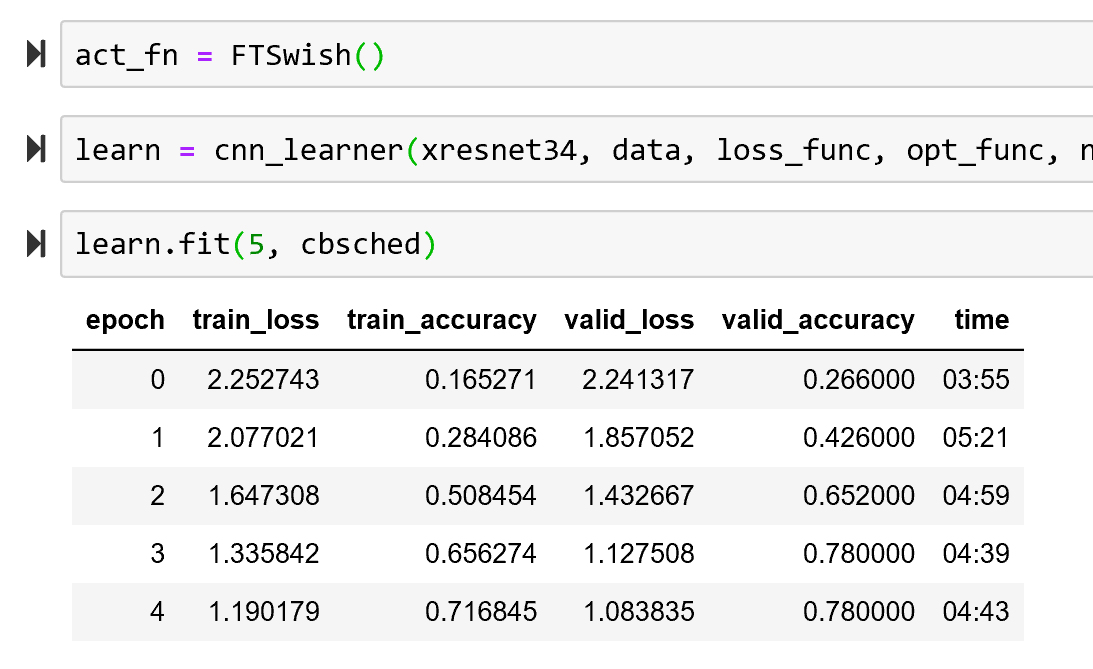
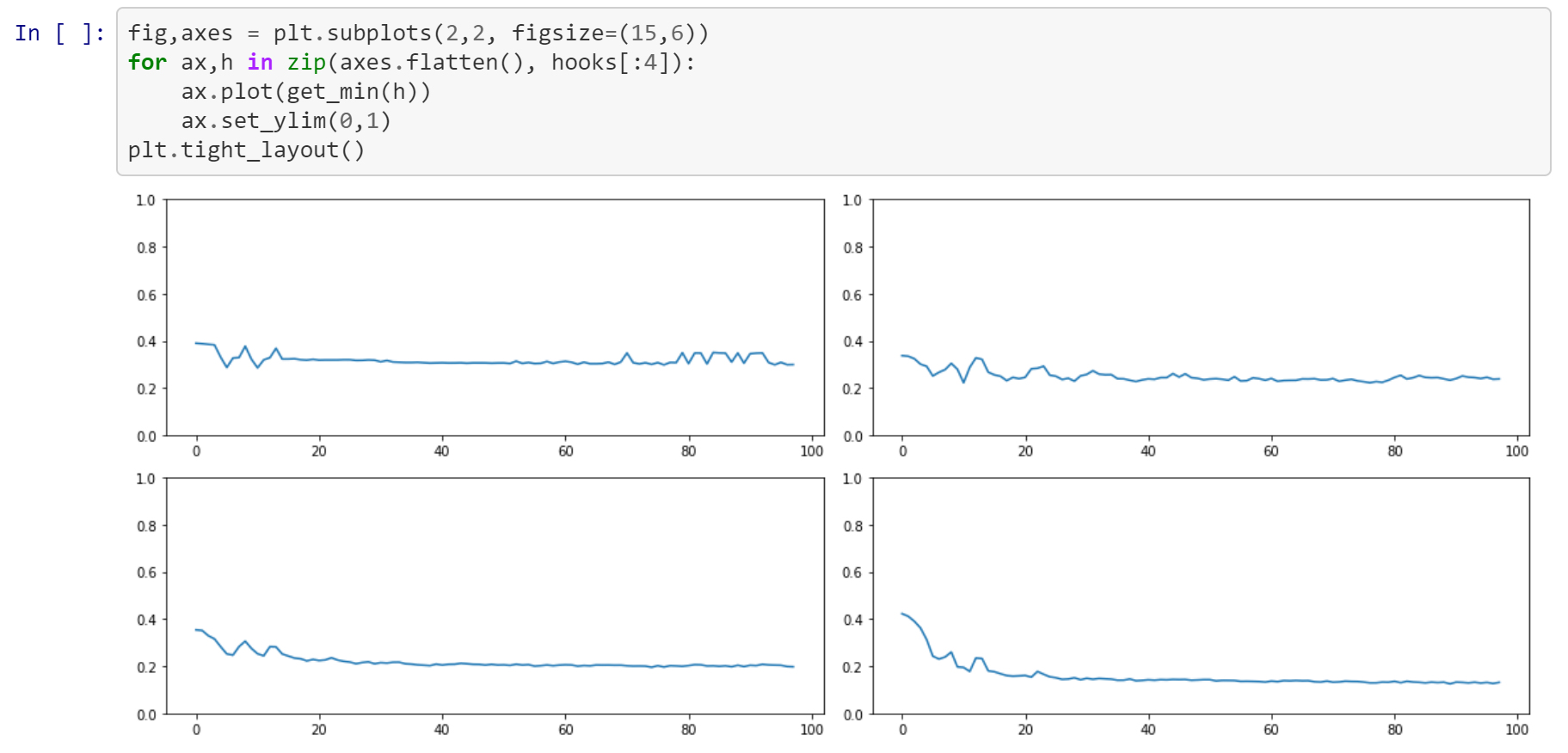
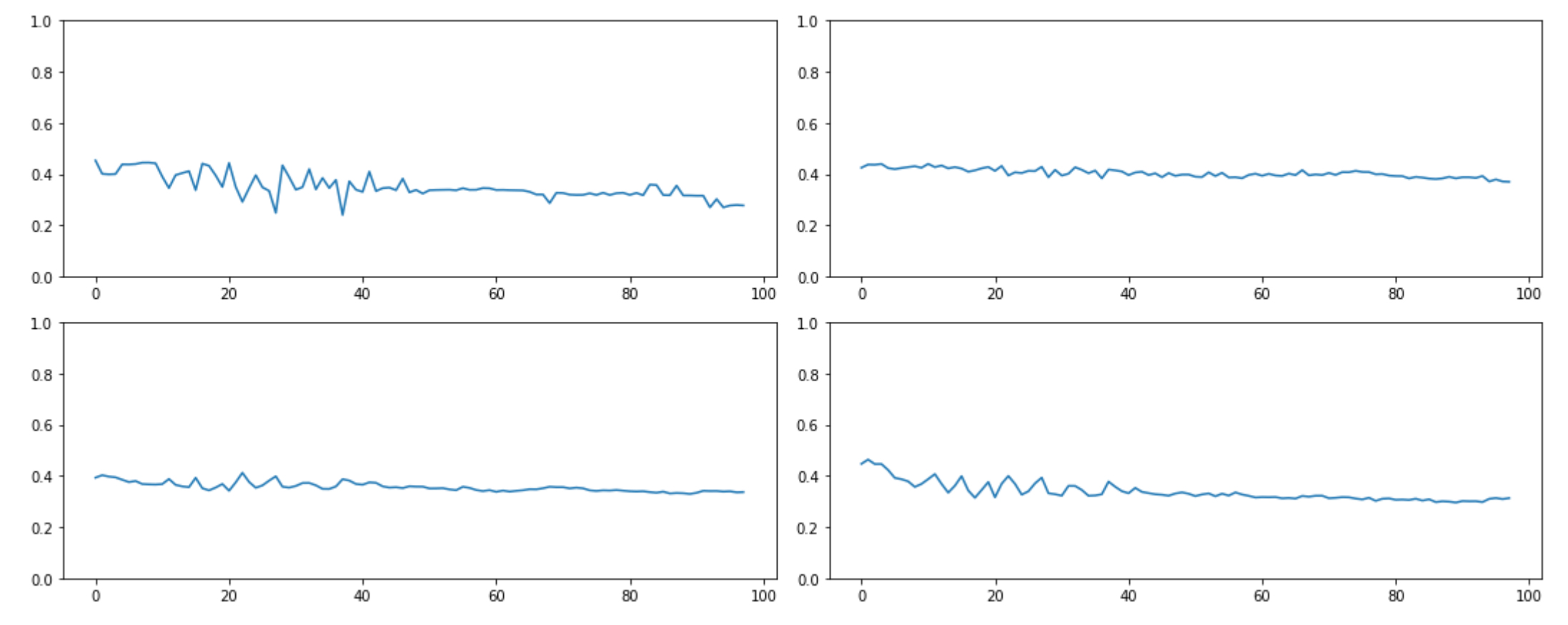
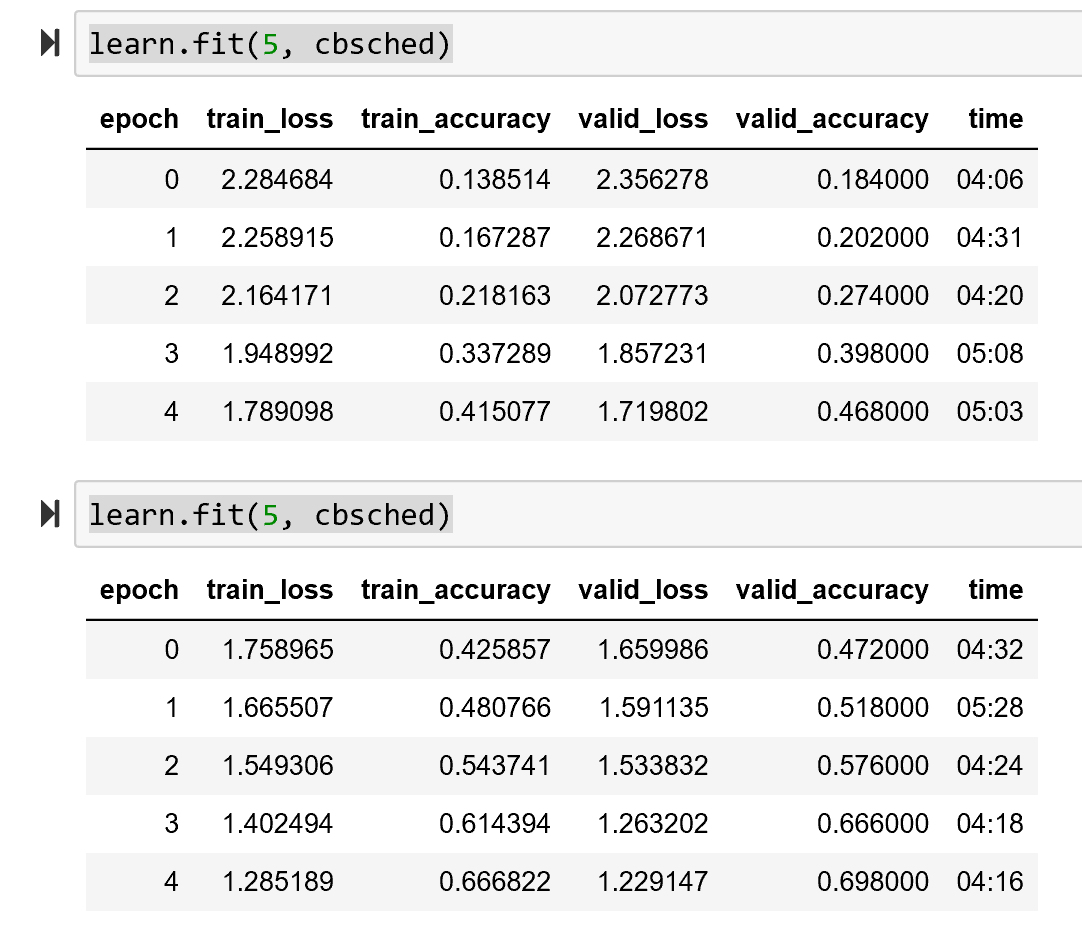
