I don’t really get why that would happen, since loss and accuracy generally have inverse relationship. Maybe someone can elaborate a bit?
Ya that happens. I’ve seen it during training sometimes. I am not very sure why, but it may be related with exploration of the loss surface. I might be completely wrong here too.
where would the ppt presentations for each lesson be posted?
I wanted to ask the same question as well, and I just messaged the USF people to see if they know
Usually a loss function is only a proxy of what we really want to optimize. For example to maximize accuracy we often minimize cross entropy, because it’s differentiable, thus we can use gradient methods. However, even though there is some inverse correlation between cross entropy and accuracy, it’s not always the case that a lower cross entropy implies a higher accuracy. Consider a binary classification example with 100 samples and two models. The first model has 100% accuracy and it assigns probability of 0.51 to the correct class. Its (binary) cross entropy is then -ln(0.51) ~= 0.67. Now, the second model “is 100% confident” of k examples, and for the 100-k remaining examples it wrongly assigns probability 0.49. Then the accuracy is k/100 and loss is (1-k/100)*ln(0.49) ~= (1-k/100)*0.71. With k = 6 you get accuracy 6% and the loss near the loss of the first model. With k=50 you get 50% accuracy and a binary cross entropy ~0.36, much lower than that of the first model. Of course it’s only a toy example, but I hope it presents the idea.
5 Likes
I’m not sure if this is what’s actually happening in that case but there are situations where loss and accuracy can both increase (or both decrease).
The loss factors in how “sure” the network is of the answer and accuracy is just how often it’s correct. You can imagine a situation where you “give” some certainty on some examples (and loss will increase) in exchange for higher accuracy.
Imagine this simplified example with 2 only items in your validation set:
Item 1
Correct answer: Class A
Predictions:
Class A: 100%
Class B: 0%
Item 2
Correct answer: Class B
Predictions:
Class A: 51%
Class B: 49%
Accuracy: 50%
MSE Loss: 0.13
Now you run another epoch and your validation set predictions look like this:
Item 1
Correct answer: Class A
Predictions:
Class A: 70%
Class B: 30%
Item 2
Correct answer: Class B
Predictions:
Class A: 49%
Class B: 51%
Accuracy: 100%
MSE Loss: 0.165
This effect would be more pronounced if you had some mis-labeled data. In “exchange” for pushing the certainty of an incorrect answer higher (because it’s mislabeled) you may move some other examples it’s less sure about over the border from incorrect over to correct.
3 Likes
Ok that is convincing to bridge my almost 20 years gap between object oriented and functional programming. Probably by laziness, I was searching reasons to not follow your recommendations. Starting to learn Swift tonight. Damn part 2 invitation.
8 Likes
trying to get behind RL scepticisim I sometimes hear in the community. While I am not competent enough to judge and have no real opinion, this here seemed interesting: https://thegradient.pub/why-rl-is-flawed/ @gmohandass
1 Like
great class, indeed ! need to go through this again too.
Working thru the notebok 01_matmul I tried this:
`c1 = tensor([[1],[2],[3]])`
`c2 = tensor([[1,2,3])`
c1,c2
(tensor([1],
[2],
[3]),tensor([[1,2,3]]))
c3=c1+c2;c3
tensor([2, 3, 4],
[3,4,5],
[4,5,6]])
but :
c4 = c1.expand_as(c2)
fails with:
RuntimeError: The expanded size of the tensor (1) must match the existing size (3) at non-singleton dimension 0. Target sizes: [1, 3]. Tensor sizes: [3, 1]
so there’s more going on here than just the expand_as before the tensor operation.
Hi, I might be wrong but if you compare equation of sigmoid vs RELU its is big difference in complexity.
Computer do very fast adding and shifting bits other operations are very expensive RELU do pretty good job and id very easy to compute
Right - read the ‘broadcasting rules’ section to see what actually happens.
