I am not sure if that is what is really happening, but this would be my take on this:
As we continue to train our model, it becomes more confident in it’s predictions (for a classification problem, the outputted values grow closer to 0 and 1). Overall, the model is doing a better job at classifying images (accuracy keeps increasing) while the loss grows as well. That is because for the now fewer examples that are misclassified, as the model becomes more confident in its predictions, the loss increases disproportionately.
If we look at how the cost is calculated using cross entropy, the more wrong the model is (difference between predictions and ground truth approaches 1) the cost asymptotically approaches infinity IIRC. So the few misclassified examples count by a lot.
Now, I don’t think this could happen if we were considering all examples in the dataset during training. But as the loss is calculated on a batch of examples, the model can still be learning something useful, becoming better overall, while we see an increase in loss (though here we probably only care about the validation loss so that is a slightly moot point).
EDIT: The image below is showing the effect:
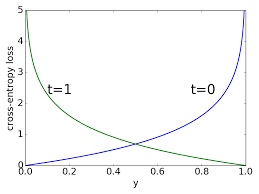
For a positive class, notice how little the cost grows from a predicted probability of 0.6 to 0.4. For as long as the model operates in that middle ground the cost changes slightly. But observe the explosion in cost as the predicted probability approaches 0!
Image taken from these lecture slides returned by google search.