Freeze the initial layers , especially the embedding’s one as they are quite heavy to start with!
1 Like
When training my language model, the GPU is only running at 20% even when I’m using large batch sizes (like 1024).
My language model has a sequence length of only 8, but that’s justified by the nature of my dataset (musical chords). Is this the reason why the GPU is so under-utilized?
1 Like
Make sure the batch size is as large as can fit in GPU memory.
1 Like
Wouldn’t freezing the embeddings defeat the purpose of fine-tuning on a new corpus as you want the model to learn the new vocabulary of the new corpus?
1 Like
You still have the last layers of the network that you are fine-tuning.
Also, I may be incorrect, but I thought Jeremy mentioned fastai automatically freezes the initial layers. I may be wrong though.
Since RNNs are free to generate an output sentence with different number of words than the input sentence, I was thinking it might be able to express a given input sentence in different words (?)
AFAIK translation models do not use RNNs. They would use a seq2seq or transformer-based architecture. I don’t think therefore this statement is necessarily valid.
I’d guess that the vocabulary of a corpus is actually a fairly high-level representation of the semantic meaning. If so, then the low-level semantics and sentiments are captured in the frozen embedding layers, and the hope is that they are fairly universal. (Perhaps not so from English to genomic sequences or sheet music.)
Seq-to-seq models are also free to generate an output sentence with a different length than the input sentence.
1 Like
Please remember to use the non-beginner topic for non-beginner discussion, and please focus on questions about what Jeremy is talking about right now 
5 Likes
Why give similar weights to each word (token)? What if the last token has more effect on the predicted token?
We use the same weights for the input, not the same embeddings. Each different token gets its own embeddings.
1 Like
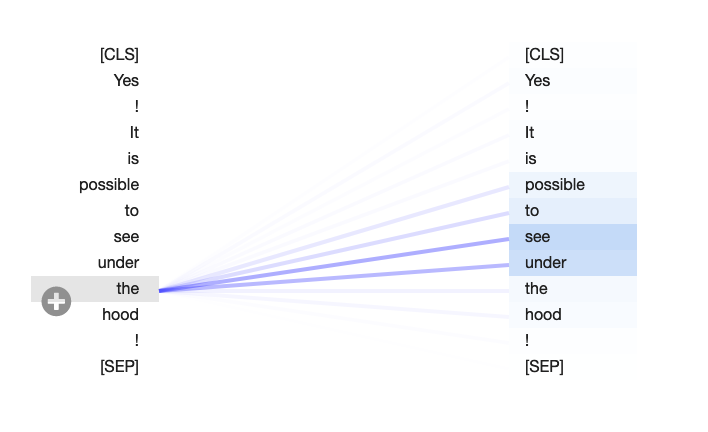

Is n in loop of the recurrent NN would map to the sequence of the DL? like if the size is 72 then it would loop 72 times?
1 Like
Sorry just saw your note…
Yes, exactly.
1 Like
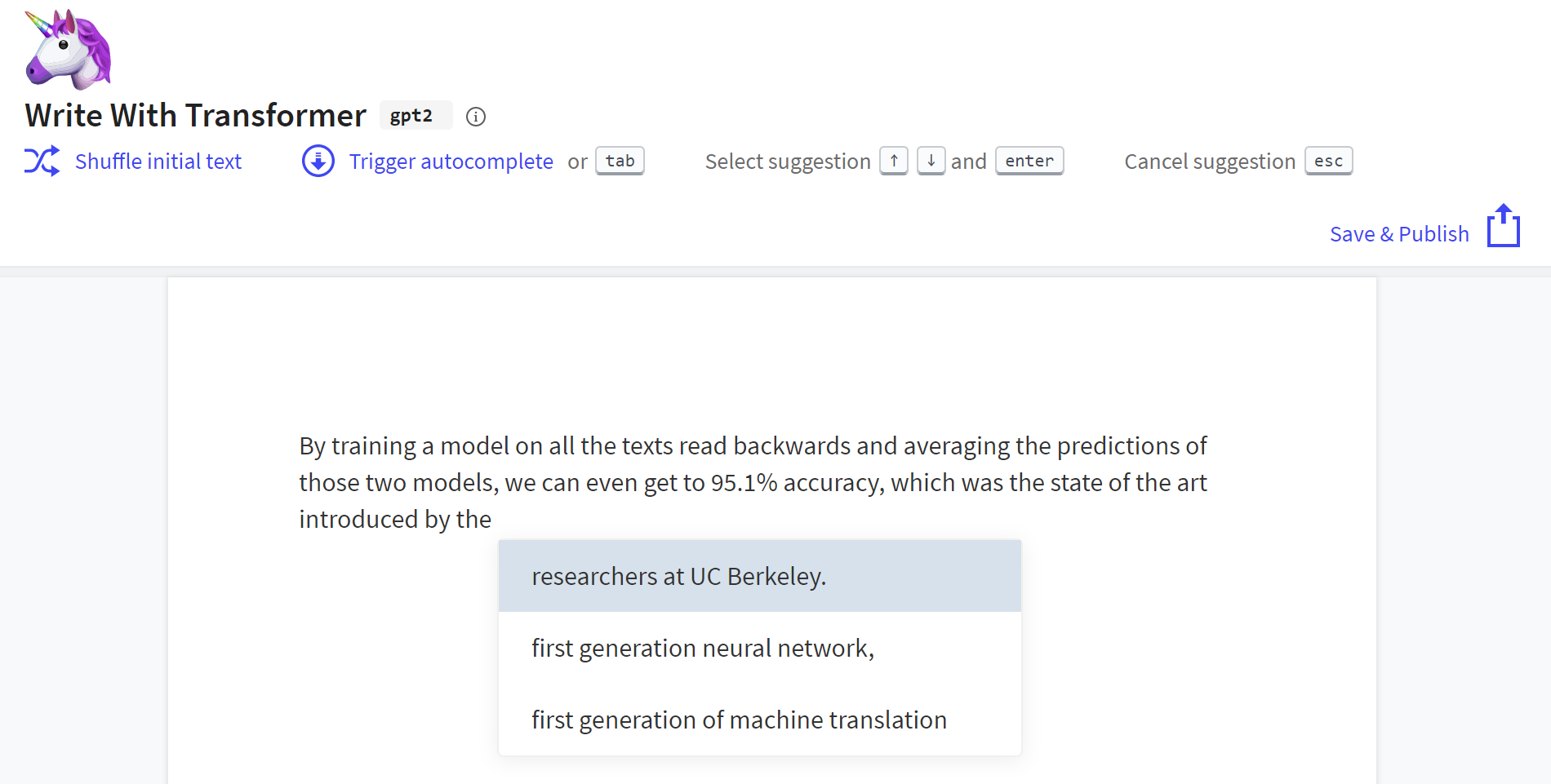
how were these generated?
Thanks 
Is LMModel3 a 4 layer model because of h? Or is a 3 layer model since there are 3 nn objects?