No, you’re not missing anything – fastai can only do it’s auto-magical stuff for loss functions and activation functions it knows about (which doesn’t include custom functions).
1 Like
@jeremy, I was surprised to see very little mention of progressive resizing in this year’s course!
Has that practice fallen from grace?
Would love to hear your thoughts on it, and whether the juice is worth the squeeze.
Thanks a ton for another fantastic course!
1 Like
It’s in the walkthrus
1 Like
When experimenting for an appropriate accum/batchsize, is best practice (or even required), for accum to be a power of two? e.g…
train('swin_large_patch4_window7_224', 224, epochs=1, accum=2, finetune=False)
1 Like
No, but you’d want batchsize divided by accum to be an integer.
1 Like
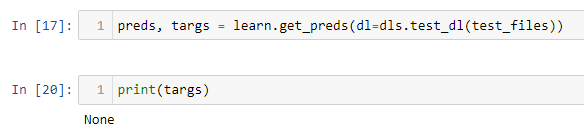
I was stuck a while trying to work out why the following code was erroring with my targs being None
tst_files = get_image_files(workpath/'test_images').sorted()
preds,targs = learn.tta(dl=learn.dls.test_dl(tst_files))
error_rate(preds,targs)
and finally come to the head-slap conclusion that its nonsensical to try to determine an error_rate for the test_images, since they aren’t supplied with categories. Obvious is hindsight, can someone confirm so I can lock the concept in.
3 Likes
Yeah, targs is None
2 Likes
The Multi-target: Road to the Top, Part 4 notebook ends with learn.fine_tune(). A bit more is required to do a submission, but the tensors are a different shape to early parts due to the additional variety elements.
I think I’ve worked it out (the first dozen items of my ‘subm.csv’ match an earlier submission, but I’d like to check I haven’t missed anything, or whether is a better way.
Reviewing the inference result we start with…
tst_files = get_image_files(path/'test_images').sorted()
tst_dl = dls.test_dl(tst_files)
allpreds,_ = learn.get_preds(dl=tst_dl)
allvocab = np.array(learn.dls.vocab)
print(allpreds.shape)
print(allvocab.shape, allvocab,"\n")
gives…
torch.Size([3469, 20])
(2, 10) [[‘bacterial_leaf_blight’ ‘bacterial_leaf_streak’
‘bacterial_panicle_blight’ ‘blast’ ‘brown_spot’ ‘dead_heart’
‘downy_mildew’ ‘hispa’ ‘normal’ ‘tungro’]
[‘ADT45’ ‘AndraPonni’ ‘AtchayaPonni’ ‘IR20’ ‘KarnatakaPonni’ ‘Onthanel’
‘Ponni’ ‘RR’ ‘Surya’ ‘Zonal’]]
Pulling out just the disease part…
preds=allpreds[:,:10]
vocab=allvocab[0]
print(preds.shape)
print(vocab.shape, vocab)
gives…
torch.Size([3469, 10])
(10,) [‘bacterial_leaf_blight’ ‘bacterial_leaf_streak’
‘bacterial_panicle_blight’ ‘blast’ ‘brown_spot’ ‘dead_heart’
‘downy_mildew’ ‘hispa’ ‘normal’ ‘tungro’]
Finally…
idxs = preds.argmax(dim=1)
results = pd.Series(vocab[idxs], name="idxs")
ss = pd.read_csv(path/'sample_submission.csv')
ss['label'] = results
ss.to_csv('subm.csv', index=False)
!head subm.csv
gives…
image_id,label
200001.jpg,hispa
200002.jpg,normal
200003.jpg,blast
200004.jpg,blast
200005.jpg,blast
200006.jpg,brown_spot
200007.jpg,dead_heart
200008.jpg,brown_spot
200009.jpg,hispa
So that seems to work, but one thing I’m not sure on is the meanign of the comma in the preds.shape “(10,)” since there is no second number to separate from the first.
1 Like
Isn’t vocab a rank 1 tensor? Also curious what is the type of vocab. Is it torch tensor or L object? It’s a bit late here, i will go and try to replicate your experiments tomorrow
1 Like
Looks good to me! (10,) is how python prints a tuple with one element (and also how you create one as a literal).
