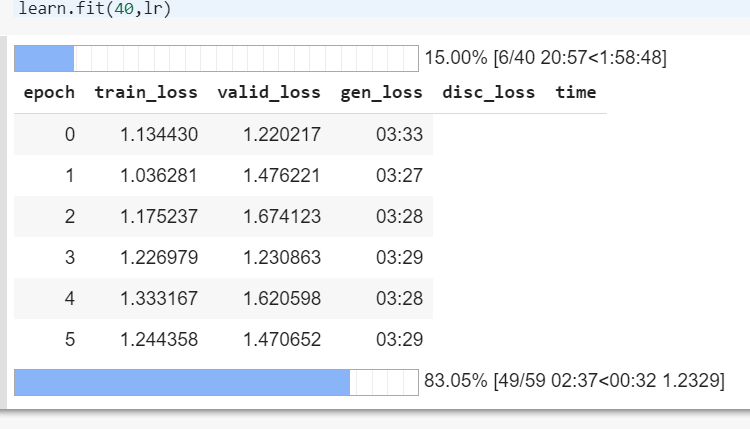
In the “superres-gan” example, I am unable to train the discriminator/generator pair using learn.fit(40,lr). The pretraining of both networks worked fine, but when I try to fit the pretrained model I get a nonspecific error. I’ve copied the full stack-trace below.
AttributeError Traceback (most recent call last)
<ipython-input-27-d44c81445766> in <module>
----> 1 learn.fit(40,lr)
/opt/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in fit(self, epochs, lr, wd, callbacks)
188 if defaults.extra_callbacks is not None: callbacks += defaults.extra_callbacks
189 fit(epochs, self.model, self.loss_func, opt=self.opt, data=self.data, metrics=self.metrics,
--> 190 callbacks=self.callbacks+callbacks)
191
192 def create_opt(self, lr:Floats, wd:Floats=0.)->None:
/opt/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in fit(epochs, model, loss_func, opt, data, callbacks, metrics)
90 cb_handler.on_epoch_begin()
91 for xb,yb in progress_bar(data.train_dl, parent=pbar):
---> 92 xb, yb = cb_handler.on_batch_begin(xb, yb)
93 loss = loss_batch(model, xb, yb, loss_func, opt, cb_handler)
94 if cb_handler.on_batch_end(loss): break
/opt/anaconda3/lib/python3.7/site-packages/fastai/callback.py in on_batch_begin(self, xb, yb, train)
253 self.state_dict['train'],self.state_dict['stop_epoch'] = train,False
254 self.state_dict['skip_step'],self.state_dict['skip_zero'] = False,False
--> 255 self('batch_begin', mets = not self.state_dict['train'])
256 return self.state_dict['last_input'], self.state_dict['last_target']
257
/opt/anaconda3/lib/python3.7/site-packages/fastai/callback.py in __call__(self, cb_name, call_mets, **kwargs)
224 if call_mets:
225 for met in self.metrics: self._call_and_update(met, cb_name, **kwargs)
--> 226 for cb in self.callbacks: self._call_and_update(cb, cb_name, **kwargs)
227
228 def set_dl(self, dl:DataLoader):
/opt/anaconda3/lib/python3.7/site-packages/fastai/callback.py in _call_and_update(self, cb, cb_name, **kwargs)
215 "Call `cb_name` on `cb` and update the inner state."
216 new = ifnone(getattr(cb, f'on_{cb_name}')(**self.state_dict, **kwargs), dict())
--> 217 for k,v in new.items():
218 if k not in self.state_dict:
219 raise Exception(f"{k} isn't a valid key in the state of the callbacks.")
AttributeError: 'tuple' object has no attribute 'items'

 Also your answer was very clear. Thank you
Also your answer was very clear. Thank you  Thanks also for the advice, good luck too!
Thanks also for the advice, good luck too!