Yup. All installed.
Yes, with
from fastcore.utils import *
It’s in the utils from fastbook.utils, not fastcore ![]()
How to save a model for further training later on?
I am halfway with Lesson 7 but I could not found yet an example of how to save a model that I am halfway training. I would like to be able to then load it to continue the process.
This is what I tried:
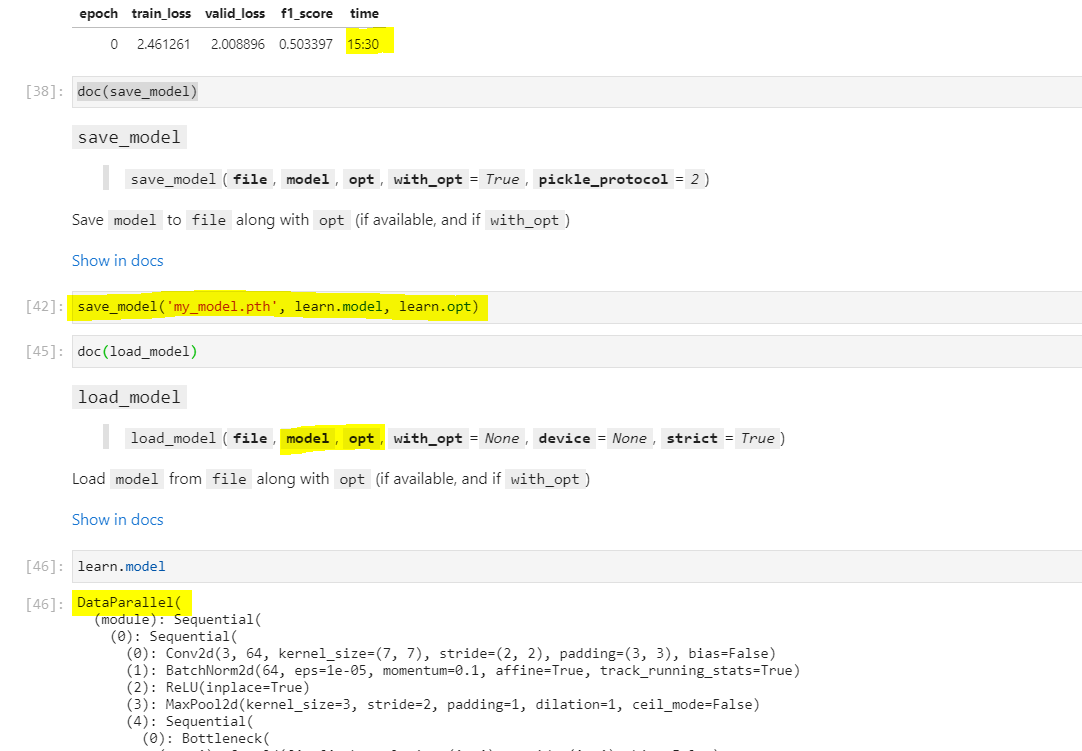
I am however not sure of how the filename should look like when saving or what parameters is load_model expecting (i.e. if in a new session I am loading the model I do no longer have the learner or the optimizer… )
Could somebody help me out with an example? Thanks a lot 
Thanks, Zachary. So I did this:
# install the utils.py from fastbook
%cd '/content/drive/My Drive/fastbook/'
pip install utils
%cd ..
But I still get the NameErrors for those two lines 
You don’t install, simply import  (as it’s just a .py file you already have in the system!)
(as it’s just a .py file you already have in the system!)
Does anyone got this result when using the weight decay or is it only my luck? it got worst, can I change the wd to lower than 0.1? or would this would cause bias in the data?
