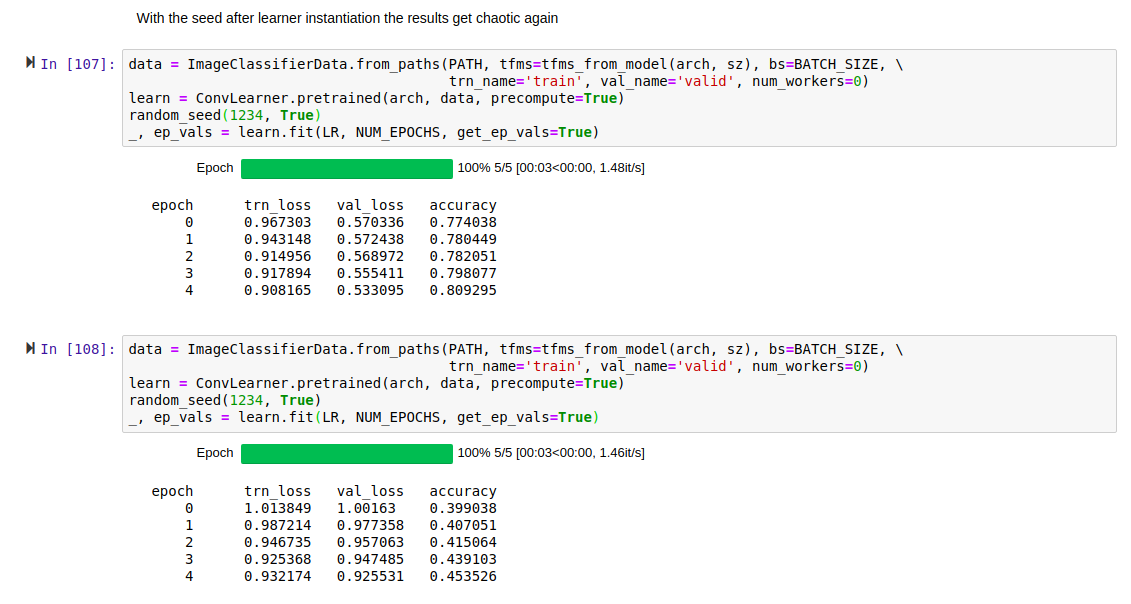
Another clue and partial solution.
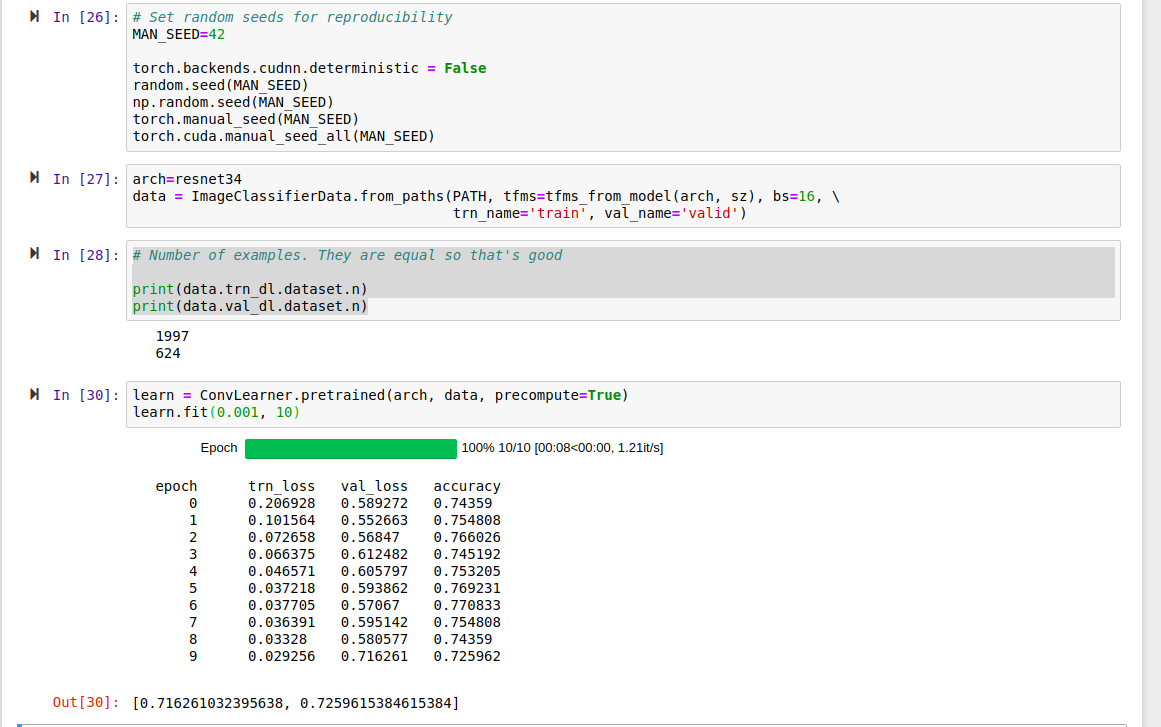
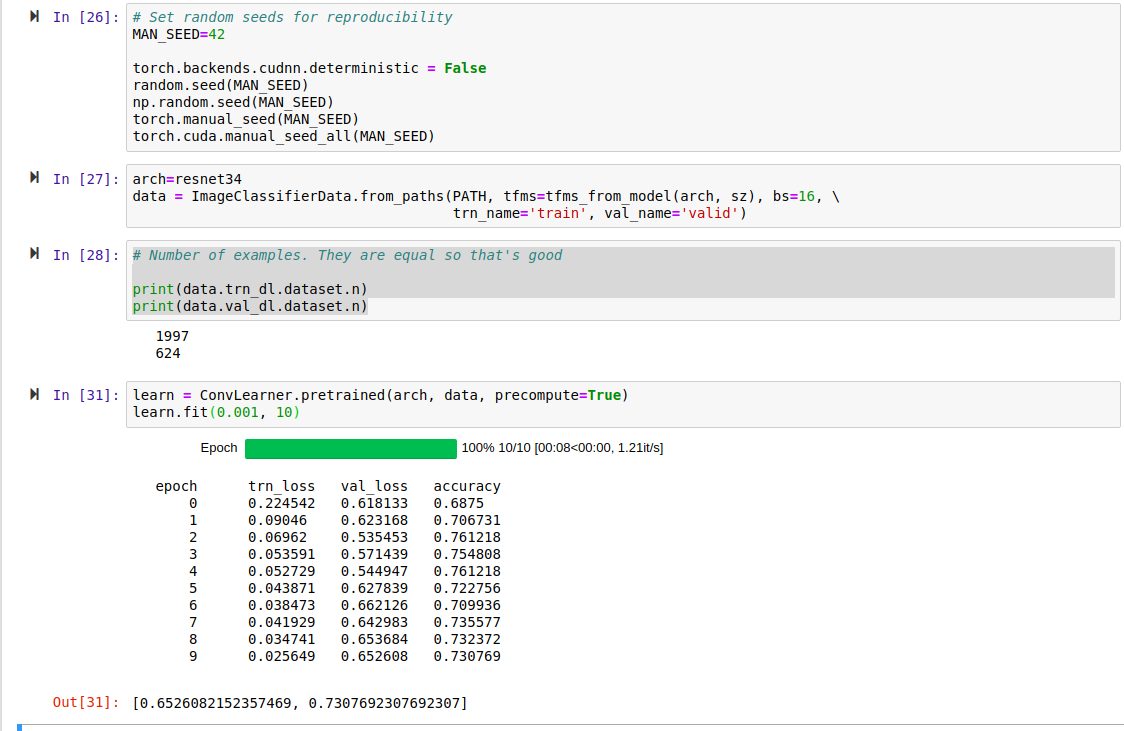
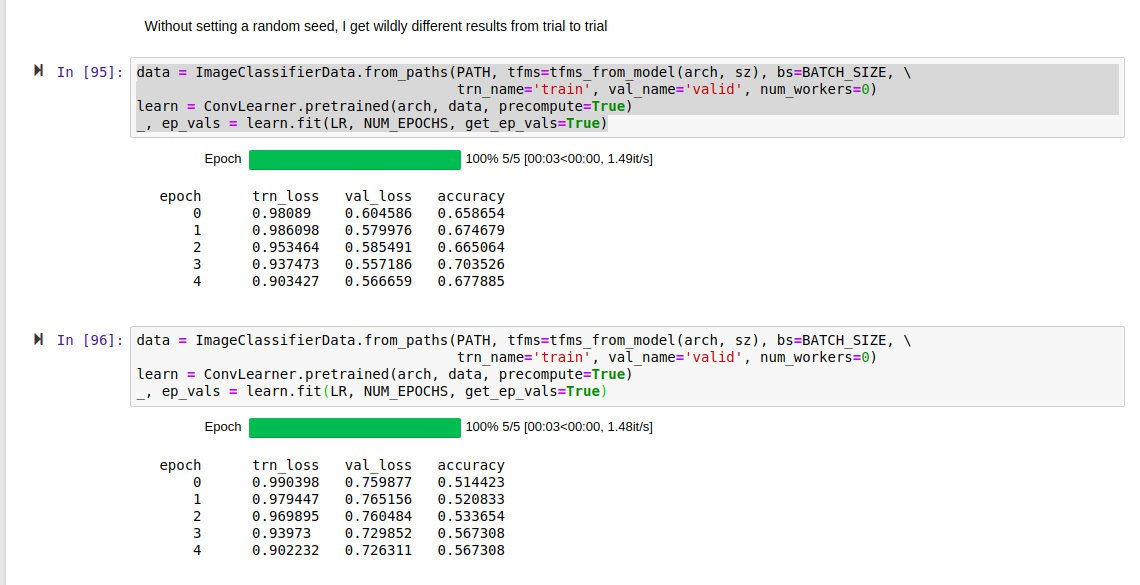
The issue is that after setting all the random seeds before creating the DataBunch, training and validation losses are inconsistent (non-reproducible) as of the first fit(). The losses have a bimodal or trimodal pattern. These observations are all after a kernel restart between runs, no transforms, and num_workers = 0.
