That makes sense, I see how it is used now. Thanks Rachel!
1 Like
For anyone who’s interested in what Jeremy is doing right now (implementing a neural net from scratch, following the PyTorch style API of creating modules etc.),
you might find this excellent course from Andrej Karpathy (who’s now the Director of AI at Tesla) very useful.
It really gives you the nitty gritties and gets your hands dirty.
Plus, it’s Andrej!
So, why not 
Highly Reccommended
4 Likes
I was reading The Matrix Calculus You Need For Deep Learning the other day, minor issue but there seems like a subscript missing in section The gradient with respect to the weights?

confused me for quit a while
1 Like
Thanks! great class.
Great lesson ! Quite a bit to think about until next week  Thanks to the fastai team !
Thanks to the fastai team !
1 Like
probably a transpose
Eh, I realize with an answer earlier that it shouldn’t have worked, but yet it did. I’ll need to double check tomorrow why.
1 Like
Great class. Thank you for opening this up to us!
For those who don’t have the link to the paper: https://arxiv.org/abs/1802.01528
thanks to @PierreO who pointed out that it can also be found more directly here: https://explained.ai/matrix-calculus/index.html#sec6.1
Adding onto this and Paul’s reply, I find myself refactoring problems into the data In/Out paradigm of normal deep learning – and this is for robotics, one of the main focuses of RL.
1 Like
Would be fun to try to code everything we learned today in swift
1 Like
This class was quite the fire hose - seems to be a lot more advanced than just the next lesson after lesson 7.
6 Likes
Is there a good way to watch mean/std of layers as your network trains over batches/epochs? I’m guessing probably yes with tensorboard and callbacks? If anyone has any hints/direction on this, would be super helpful.
1 Like
iirc, FastAI’s ActivationStats callback does exactly this.
9 Likes
RNN’s does not commonly use batch norm, so this initialization might just help a lot.
1 Like
Great first lesson 
1 Like
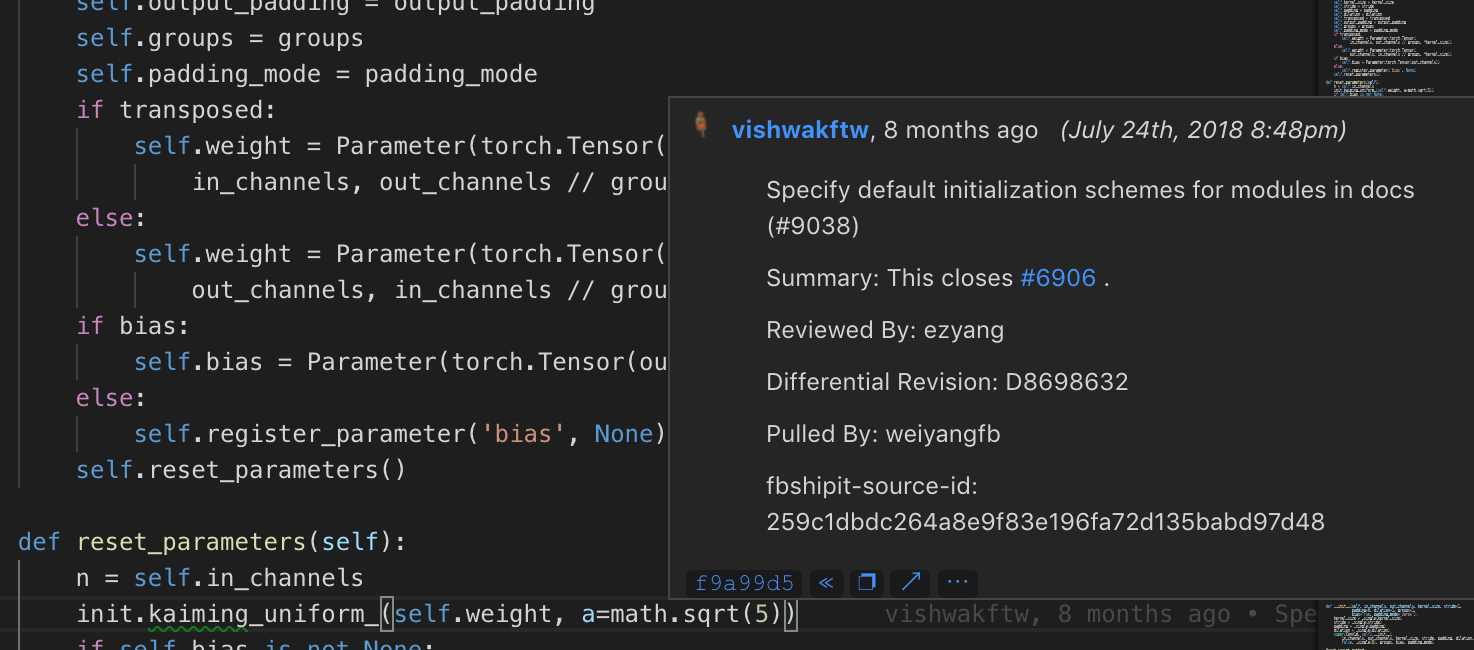
@sgugger, I’m not sure if this was mentioned in the discussion but the bug that Jeremy found in pytorch seems to be a bug introduced during refactoring. The commit that introduced this change was supposed to only add documentation and a bit of refactoring so it wasn’t done knowingly.
Here is the commit for bug #6906:

btw. Could git commit messages work as a way to reference why a change was introduced as Jeremy stated?
It is easy to access them in VSCode:
6 Likes
Really enjoyed this first class, and the direction this 2nd half is going!
Why is the call function defined as a magic method inside the Model class, and not as a regular method ? I think correlates with the forward() in pytorch. Please, correct me if I’m wrong in the usage of some terminologies.
class Model():
def __init__(self, w1, b1, w2, b2):
self.layers = [Lin(w1,b1), Relu(), Lin(w2,b2)]
self.loss = Mse()
def __call__(self, x, targ):
for l in self.layers: x = l(x)
return self.loss(x, targ)
def backward(self):
self.loss.backward()
for l in reversed(self.layers): l.backward()
Looking at the PyTorch.Tensor docs .clone() seems to do something more interesting than just making a copy with .copy().
Appears that the cloned tensor becomes part of the original computation graph in addition to the original, which could be good/bad.
Would .copy() be a safer bet?