2 Likes
I have an anecdotal feeling that my epochs are actually taking longer than the reported eleapsed-time of 13:31.
Is there a way to add a column showing the “wall clock” when the epoch info is printed?
epoch train_loss valid_loss disease_err variety_err disease_loss variety_loss time
0 1.777488 1.246598 0.252763 0.113888 0.886075 0.360523 03:51
epoch train_loss valid_loss disease_err variety_err disease_loss variety_loss time
0 0.774896 0.366873 0.086977 0.031235 0.265531 0.101342 13:31
1 0.653621 0.377183 0.082172 0.029793 0.265389 0.111794 13:31
2 0.581095 0.389426 0.078808 0.040365 0.270176 0.119250 13:31
3 0.481458 0.384125 0.091302 0.015377 0.336432 0.047693 13:31
1 Like
I guess you could make that a metric…
1 Like
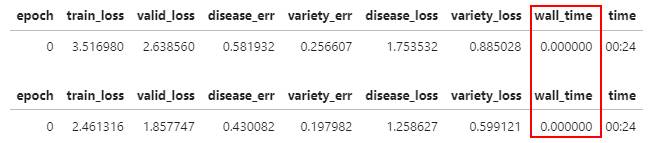
I got as far as outputting constant zero as a test case…
def wall_time(inp,disease,variety): return 0
def disease_err(inp,disease,variety): return error_rate(inp[:,:10],disease)
def variety_err(inp,disease,variety): return error_rate(inp[:,10:],variety)
all_metrics = err_metrics+(disease_loss,variety_loss,wall_time)
learn = vision_learner(dls, arch, loss_func=combine_loss, metrics=all_metrics, n_out=20).to_fp16()
which produces…
but when I try…
def wall_time(inp,disease,variety): return datetime.datetime.now(pytz.timezone('Australia/Perth')).strftime('%H:%M:%S')
I get an error…
TypeError(“Exception occured in
Recorderwhen calling eventafter_batch:\n\tunsupported operand type(s) for +=: ‘float’ and ‘str’”)
which seems to lead from here to notebook 13_callback.core,
and presumably the error occured in method Recorder>>after_batch()
Taking a wild guess, presuming that “mets” = “metrics” and “+=” is invoked from accumulate(), the problematic line is…
for met in mets: met.accumulate(self.learn)
However the text output seems to happen a dozen lines lower…
def after_epoch(self):
"Store and log the loss/metric values"
self.learn.final_record = self.log[1:].copy()
self.values.append(self.learn.final_record)
if self.add_time: self.log.append(format_time(time.time() - self.start_epoch))
self.logger(self.log)
self.iters.append(self.smooth_loss.count)
So perhaps… rather than adding my wall_time() function to metrics, I need to subclass Recorder and replace it in the callbacks?
Maybe something like…
class MyRecorder(Recorder):
def after_epoch(self):
super().after_epoch()
self.log.append(datetime.datetime.now(pytz.timezone('Australia/Perth')).strftime('%H:%M:%S'))
How would I replace the existing Recorder instance in the training loop with MyRecorder?
Or… can I leave out the super call, leave the original Recorder instance alone and add MyRecorder along side it?