Some comparisons on MNIST with the basic conv framework in notebook 6:
Regular ReLU:
LightRelu(with shift and clamp):

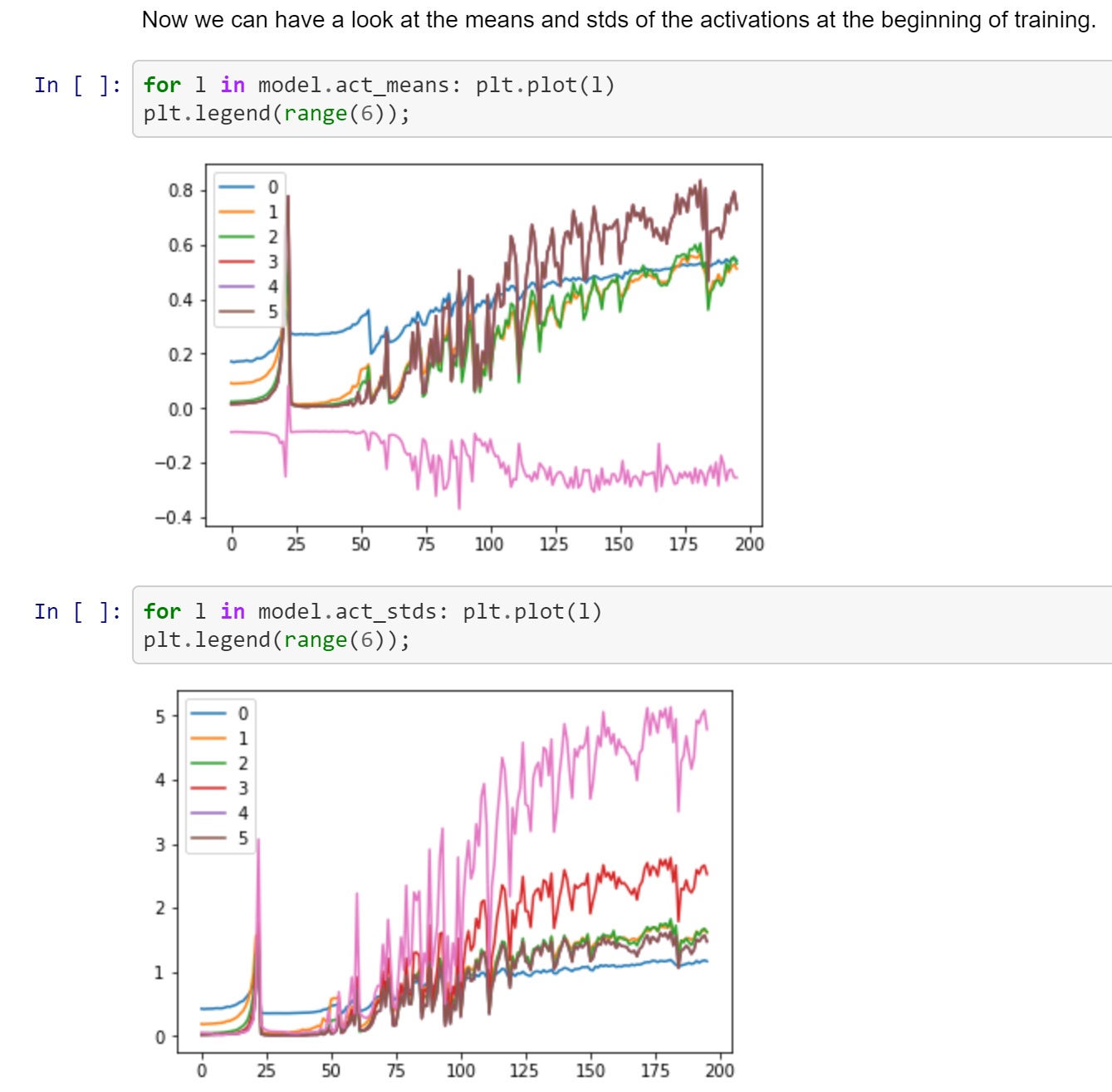
More interesting is the comparison