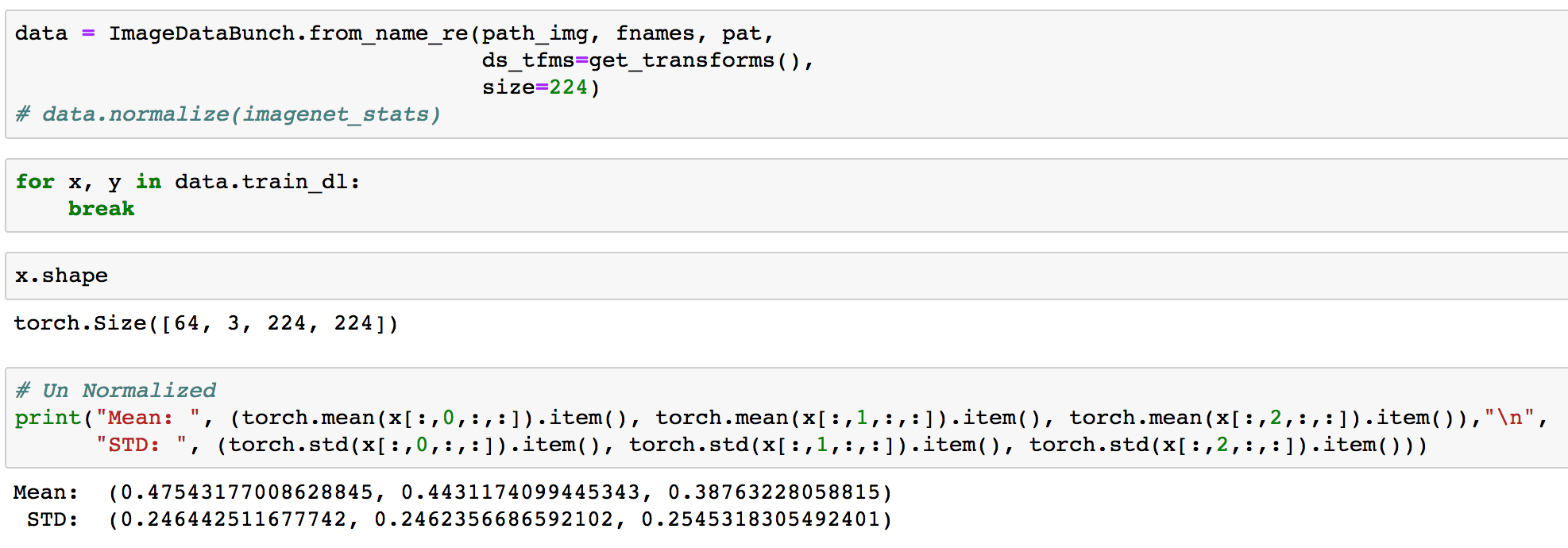
I was building notebook from the scratch. But I forgot to normalize the dataset with the imgnet_stats.
So, here the result with that.
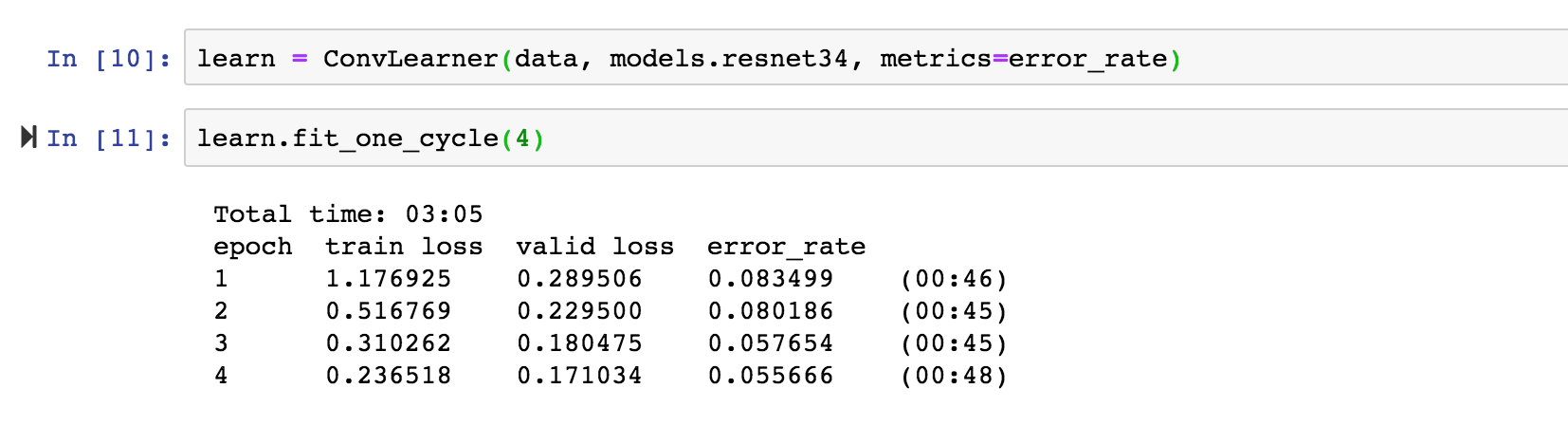
It looks good.
