I was curious to have a go at extending the example “RTTT Part 4 multi-target notebook” to include Age. After throwing lots of darts in the dark, I’ve now cleared the runtime errors and am looking for some feedback on what I’ve cobbled together. Here is the notebook.
I added get_age from basic pattern matching, and took a wild guess at using RegressionBlock…
def get_variety(p): return df.loc[p.name, 'variety']
def get_age(p): return df.loc[p.name, 'age']
...
dblock = DataBlock(
blocks=(ImageBlock,CategoryBlock,CategoryBlock, RegressionBlock),
n_inp=1,
get_items=get_image_files,
get_y = [parent_label,get_variety, get_age],
That seemed to work, with show_batch displaying the age…
From basic pattern matching I extended loss and error functions to three parameters. It was a struggle to clear runtime errors until I discovered rmse() in the Regression Metrics to use instead of error(). But I’m not sure if I need to scale age?
I took a guess that only a single addition float output (zero offset element 20).
def disease_err(inp,disease,variety, age): return error_rate(inp[:,:10],disease)
def variety_err(inp,disease,variety, age): return error_rate(inp[:,10:20],variety)
def age_err(inp,disease,variety,age): return rmse(inp[:,20],age)
err_metrics = (disease_err, variety_err, age_err)
The gist here was using F.l1_loss for age regression, so I copied that…
def disease_loss(inp,disease,variety,age): return F.cross_entropy(inp[:,:10],disease)
def variety_loss(inp,disease,variety,age): return F.cross_entropy(inp[:,10:20],variety)
def age_loss(inp,disease,variety,age): return F.l1_loss(inp[:,20],age)
def combine_loss(inp,disease,variety,age): return disease_loss(inp,disease,variety,age) + variety_loss(inp,disease,variety,age) + age_loss(inp,disease,variety,age)
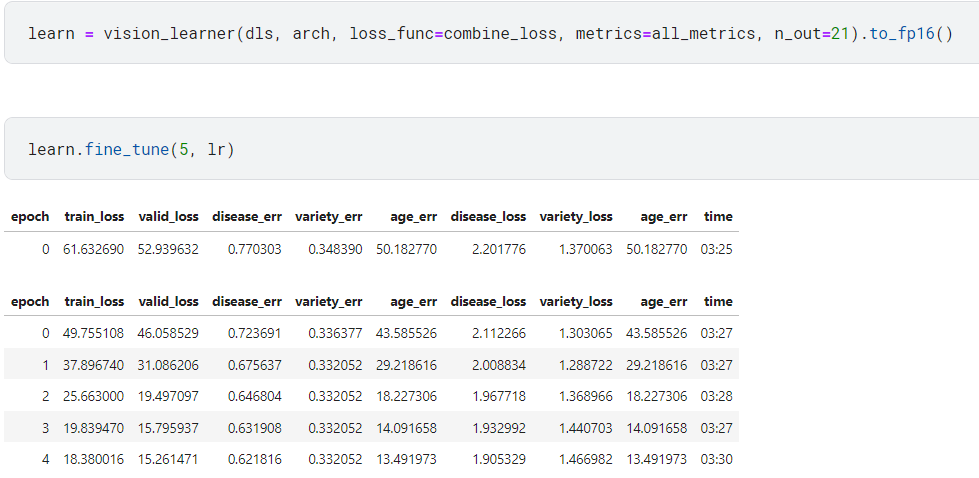
So here is the result…
I notice that while age_err improves a lot, disease_err and variety_err don’t improve much, and certainly much less than without age. So I’m guessing the age_loss is swamping the others and needs to be scaled. Does that scaling need to be done in both loss and error functions? I can’t try this until tomorrow, so hints are welcome to reduce my time experimenting then…