Please ask any questions that are not immediately relevant to today’s discussion here, such as extensions beyond the lesson, or diversions outside the lesson.
Hi,
How long Part 1v3 forum and messages will be active and available? As in my case I wasn’t able to go through all interesting topics yet?
Thank you 
3 Likes
Sorry if this question is a bit offtopic but I think it is worth to ask it one more time.
Recently I had a quite rough time while trying to tackle a Kaggle dataset from Quick Draw Doodle competition. I am still not sure if the problem was related to PyTorch or Python multiprocessing itself.
How do you guys usually tackle problems like this? Like, at the end of the day, even with Deep Learning we still have memory leaks, overflows, multiprocessing, i.e., this “mundane” stuff of programming world. How do you usually organize your workflow? I feel like using PyTorch/fastai and standard Python library not enough to get scalable and robust machine learning pipeline. Though probably it is just my impression.
Would be happy to hear any advice from seasoned Kaggle competitors and experienced Data Scientists!
1 Like
I feel like there is some way to tie Hidden Markov Models to RNNs but am not sure how…any ideas?
We don’t remove forums or messages at all.
1 Like
That Quick Draw competition had a particularly large dataset. I nearly never have to deal with something so big in practice. So this doesn’t come up much. When it does, it’s difficult, because Python is not a good language for dealing with really large datasets in parallel. There’s nothing that fastai or pytorch can do really to fix this - instead you need to use other tools for your data management (such as redis) and let python/pytorch/fastai focus on the computation part of the problem, not the data access part.
We’ll probably spend some time on this in part 2, BTW.
10 Likes
Datablock API questinon …
Is there a recommended approach to using a merging different ItemLists into a single ItemList?
For example, I have a raw dataset that includes both tabular and text data from which I want to create a single ItemList that uses both the tabular processing goodness for handling categorical and continuous variables as well as the text classification goodness that handles tokenization, numericalization, vocab building, etc… for the text bits … and then for shuffling/sorting tell it to use the strategy implemented in the TextClasDataBunch.create().
2 Likes
You should probably define your custom ItemList for that (see the corresponding tutorial).
2 Likes
Hi,
Sorry if this is not the right forum for this question, but I’m somehow getting weird predictions with the GAN Learner when running the lesson7-superres-gan.ipynb notebook. I haven’t changed anything from the original code.
Before getting into the building the GAN Learner section, everything seems to work as expected. But when training the GAN Learner these are the results:
data_crit = get_crit_data(['crappy', 'images'], bs=bs, size=size)
learn_crit = create_critic_learner(data_crit, metrics=None).load('critic-pre2')
learn_gen = create_gen_learner().load('gen-pre2')
switcher = partial(AdaptiveGANSwitcher, critic_thresh=0.65)
learn = GANLearner.from_learners(learn_gen, learn_crit, weights_gen=(1.,50.), show_img=True, switcher=switcher,
opt_func=partial(optim.Adam, betas=(0.,0.99)), wd=wd)
learn.callback_fns.append(partial(GANDiscriminativeLR, mult_lr=5.))
lr = 1e-4
learn.fit(40,lr)
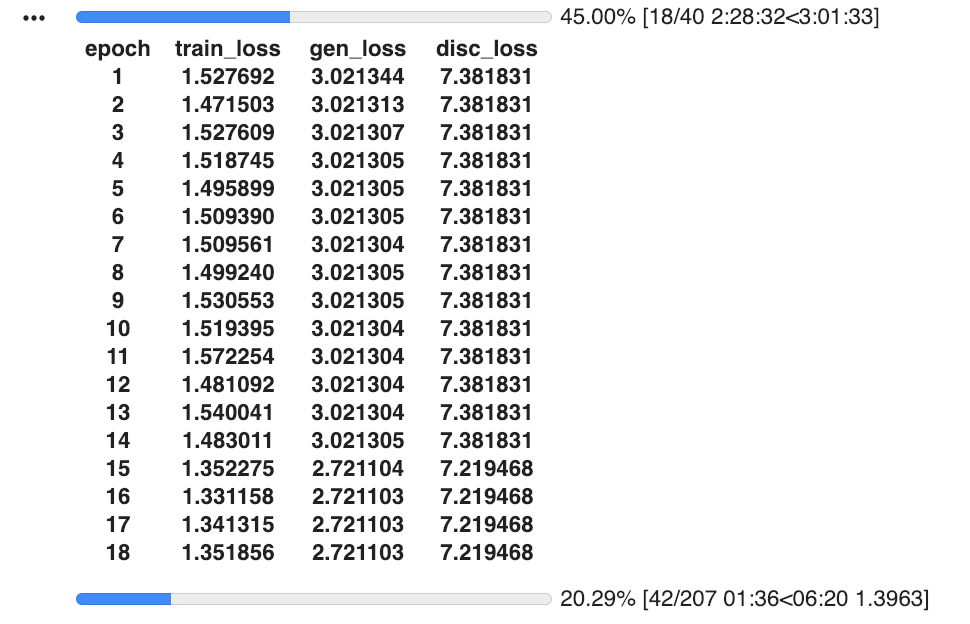
While train loss is declining, both generator and discriminator losses have not changed for a few epochs. On the 15th epoch it drops for both gen and disc. Then again on the 19th. Coincidentally, the predicted image printed is a different animal (see below the results)
Any thought on why is this happening?