1 Like
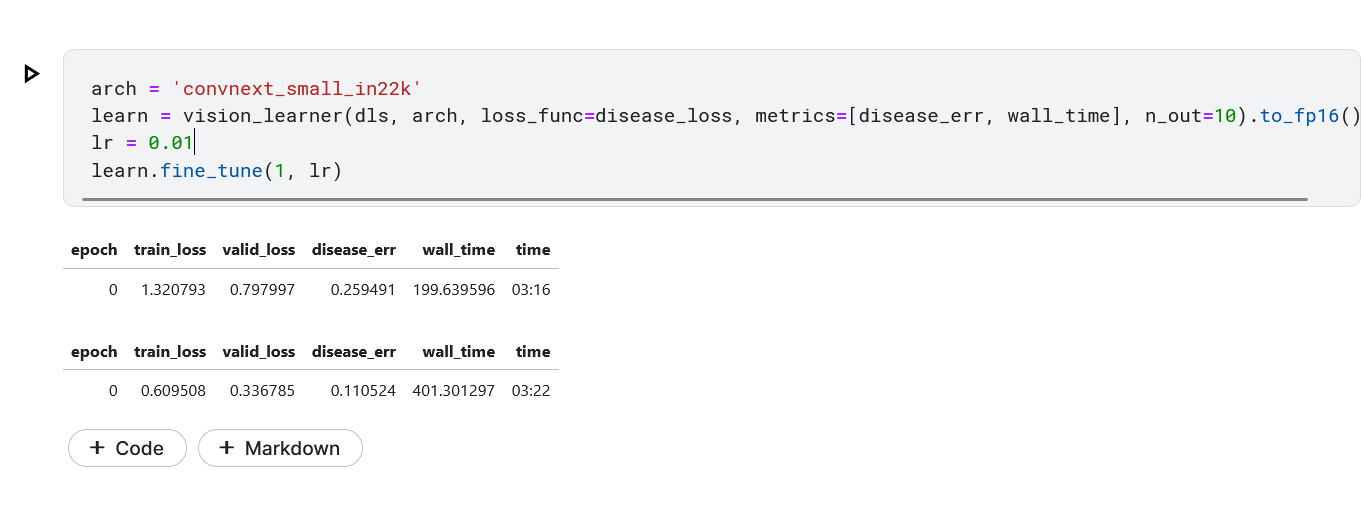
As Jeremy pointed I tried out making a metrics with same stuff. I used the python standard library time to create my wall time function as shown below:
import time
start = time.time()
def wall_time(inp, disease, variety):
t = time.time()
return int(time.time() - start)
On passing this wall time function, to the learner as a metrics. I was able to train it, and it seems to return the wall time correctly.
This kind of works, and the main reason I got it working was realizing passing an integer like 0 works as metrics. It somehow works, which I am really surprised by.
Yet making a minor tweak by removing int from my wall_time function, it throws the error below similar to what @bencoman also got in his experimentation ![]()
TypeError(“Exception occured in
Recorderwhen calling eventafter_batch:\n\tunsupported operand type(s) for +=: ‘float’ and ‘str’”)
@kurianbenoy, partial progress. maybe something for you to play with…
import fastcore, fastai, timm, gc
from fastai.vision.all import *
import datetime, pytz
class MyRecorder(Recorder):
def after_epoch(self):
"Store and log the loss/metric values"
self.learn.final_record = self.log[1:].copy()
self.values.append(self.learn.final_record)
if self.add_time: self.log.append('MY WALL TIME ' + datetime.now(pytz.timezone('Australia/Perth')).strftime('%H:%M:%S'))
self.logger(self.log)
self.iters.append(self.smooth_loss.count)
item=Resize(480, method='squish')
dls = ImageDataLoaders.from_folder(trn_path, valid_pct=0.2, item_tfms=item,
batch_tfms=aug_transforms(size=200, min_scale=0.75), bs=64)
cbs = MyRecorder()
learn = vision_learner(dls, 'resnet18', metrics=error_rate, cbs=cbs).to_fp16()
learn.fine_tune(2, 0.01)
produces…
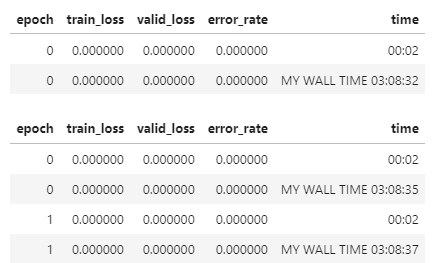
You can see stats doubling up because both Recorder and MyRecorder are registered as callbacks…

My after_epoch() is adapted from here
TODO:
- remove Recorder from callbacks.
- work out how to add a column instead of abusing the “time” column
This seems like it should be done in before_fit(), but I just couldn’t find the right variable to poke.
Unfortunately I’ve not done OO programming in Python before. I’m adapting from the Smalltalk I usually program in.
