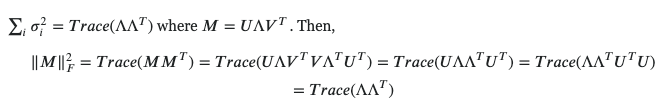The Frobenius norm of a matrix is the square root of the sum of the squares of its elements; it provides a rough measure of the “size” of the matrix.
Wikipedia gives three ways of expressing the Frobenius norm of a matrix whose elements are real numbers:
\|A\|_{\mathrm{F}}\equiv \sqrt{\sum_{i=1}^{m} \sum_{j=1}^{n}\left|a_{i j}\right|^{2}}=\sqrt{\operatorname{trace}\left(A^{T} A\right)}=\sqrt{\sum_{i=1}^{\min \{m, n\}} \sigma_{i}^{2}(A)}
Here, the superscript ^{T} refers to the transpose matrix, and the singular values \sigma_{i}(A) are the square roots of the eigenvalues of the matrix A A^T
The third expression is the square root of the sum of the eigenvalues of A A^T; although mathematically interesting, it’s not the best way to compute the Frobenius norm.
Let’s demonstrate the equality of the 1st and 2nd expressions. Suppose A is an n\times m matrix, i.e. A has n rows and m columns.
Then
A^{T} A is an m\times m matrix whose diagonal elements are
A_{j} \cdot A_{j}, where j runs from 1 to m, and
A_{j} \equiv (a_{1j}, ..., a_{nj}) is the jth column of A.
The diagonal elements of A^{T} A are evidently the set of dot products of each column of A with itself.
\operatorname{trace}\left(A^{T} A\right) is defined as the sum of the diagonal elements of A^{T} A,
which is just the sum of the squares of all the elements of A.
QED
It’s interesting to note that the order of the terms in the product of the matrix with its transpose doesn’t matter, giving rise to an alternate form for the Frobenius norm:
\operatorname{trace}\left(A^{T} A\right) = \operatorname{trace}\left(A A^{T} \right);
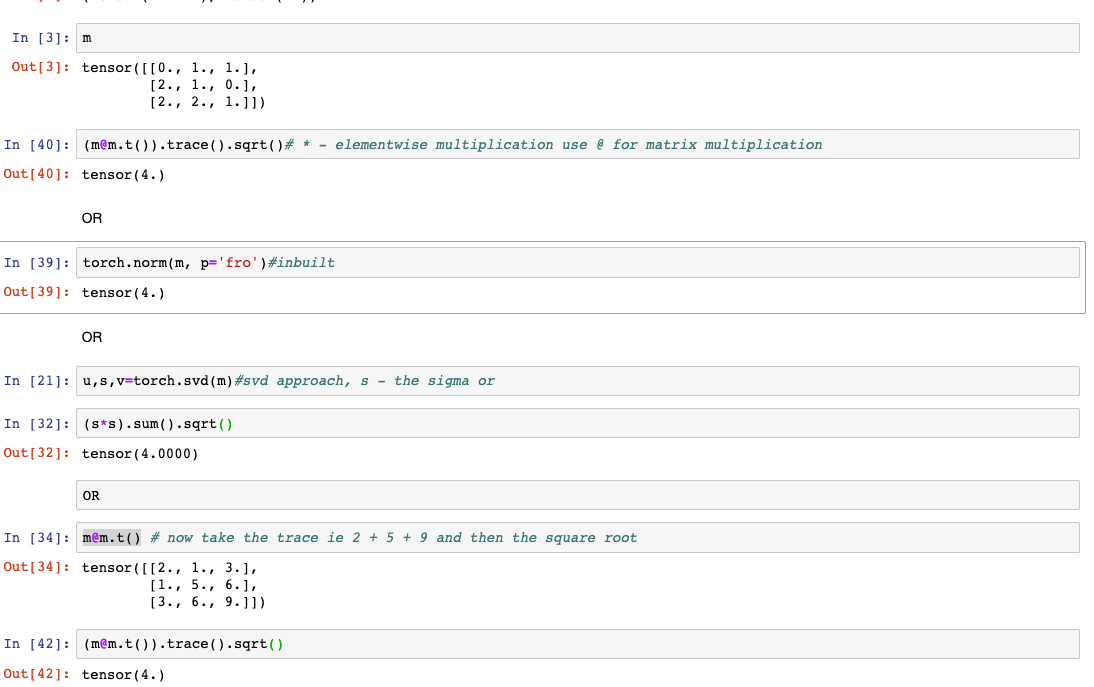
\operatorname{trace}\left( A^{T}A \right) is the sum of the m dot products of the n\times1 column vectors of A with themselves, while \operatorname{trace}\left(A A^{T} \right) is the sum of the n dot products of the m\times1 row vectors of A with themselves. The expressions are equivalent because each reduces to the sum of the squares of the elements of the matrix A. Their computational complexity is O(mn), which is lower than that of the singular value decomposition required to compute \sigma.
 .
.