In the superres-gan notebook dealing with the Oxford Pets dataset, while creating the unet learner, we pass (-3.,3.) to the attribute y_range. I understand that in this case we have 3 output activations for 3 input channels (R,G,B). Can anyone clarify why we are doing this?
I do remember that in the collaborative filtering lesson, we passed a y_range of (0, 5.5) for the 5 different classes in order to scale our activations and make better predictions. I am wondering if there is a similar intuition here.
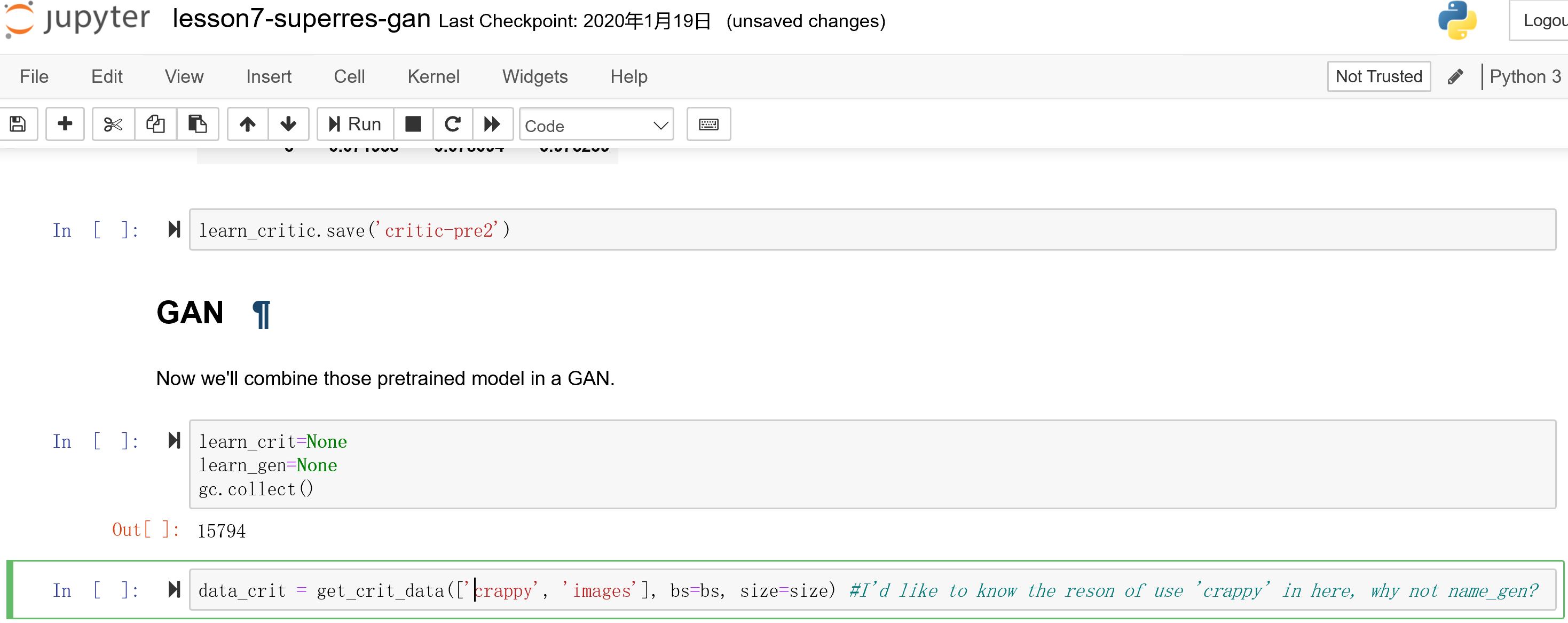
In the superres-gan notebook, I’d like to know the reason of use ‘crappy’ in here, why not name_gen?
I think it’s wrong: data_crit = get_crit_data([‘crappy’, ‘images’], bs=bs, size=size)
Is it right? :data_crit = get_crit_data([name_gen, ‘images’], bs=bs, size=size)
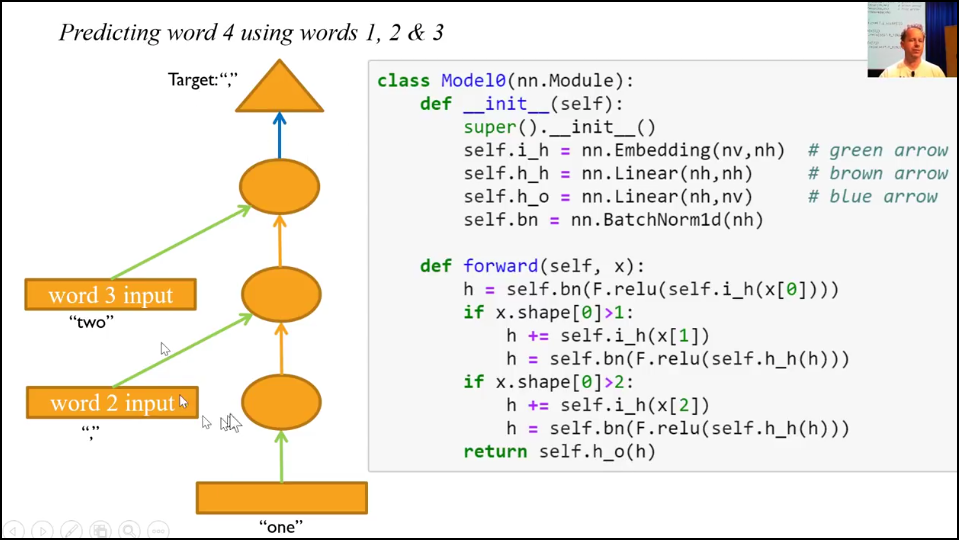
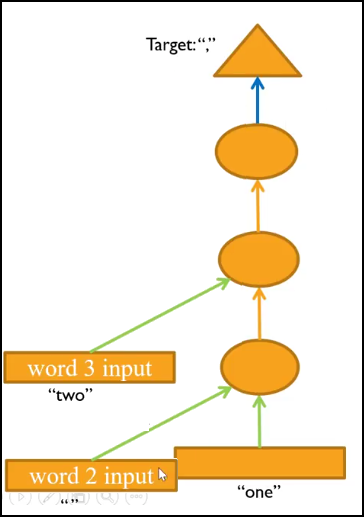
x[0] only passes through h_h after being added to the other input, not before.
Just changing the order of these 2 lines (idem on the next block) would make the picture correct (in my naive understanding)
h = h + self.i_h(x[:,1])
h = self.bn(F.relu(self.h_h(h)))
Or else I don’t really understand it.
…
I guess I will answer myself.
The code on the notebook I have is different.
def forward(self, x):
h = self.bn(F.relu(self.h_h(self.i_h(x[:,0]))))
if x.shape[1]>1:
h = h + self.i_h(x[:,1])
h = self.bn(F.relu(self.h_h(h)))
if x.shape[1]>2:
h = h + self.i_h(x[:,2])
h = self.bn(F.relu(self.h_h(h)))
return self.h_o(h)
And this and the loop version match with the picture.
Hey, I’m asking myself the same question. I changed the y_range value to -1,1 and it increased the train loss dramatically (from .05 to .2).
I removed the y_range parameter altogether and got the same results as with -3,3. I’m gonna settle for the usual “it empirically works better like this” but I’m wondering if there are any comments to be added on that.