I am not sure if that is what is really happening, but this would be my take on this:
As we continue to train our model, it becomes more confident in it’s predictions (for a classification problem, the outputted values grow closer to 0 and 1). Overall, the model is doing a better job at classifying images (accuracy keeps increasing) while the loss grows as well. That is because for the now fewer examples that are misclassified, as the model becomes more confident in its predictions, the loss increases disproportionately.
If we look at how the cost is calculated using cross entropy, the more wrong the model is (difference between predictions and ground truth approaches 1) the cost asymptotically approaches infinity IIRC. So the few misclassified examples count by a lot.
Now, I don’t think this could happen if we were considering all examples in the dataset during training. But as the loss is calculated on a batch of examples, the model can still be learning something useful, becoming better overall, while we see an increase in loss (though here we probably only care about the validation loss so that is a slightly moot point).
EDIT: The image below is showing the effect:
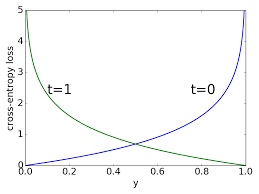
For a positive class, notice how little the cost grows from a predicted probability of 0.6 to 0.4. For as long as the model operates in that middle ground the cost changes slightly. But observe the explosion in cost as the predicted probability approaches 0!
Image taken from these lecture slides returned by google search.
15 Likes
That’s the key insight! ![]()
What happens is that for the start of training, the model gets better at predicting, and more confident (correctly) of those predictions, so accuracy and loss both improve.
But eventually, additional batches only make it slightly more accurate, but much more confident, such that that over-confidence causes loss to get worse, even as accuracy improves.
Since what we actually care about is accuracy, not loss, you should train until accuracy starts getting worse, not until loss starts getting worse.
25 Likes
I’ve just added them to the top post of this topic.
3 Likes
This article has also a nice visualization and explanation for broadcasting: https://jakevdp.github.io/PythonDataScienceHandbook/02.05-computation-on-arrays-broadcasting.html
1 Like
Hi fellow students,
I started with the matmul implementations as discussed in the lesson and found few interesting things that I would like to share. I also came across some observations which needs your review/help, they are marked as TODO in the notebooks.
Update: tagging @sgugger for help
3 Likes
I will share my interpretation. Please, correct me if there’s something wrong: What we really want to track is the metric, not the loss function. We use the gradient of the loss instead of the metric for updating the weights because the loss is better behaved. On the other hand, the metric provides a “human readable” value that allows us to judge how good or how bad is the model. However, in regards to this part:
Remember we discussed in part 1 that your accuracy will keep improving even after your loss starts getting worse.
Can anyone point me which lesson was this behaviour observed? In my mind, the loss and the metric would somehow have a correlation. For example, in regression problems, R2 score is just a normalized version of MSE.
Does anyone know how much research has been done into S-shaped RELU activations? That is:
-k if x < -a, k if x > a, else x (or other versions)
This would also have a zero mean.
First hit I found was this which shows positive results, but fairly old network architectures: https://arxiv.org/pdf/1512.07030.pdf
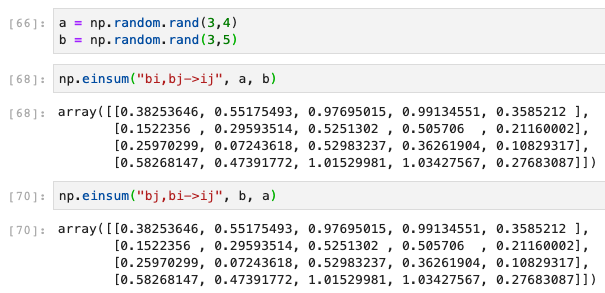
You are right, I did not pay attention to bi and ib part. What I meant is that the order of input arrays doesn’t matter (while it does matter for regular matrix multiplication with @ or matmul)
For order of the arrays, einsum will figure it automatically (of course it is a different thing and not what was asked in the original question):
1 Like