with General Relu and LightRelu (both thus have mean shift and clamp):
General:
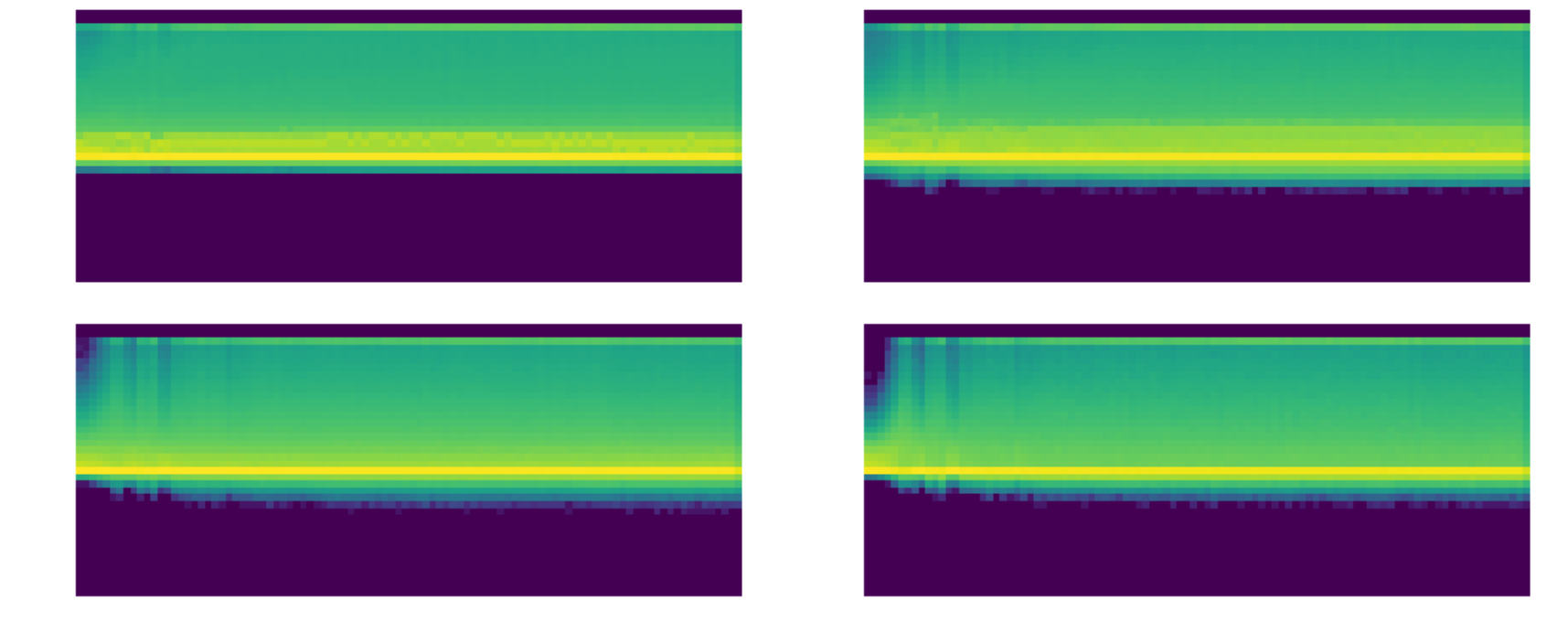
Light:
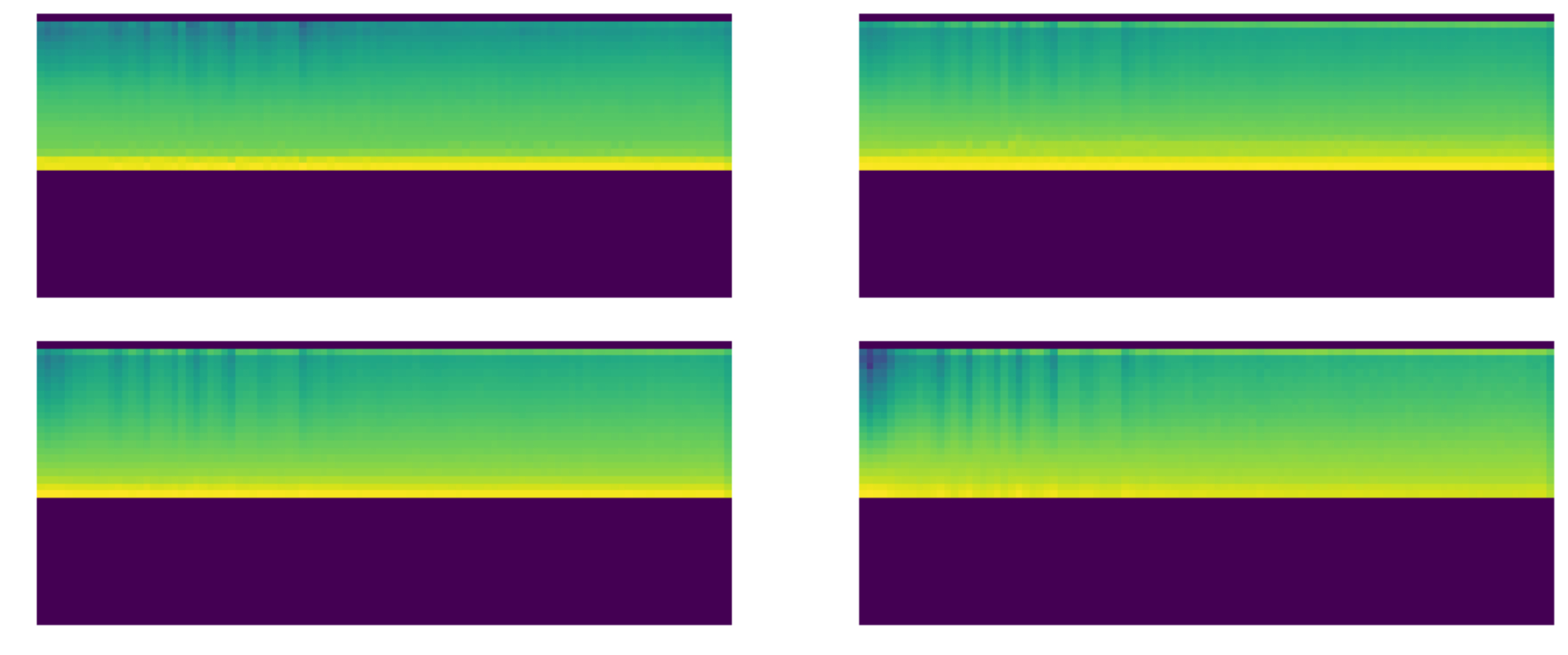
and min activations - LightRelu was nearly double by the fourth layer:
General:
LightRelu:
I’m going to test it with ImageNette next as that way it can be used with BatchNorm. The authors only used it that way and perhaps that removes the need for clamping.
Overall I did get consistenly higher accuracy on MNIST with the LightRelu. It also learns rapidly so it’s easy to blow up - learning rate finder actually doesn’t work well with it b/c it blows up so fast.
More to come…
 on a paper and improved it at least.
on a paper and improved it at least.