That would be great! This information would be really helpful for anyone who tries to train on the datasets that cannot fit into memory or require distributed computations. It seems to be a not too straightforward topic and rarely covered in tutorials.
3 Likes
Hi @jeremy, I noticed that in the lessons, you’re using ReLU + Batch Normalization. It’s my understanding that the authors of ELU and SELU (https://arxiv.org/abs/1706.02515 ) have shown that these activations accomplish the work of Batch Norm, but without its slow performance. My own experiments with image classification have agreed with this, i.e. that (in my case) one can replace a lot of the ReLU+BN blocks in a model with ELUs and get comparable results only in much less (wall clock) time.
My question: Given that you often try to teach “the latest”/“cutting edge” methods: Why are you using ReLU+BN? Is it that you haven’t seen similar results, or is it that since the models you were teaching on use this construction, you were teaching that, or… some other reason?
Thanks!
GREAT course btw. Excellent instruction. I’m very thankful to have been given the opportunity to participate.
Here is a thread on Self-Normalizing Neural Networks but unfortunately the results seem not so applicable. Did you played around with it and got interesting results?
1 Like
Yea, similar to that thread, I did not find swapping ReLU+BN for SeLU to work for me – perhaps there are other aspects of SNN that I failed to implement.
But swapping ReLU+BN --> ELU… Actually, I should revisit those tests and report back. It’s been a couple years since I made that switch.
I can definitely assert that doing BN before ELU makes no significant change in accuracy compared to ELU alone (without BN at all), and furthermore that using ELU alone does work really well and works really fast… but these are not remotely the same thing as my earlier claim that “ELU works as well as doing BN after ReLU”!
(And anyway, as discussed in this Reddit thread, one should do BN after activation, not before).
I’ll re-do some tests and edit this post later.
EDIT: These experiments were done using Keras, not Fast.AI or PyTorch. I suspect that Francois Chollet or someone else has tweaked the Keras BN in the past year or so, because I remember it used to be “slow”. Anyway, my experiments today do confirm that ELU alone works “just as well” (in multiple senses: in the sense of accuracy & loss on the validation set, in the same number of epochs, with essentially indistinguishable ROC curves) as ReLU+BN, but also that the two approaches (now) take essentially the same execution time. (The ELU-only version is maybe 0.5% faster if that’s significant.)
As an additional bit of trivia, at least for my code (https://github.com/drscotthawley/panotti/blob/master/panotti/models.py), it’s better to keep the first block to be BN before ReLU, regardless of what one does with the other layers.
So, I retract my earlier claim: ReLU+BN has not been shown to have been superseded.
.
One more update: Actually, in some newer audio autoencoder experiments I’m doing using PyTorch, ELU seems to be faster and nearly as accurate (lower loss in Training & Validation sets) as ReLU+BN, but the latter has slightly lower loss.
1 Like
SELU is super-fiddly. Everything has to be “just so” to ensure it’s prerequisites are met. I tried to do that for a while when it came out, but in the end the complexity just wasn’t worth it, for me.
However, recent advances in understanding of normalization are leading to other directions that may have the benefits of batchnorm without the downsides. We’ll look at them in some detail in part 2.
3 Likes
In the lecture and resnet-mnist notebook, Jeremy’s basic CNN example uses Conv2D, BatchNorm, ReLU sequences. Then the refactor uses fastai’s conv_layer, which wraps a Conv2D, ReLU, BatchNorm sequence.
Is the order of the ReLU and BatchNorm operations not consequential?
I would have thought the composition of the sequence matters, especially the location of the ReLU. Further, I’d have thought that BatchNorm on the raw Conv2D weights rather than on the ReLU-truncated weights would make more sense, in accordance with the basic CNN example, rather than with the conv_layer function.
2 Likes
It is somewhat consequential - experiments show that BatchNorm after ReLU is generally a bit better.
4 Likes
When implementing the unet paper, I noticed that in the case of the example in the paper, the features from the encoder are 64x64 and the upsampled features are 56x56.
My question is how do concatenate them, do you pad the upsampled features to 64x64 or do you crop the features from the encoder to 56x56.
You crop the features from the encoder. Quoting the paper:
Every step in the expansive path consists of an upsampling of the
feature map followed by a 2x2 convolution (“up-convolution”) that halves the
number of feature channels, a concatenation with the correspondingly cropped
feature map from the contracting path, and two 3x3 convolutions, each followed by a ReLU. The cropping is necessary due to the loss of border pixels in
every convolution.
The ‘contracting path’ is the encoder which ‘contracts’/‘encodes’ the input into a representation of smaller dimensions.
4 Likes
thanks
1 Like