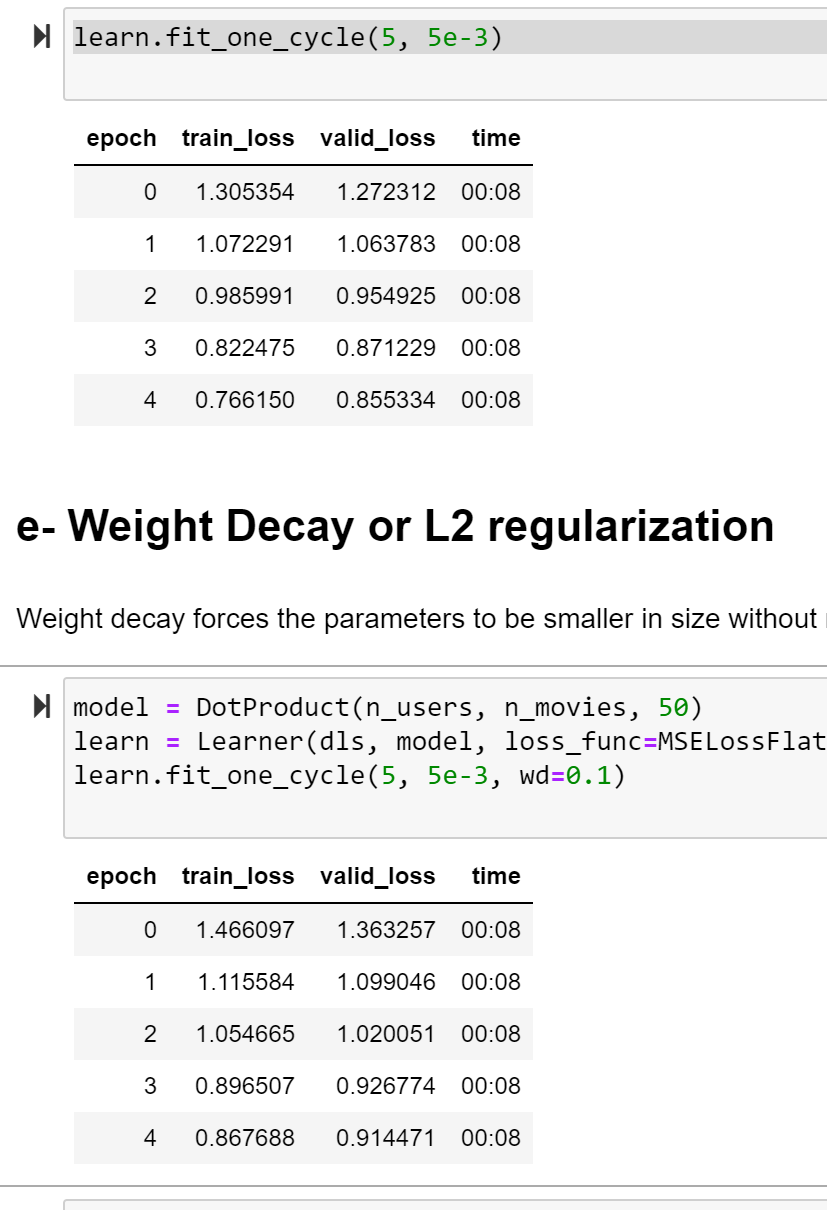
Thanks @muellerzr Zachary,
so this time:
# install the utils.py from fastbook
%cd '/content/drive/My Drive/fastbook/'
import utils
%cd ..
But no cigar – same errors.
from utils import *
3 Likes
Third time’s the charm! Thanks for your patience, Zachary! 
1 Like
My pleasure ![]() glad we got it working!
glad we got it working!
1 Like
Hi @mgloria – which notebook are you in?
This is my own code. I am trying to train a model that takes a while (>15 min/epoch) and I would like to know who to save it for later further training. I could not find an example in the notebooks for save_model and load_model.
Do you @muellerzr maybe know?
Hi @SMEissa! If we focus on the second case (wd=0.1), by epoch 5 both your training and validation losses are still getting better… so try training a bit longer until your training loss keeps getting better but your validation loss starts getting worst. This is the time to stop.
Weight decay has a regularization effect that prevents from ovefitting (which is a good thing), but it means also that it can take longer for your model to learn. That’s why in your second case more than 5 epochs may be required.
I think you have it right. You can choose any file name you want for the model. But then when you use load_model you have to pass it the filename. So in your example, you can retrieve the saved model with
my_model_objects = load_model('my_model.pth')
then you can check if you got everything you saved with
dir(my_model_objects)
You should see the model and the optimizer that you saved.
1 Like
You could also utilize the SaveModelCallback, which has a parameter for a filename that it will save it to (I believe you can also have it simply save every iteration). Then do a learn.load (or load_model) to bring it back in ![]()
2 Likes
Thanks a lot for the clarification!
In the video, and also in the relevant fastbook notebook here, for weight decay it says that:
loss_with_wd = loss + wd * (parameters**2).sum()
which, in derivative, is equivalent to (note: ‘parameters’ above has been swapped for ‘weight’ below):
weight.grad += wd * 2 * weight
Shouldn’t it be loss.grad instead? i.e. (I’ll use the original naming of ‘parameters’ here):
loss.grad += wd * 2 * parameters
Or have I misunderstood something…?
Thanks.
Yijin
Great question, Yijin! In principle you are correct. But PyTorch uses a slick notation trick:
weight.grad implictly calculates the derivative of the loss function with respect to weight.
2 Likes
Ah right. Thanks for your clarification : )
Yijin