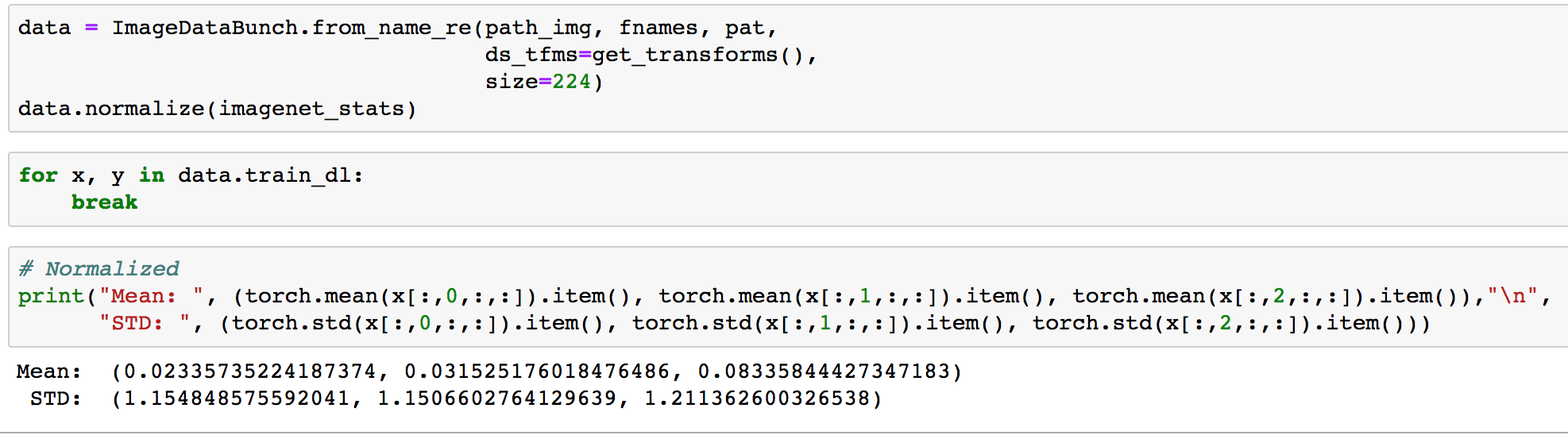
Then I add the normalization back and tried. Now the error rate is higher. Why’s that?
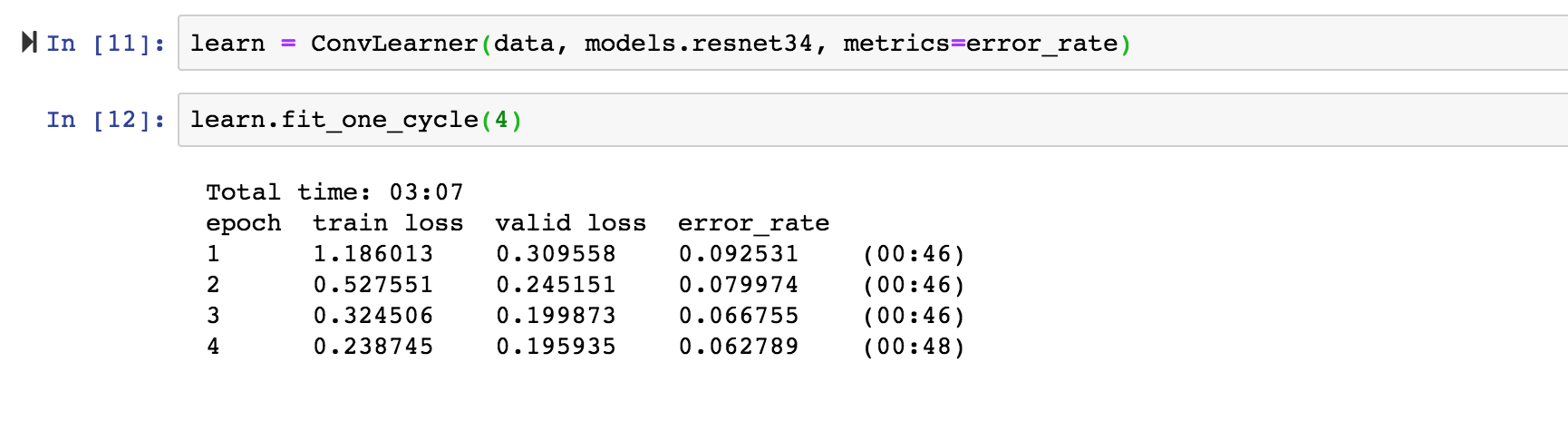
Why is that?
I was building notebook from the scratch. But I forgot to normalize the dataset with the imgnet_stats.
So, here the result with that.
It looks good.
Then I add the normalization back and tried. Now the error rate is higher. Why’s that?
Why is that?
When the image is read in and converted to Tensor, it’s normalized to a range from 0-1 as you can see below. Hence the Data is from 0-1 whether you use use Imagenet_stats or not.
But when you apply Imagenet Stats, it’s normalized to mean of Imagenet image stats (([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])) that the Model was Trained in, so it adjusts the inputs to Mean 0 and Standard Dev 1.
But regardless, Network will still learn, with or without Normalization to imagenet stats since the inputs are in similar range 0-1 or -1 to 1. Hope this helps.
Thanks. I understood your points.
My question was why it worked better with not-normalized images with imgnet?
May be that’s because both sets of images are different.
Anyway, I’ll keep this in my mind. I hope I’ll get answer in a future lesson.
IMO, because the Train Loss > Val Loss in both experiments above. The Model is “underfit” at this point and Training Loss is going Down on each Epoch. It needs to run for few more Epochs before we can conclude that one is better than other.
That’s a good point. I’ll try that too.