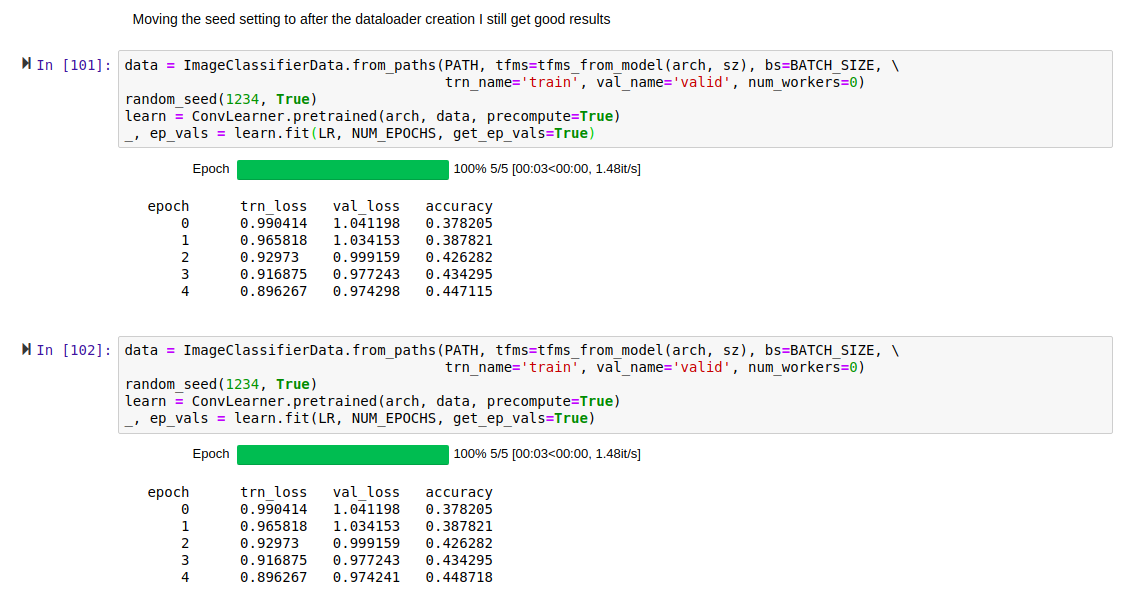
What I see is that setting these random seeds again before fit() yields consistent, reproducible loss results. However, setting them before create_cnn still yields the bimodal loss pattern.
Conclusions:
-
Setting random seeds before creating the DataBunch is needed to have a consistent Train/Validate split.
-
create_cnn, in this case Resnet50, leaves the random seeds set inconsistently. (It’s possible that both DataBunch creation and create_cnn leave inconsistencies.)
-
Somthing in fit_one_cycle() then uses a random seed, perhaps to shuffle the images. Because the random seeds are inconsistent across runs, the losses are inconsistent.
-
You can get reproducible results by setting random seeds before creating the DataBunch (with num_workers=0) AND before the first fit_one_cycle().
I should say these conclusions are tentative because 1) there are other explanations, such as a flaky GPU; and 2) I have not identified the source of the inconsistency. But I have spend a large number of hours getting to this point, and hope that a more competent developer will eventually investigate.
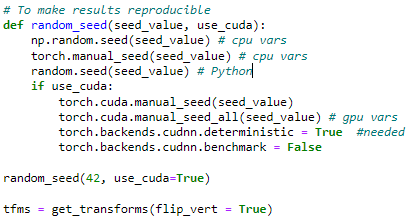
Here’s the function (originally by someone else) I use to reset every random seed I’ve ever seen mentioned:
def random_seed(seed_value, use_cuda):
np.random.seed(seed_value) # cpu vars
torch.manual_seed(seed_value) # cpu vars
random.seed(seed_value) # Python
if use_cuda:
torch.cuda.manual_seed(seed_value)
torch.cuda.manual_seed_all(seed_value) # gpu vars
torch.backends.cudnn.deterministic = True #needed
torch.backends.cudnn.benchmark = False
#Remember to use num_workers=0 when creating the DataBunch.
I hope this information can help anyone else who needs reproducible training. For myself, when trying to squeeze off fractions of a percent for a Kaggle competition, it does not work to have variations of 5% across training runs. With that much variation, small effects of changes to the model and parameters get lost in the noise.