Yes, it’s an active area of research.
5 Likes
We covered this a couple of times in earlier lessons, so be sure to go back and re-watch the material on transfer learning and layer-freezing.
In short: freeze freezes all layers except for the randomly initialized new layers. The randomly initialized new layers need a lot more training than the pre-trained layers. So this approach lets us train them more. This is faster, and (most importantly) avoids overfitting by training most parameters for fewer epochs.
3 Likes
In part 2 we’ll cover object detection - finding the bounding box of each object in an image. The best models here use feature pyramid networks - which are nearly identical to unets.
1 Like
Just a note - quite a bit of that may be out of date, now that we’re doing things so differently.
2 Likes
AFAIK there’s never any benefit to using more than one batch to calculate stats.
1 Like
Apologies @simonw I suspect I did a poor job of setting the context here.
What we’re doing here is the exact same thing as the language model pre-training we saw in lesson 3 (IMDB sentiment classification). So the purpose of this section of the course today is to show how that language model was created “behind the scenes”. Since you have already trained a much more interesting language model in lesson 3, we switched to a much more simple toy dataset for today’s deep dive, so that you can better understand exactly what is going on.
Does that make sense?
2 Likes
This one.
1 Like
That would be awesome - perhaps you could start such a thread collecting the ones you like best?
1 Like
To know where something comes from, just type its name in a cell and hit shift-enter. You will see where it comes from.
However this won’t help you productionize a model - where the symbol is imported from doesn’t tell you which parts of the library are being used to implement that in the library (this is true of all libraries, not just fastai). Instead, see the pic at the bottom of http://docs.fast.ai, copied here for your convenience, to see what modules you’re using:
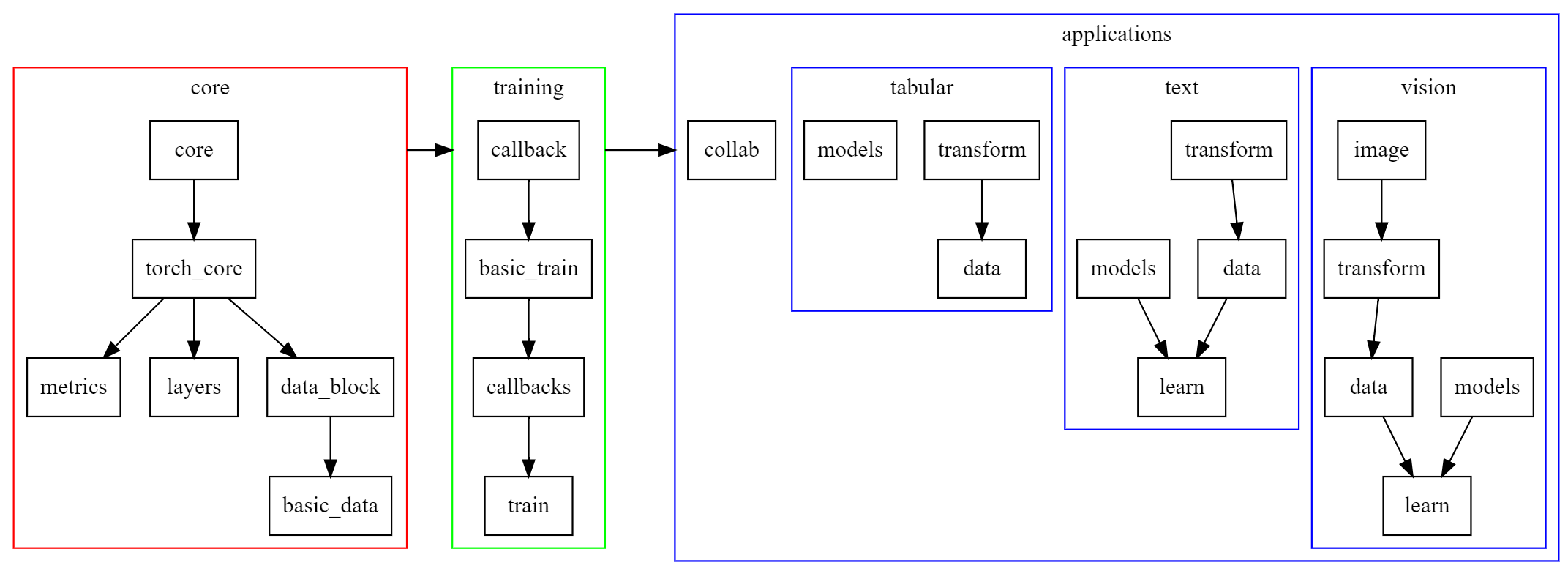
7 Likes
Whether a pixel with the value 1 should be considered black, or 0 should be considered black, depends on what color map (cmap) you use - it’s not defined by the image.
Maybe a stupid question, why Res block is only used with conv layer but not other layer like fully connected layer?
Check out: GitHub - fastai/fastai: The fastai deep learning library
You need to basically re-install fast.ai each time, don’t do the conda update anymore in fastai version 1.x.
Edit: Am I reading this wrong, can we still do the conda instead of the --upgrade flag mechanism?
In order to update your environment, simply install
fastaiin exactly the same way you did the initial installation.Top level files
environment.ymlandenvironment-cpu.ymlbelong to the old fastai (0.7).conda env updateis no longer the way to update yourfastai-1.xenvironment. These files remain because the fastai course-v2 video instructions rely on this setup. Eventually, once fastai course-v3 p1 and p2 will be completed, they will probably be moved to where they belong - underold/.
Is there already an implementation of a feature pyramid network in fastai ? I was looking to try to implement one myself using fastai but if there’s already one I can focus elsewhere
1 Like
GANs are possible only with continuous data. NLP embeddings are discrete data values.
I don’t see why either of those sentences are true. Are you sure?
2 Likes
I was about to say the same…
Um, perhaps I have worded it wrong? I did some reading before stating as continuous vs discrete values.
Link: https://www.reddit.com/r/MachineLearning/comments/40ldq6/generative_adversarial_networks_for_text/?utm_source=reddit-android
Um, please let me know your thoughts.
Re: The generative models to repair photos using U-net.
- Is it possible to use this approach to do image straightening, lens correction etc.?
- How does one handle larger image size?
To be used in production in publishing, I suspect it will need to be able to do much larger photos (i.e. 3872 x 2592 etc) Training U-Net that encodes and then decodes from these kind of sizes is going to be very memory intensive.
What is the best way to approach this challenge. Does one segment the photo up into blocks? Parse in smaller batches (i.e. one or 2 photos at a time)
Wat is the best order: Batchnorm before or after Relu?
In the lesson 7-resnet-mnist notebook in the “Basic CNN with batchnorm” section, the order is: Conv2d-Batchnorm2D-RelU.
In the “Refactor” section, using conv_layer, the order is: Conv2D- ReLU-Batchnorn2D.
Which of the two is best practice?
4 Likes
Hello Benudek, same issue here. Steps below solved my issue.
- conda install pytorch torchvision -c pytorch
- conda install -c fastai fastai
5 Likes