On the other hand there’s a difference between adding a constant to the pre-softmax activations, and having two inputs yielding pre-softmax activations that differ by a constant. So I struggled with that thought for a while before eventually going with “I don’t really know”
Jeremy/pomo bring up the good point that actual inputs might not be so nice – what if you fed a model a picture of a dog and cat together, vs a picture of nothing? Despite what I said earlier, if you told me that the former had large pre-softmax activations for cattiness and dogginess, and the latter didn’t, I would readily believe you. But surely we should just check an actual example.
Re: the uncertain category, it seems like reasonable “data augmentation”. Growing up I always found multiple choice exams that allowed “None of the Above” much more annoying than ones without.
By looking at the source code of zero_grad(), it calls .detach_() before gradients are zeroed. I interpret that as .detach_() cuts the computation tree upon each call of zero_grad().
If the zero_grad() is not called, the computation tree would keep growing for more than one epoch. Upon the .backward() call, the autograd logic would walk along the computation three and call .backward() method for every object it finds in it. If a tensor was multiplied in two consecutive epochs until the next zero_grad() is called, the backward method would for the tensor would be called twice and results of two .backward() calls would be summed up. What we accumulate is computation graph, but it appears to us as accumulation of values when the gradients are computed.
This is my theory, anyway. I might be wrong. May be somebody would correct me if I am.
I am not sure if I understood your points correctly, but I checked the documentation of .backward() and it says that “This function accumulates gradients in the leaves - you might need to zero them before calling it.”, the leaves are the tensors which have a grad part attached to them i.e. requires_grad=True (I think).
However, I did not fully understand the implementation and how it manipulates the graph since there is a variable called “retain_graph” so there is a choice of keeping it. Maybe the .detach() function in .zero_grad() is just a precautious measure so that the zeroing operation and what comes later is not added to the chain if the graph is retained
Actually looking into this in more detail, I’m not sure this is that important. detach_ sets it so future computations using this grad tensor aren’t included in gradient computations. But we only use it to update the parameters using SGD, which is already done without including those in gradient computations (using .data or with torch.no_grad).
So I’m guessing this is just here in case a user does some additional calculations with this tensor. But I’m not 100% sure - I might be missing something.
thanks @sgugger that helps!
would you be willing to point out the most important bits that we should try to master first? the ones that are most important on the bigger picture or without them would be difficult to move forward. maybe there are some nice to have things that can be mastered later… just trying to mange time and prepare for our study group meetup this sunday. i hear similar comments about lesson 9 from others too and this helps me not to feel bad about it lol…
that would be much appreciated! thank you!
You’re right, they’re just functions—if the name “callback” is weird to you, just think of them as functions. They’re called “callbacks” because of the English expression “to call (someone) back”, where the idea is that if you give me your number, I can call you back when I feel like it/am ready to; in programming, calling a function a “callback” conveys the idea that you’re handing it to someone so they can call you back when they’re ready, sometime in the future, or maybe even never.
Is this Python thing anything to do with the Javascript thing? If I understand correctly in JS callback is something the code will wait and the result doesn’t need to be given right away. And if Python is not waiting anything (like I expect) why aren’t we using callback name when we are talking about functions? Same way we give them some values and expect to get something in return.
Yep, callbacks in Python are the same idea as in Javascript, although they’re generally more common in JS because so many JS things happen asynchronously: call me back when somebody clicks on this button, call me back when this API response arrives on the network, etc.
In the fast.ai library, you’re similarly waiting on something asynchronous: call me back once the next training epoch is about to start (that could be a while in the future), call me back once you want to know the next learning rate (that could be a while in the future), etc.
For a situation where you (usually) would just use the term “function” rather than callback, take Python’s map function, e.g. map(lambda x: x + 1, [1,2,3]). The lambda you pass here is going to get executed immediately, there’s no notion of “yeah hopefully let me know if you have any numbers I can add one to”. It would sound a little weird to call the lambda a “callback” rather than just a “function”, but eh, some people do.
The thing is you need to have a general understanding of all the bits presented to progress. Going into the fine details can wait, for instance you can skip what exactly is Kaiming initialization and just remember “We need a good init and pay attention to that.”
The first part is to understand what are the big topics seen in lesson and what is their respective importance. Going back to some parts of the lessons in part one might help with that. Then you can dig in the details of the implementation.
Otherwise, I’d say the Callback system is pretty important but I’m biased since I love Callbacks
Going back through the lesson 9 video on the topic of initialization and I had a thought that I’m not sure is really useful … but here it is:
Would it be useful to include in the framework something akin to lr_find but for initialization settings (e.g., an init_find) that runs a subset through your network and reports out best mean and std scores for various initialization settings?
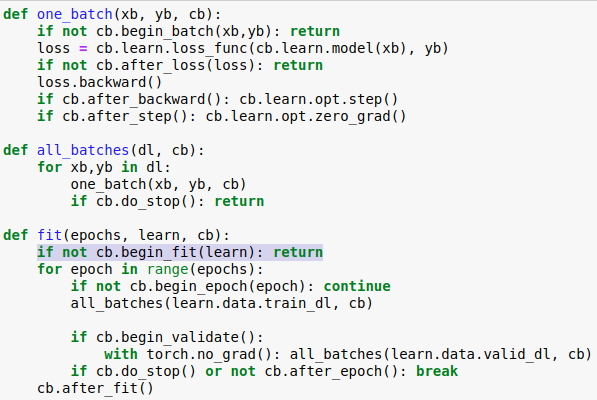
Can someone explain this thing:
Why we would want to stop fit function by returning none before even starting training? Why there is actually always return after callbacks? is this required or just something which make the code generalize better? But why there is this cb.after_fit() but still we are returning True although we never use it?
And why this part:
res = True
for cb in self.cbs: res = res and cb.begin_fit(learn)
return res
is not written like this:
for cb in self.cbs: res = True and cb.begin_fit(learn)
return True
Final thing: Is it correct that the idea of callbacks in Fastai library is to just make it plausible to add any code to the places where there is callbacks? We define some basic structure for these because begin_fit should include certain kind of code. For example if we want to save the losses to csv we can do this with callbacks instead of needing to modify the original fit function. And where we want to add this code? Well, after we have calculated the loss but it is even better to add it inside after_loss function because this is designed for this but basically it could be also added to after_backward.
as @cqfd writes callbacks is used by the publisher of a service to callback to the subscriber. It is a very power full design pattern to create loosely couple designs (separation of concerns) thereby improving the maintainability and readability of af library/service
The result of the cb.begin_fit(learn) call has been accumulated on this res variable. As you can notice res and cb.begin_fit(learn) is boolean operation and can be seen as res = ( res and cb.begin_fit(learn) ).
You can print, save, or do some manipulations inside callback. It is easy was to get values or terminate operation without changing library.
I didn’t study the callback system in detail yet so this answer is just based on intuition and might be completely wrong :):
My guess is that if someone wants to implement a different kind of fit() function via a callback, they could set cb.begin_fit(learn) to return True to avoid starting the standard fitting.