Thank you fastai team! It really inspires me to do better time management, learn DL well, and be able to teach others as well. Let me see how far I get…
3 Likes
Here’s something to keep you happy: https://www.youtube.com/watch?v=v16uzPYho4g. That was just yesterday. Got most of the way through- really liking it- haven’t heard him talk about a lot of this stuff that he’s covering here.
11 Likes
Many many many thanks to Jeremy, Rachel, Sylvain and all the others for this course. I and so many others have learned so much it’s incredible. This course is fantastic and very thoughtfully made. Thank you for all the effort and time you all put into it, I’m very grateful.
15 Likes
Thank you Jeremy, Rachel and Fastai team for this wonderful course.
5 Likes
Thanks Jeremy, Rachel and the team! Have you considered moving to Melbourne :)
1 Like
If life is a Unet, they have no choice but to go back to Melbourne! But a better one this time!
2 Likes
Well done, Jeremy, Rachel, Sylvain and everyone in the forums. Very much indebted to all of you and deeply inspired to keep learning and building.
7 Likes
Thank you! It has been an amazing time taking these live lessons. The fastai team, the course, the forums, the work shared… so inspiring.
2 Likes
Fingers crossed! Or maybe crossed Unet? hmm…
1 Like
In the process of explaining my question more clearly, i think i was to able to understand more and answer myself. Please confirm if my understanding is correct
Lets say we chose n dimensions to represent each word we have in the corpus and assume one of dimensions is capturing sentiment. So for words expressing sentiment, this particular dimension will be more activated (e.g. ‘celebrating’- positive, so the sentiment dimension will be more activated). Similarly assuming a dimension for ‘fun’, this will be more activated as well for ‘celebrating’ word.
Next comes the weight matrix of hidden layer. Now this weight matrix will be tuned to further combine the activations of ‘celebrating’ word(one of them representing ‘sentiment’ dimension along with other things like ‘fun’) and make a complex feature(like probably ‘partying’). So having the same weight matrix for all words means we can extract one feature from every word for each RNN node.
But we can have many RNN nodes in the hidden layer, where each node learns one meaningful feature from the activations of word embeddings. So having same weight matrix helps to extract a specific feature is present in that each word
1 Like
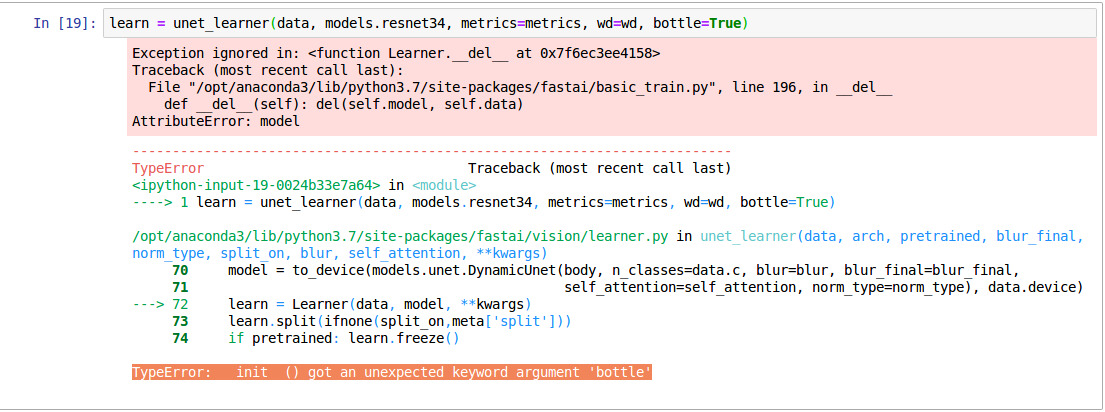
I am getting this error in new camvid notebook.
TypeError: init() got an unexpected keyword argument ‘bottle’
I think new changes are not merged to latest fastai library
The new changes don’t seem to be deployed to conda yet, but are available if you install the development version from source. I’m sure they’ll be out soon.
1 Like
anyone has issues importing the gan lib ?
ModuleNotFoundError: No module named ‘fastai.vision.gan’
1 Like
thanks so much for that class !!!
1 Like
We always deploy the latest before the class - including this one. If you aren’t able to access some feature, then it means that your fastai upgrade didn’t catch the latest for some reason. See earlier replies for how to force it to grab a particular version.
1 Like
It’s doing the same thing mathematically, just in a different way. The benefit of SequentialEx is that you can turn any sequence of modules you like in to a resblock or denseblock. So you can design your own res/denseblock variants (e.g. with different nonlinearities, normalization, conv types, etc). But it is still just as easy as defining a sequential model.
4 Likes
Please use the further discussion thread in the advanced forum to ask questions about topics beyond what was in the lesson.
2 Likes
Cross connection is one kind for skip connection. Another kind of skip connection is a resnet identity connection.
1 Like
It gets concatenated on dim=1 of the tensor - i.e. concatenated on the channels dimension.
2 Likes