2 Likes
This is pretty interesting observations. Great to see that you got it by using callbacks in fastai ![]()
Hi, I don’t know what I’m doing wrong, but I cannot replicate the excel results for x-entropy with pythorch.
- Here is what is in the Excel file:
Softmax and cross-entropy
| output | softmax | actuals | x-entropy | |
|---|---|---|---|---|
| cat | -4.885225 | 0.000491 | 0 | 0.0 |
| dog | 2.597473 | 0.873139 | 1 | -0.0589164124 |
| plane | 0.591665 | 0.117482 | 0 | 0.0 |
| fish | -2.068945 | 0.008213 | 0 | 0.0 |
| building | -4.568679 | 0.000674 | 0 | 0.0 |
| 0.0589164124 |
- In pythorch I’m doing this:
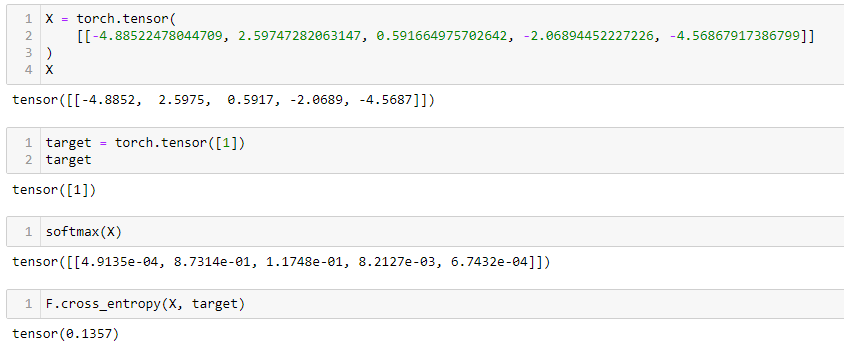
X = torch.tensor([[-4.88522478044709, 2.59747282063147, 0.591664975702642, -2.06894452227226, -4.56867917386799]])
target = torch.tensor([1])
F.cross_entropy(X, target)
| x-entropy | ||||
|---|---|---|---|---|
| 0.1356599777937 |
PyTorch docs say that its cross_entropy is “equivalent to the combination of LogSoftmax and NLLLoss”. It might be worth checking those intermediate steps.
Thank you Jeremy.
I found that the difference was that log in pythorch/python is equivalent to LN in Excel/Sheets.
So switching the formula to LN would return same results.
| exp(xi) | Softmax(xi) | LogSoftmax(xi) |
|---|---|---|
| =EXP(B2) | =C2/sum($C$2:$C$6) | =LN(D2/sum($D$2:$D$6)) |
| xi (logit) | exp(xi) | Softmax(xi) | LogSoftmax(xi) | target | x-entropy | |
|---|---|---|---|---|---|---|
| cat | -4.885225 | 0.007557 | 0.000491 | -7.618358 | 0 | 0 |
| dog | 2.597473 | 13.429756 | 0.873139 | -0.135660 | 1 | -0.13566 |
| plane | 0.591665 | 1.806995 | 0.117482 | -2.141468 | 0 | 0 |
| fish | -2.068945 | 0.126319 | 0.008213 | -4.802077 | 0 | 0 |
| building | -4.568679 | 0.010372 | 0.000674 | -7.301812 | 0 | 0 |
| 0.1356600528 |
3 Likes
Does anyone have an example of multi-target using TabularDataLoaders? Given that y_names (plural) is an option I thought it might “just work” but I get an error using fit_one_cycle() when I have two targets. If anyone could point me towards an example that would be great.
Expected input batch_size (64) to match target batch_size (128)
from fastai.tabular.all import *
# https://docs.fast.ai/data.block.html#categoryblock
y_block = CategoryBlock
# https://docs.fast.ai/tabular.data.html
# By default the factory method uses a random 80/20 split
# By default the batch size is 64
dls = TabularDataLoaders.from_df(
df = df,
path = working_path,
procs = [Categorify, FillMissing],
cat_names = [],
cont_names = ['CONT1','CONT2','CONT3'],
y_names = ['TARG1','TARG2'],
y_block = y_block,
valid_idx = valid_idx,
bs = 64
)
dls.show_batch()
1 Like