You’re right, see my answer a few posts above. I guess Jeremy just got unlucky with his RNG 

source: https://dilbert.com/strip/2001-10-25
You’re right, see my answer a few posts above. I guess Jeremy just got unlucky with his RNG
Thanks! For others, looks like free registration is required to join the TWIMLAI slack channel.
I started and others have contributed to the wiki portion at the top of this topic some “Assigned homework” tasks.
You’ll probably get more help if you actually show your results and ask your questions in the forum.
Also, please don’t at-mention fast.ai staff asking for help. Since you’re here in the part 2 forums, I’m surprised you don’t know that. Especially since it was mentioned on the slides in lesson 1, and is in the FAQ.
If you ask again in this way, I suspect you’ll get the answers you need.
Can you please use this forum category instead of slack? Slack is not readily accessible, is not indexed by google, and often is not permanently archived. Everyone invited to participate remotely has been a strong contributor to this forum community, so let’s keep that going! ![]()
I haven’t really thought thru it carefully - but I think that in the following layers, you now don’t have a zero-centered input, which would impact the variance of the next layer. Does that sound right?
The variance estimate Vhat depends on the mean estimate xhat :
Vhat = mean_over_i(( xi - xhat )**2)
so that if the mean is based, the variance will be based as well. Therefore, we should expect improving the accuracy of the mean to also improves the accuracy of the variance.
Did anyone find out the answer to this?
For this course, is it recommended we use the bleeding edge developer install …
git clone https://github.com/fastai/fastai
cd fastai
tools/run-after-git-clone
pip install -e ".[dev]"
… or is it sufficient to just stay up-to-date with the latest release via …
conda install -c pytorch -c fastai fastai
My sincere apologies, I was not able to summarize all the details in here so I posted the links to the notebooks.
I also didn’t forget about the at-mention rule, I saw some recent replies and thought I might request some direct help if he is available at that point in time. Will not repeat for sure. I apologize again.
Since we rebuild fastai from scratch, it’s not necessarily important to have the bleeding edge. At least not until the lessons where we’ll tackle things like object detection or seq2seq. That being said, having two environments with last release and an editable install is good if you want to quickly check something that was just added.
No need to apologize! I just wanted to make sure that you got the help that you needed.
This one’s cute: https://www.youtube.com/watch?v=BGbiHdKHG7o I think a different tune, but the same.
@ 1:04:22 of the edited version
Jeremy replaces a[i].unsqueeze(-1) by a[ i , None]
Shouldn’t it be a[i] [:, None] ?
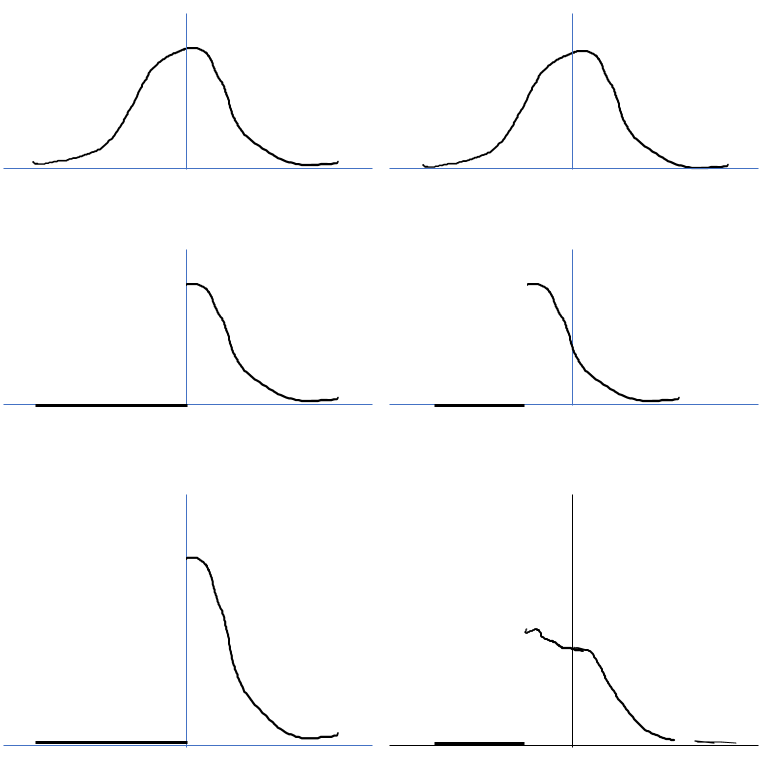
yes. exuse the awful sketch… someone can replicate with maths…
If we start with identical normal distrivutions (bell curves), take relu, left side is typical, right side with clamp -0.5 thats the top 2 rows below
Third row is a hack… but if we multiply the above two rows you can see the distribution changes. Thats effectively what you’re saying happens in layers. And the shift and multiply builds each layer
So thats my intuition from work… someone can probably experiment by the time I get back here
seems like after RELU() after there should be a really huge spike at the Y-axis i.e. at value zero, as all the negative values on the left-hand side of the bell curve become zero. The number of data points N remain the same, so all those previously-negative values get stacked up at the Y-axis.
If so, due to broadcasting x.clamp_min(0.) - 0.5 could be pushing those zero values back to negative region at -0.5 while reducing the remaing positive values by 0.5
I wonder if its because those codes are in written in C (torch.randn returns <function torch._C.randn>), which prevent us from looking at the source code? maybe thats why ??torch.randn only returnd the docstrings
what plugin is needed for VSCode to display git commit messages like this?
For those of you thinking about S4TF’s future, here’s my math for the success of S4TF as a major ML platform:
pLinux * pMac * pWindows * pMLIR
where pLinux, pMac, pWindows are probabilities of achieving production quality implementation of S4TF for those platforms, pMLIR is probability of production quality implementation of MLIR (https://llvm.org/devmtg/2019-04/talks.html). There’s many other success reducing probabilities but this, IMHO, foretells the future and the magnitude of work needed.
The idea of developing totally in jupyter is great. I love this tool. But there are still something confused me. After exporting all the dev_nb to nb.py, one need to reintegrate it to the library right ? How can we do that other than copy paste the code ?
How about testing ? I read some thread about testing in fastai and it seems that we test in python environment than jupyter notebook. Is there someone use pytest in jupyter ? I searched about this and someone told that it is not recommended. After reading 2 blogs about Machine Learning pipeline by Radek now I think I need to test my code. The Notebook is so flexible that sometime it makes my environment so messy.
Thank you in advance,