So my logic is that since the Test set ranges from:
(Timestamp(‘2015-08-01 00:00:00’), Timestamp(‘2015-09-17 00:00:00’))
We would want the val set to reflect a similar time period. So in this case the test set is about a month and a half in length, beginning at a month start and ending just after mid month(therefore possibly including a 15th of the month payday spike).
So I see a couple options for the validation set.
- You could match the specific days of the month reflected in the test set, so in this case 2015-06-01 to 2015-07-17. The problem with this is you throw away the data from 2015-07-17 until 2015-08-01.
- You could just match the length of time included in the test set and count back from the beginning of the test set. So, in this case, the test set lasts 48 days. So counting back 48 days from the beginning of the test set gives 2015-06-14.
Unfortunately, I remain confused about the selection of 2015-06-19 but also the syntax being used to create the indexes.
After considering my notes above, it seems like instead of matching days of the month or number of days in the test set, a third option is being used that instead matches the number of observations in the test set to the number of observations in the val set.
I guess the thing that confuses me is that len(test_df) = 41,088. So, assuming the DataFrame is sorted in descending order of date, the line:
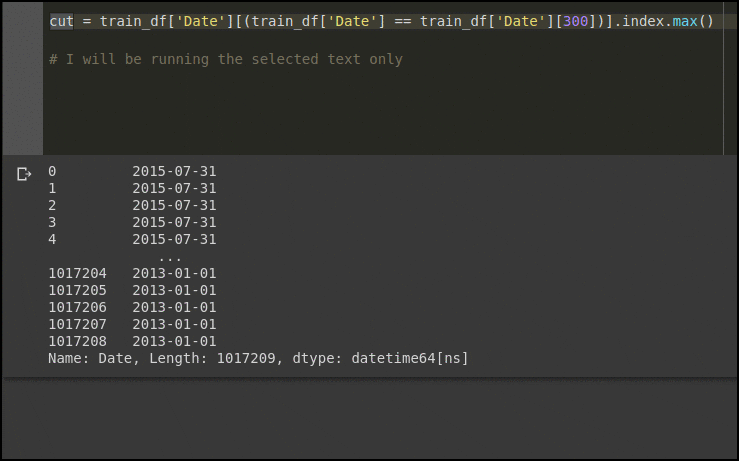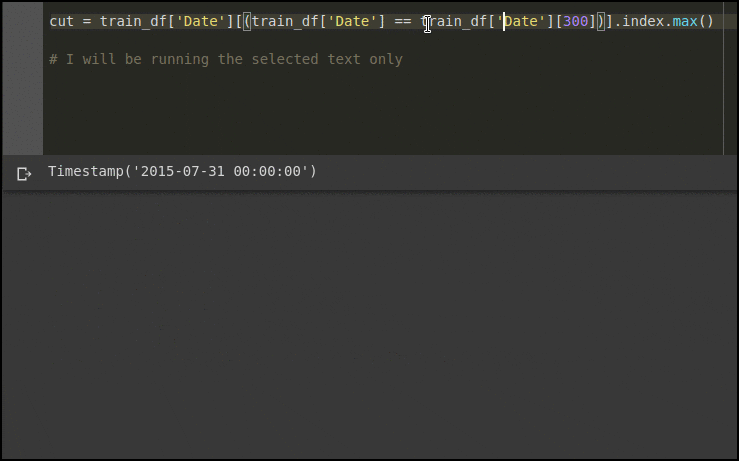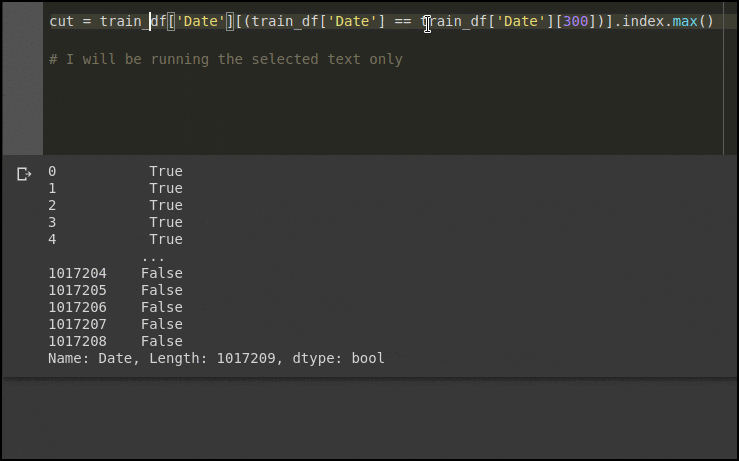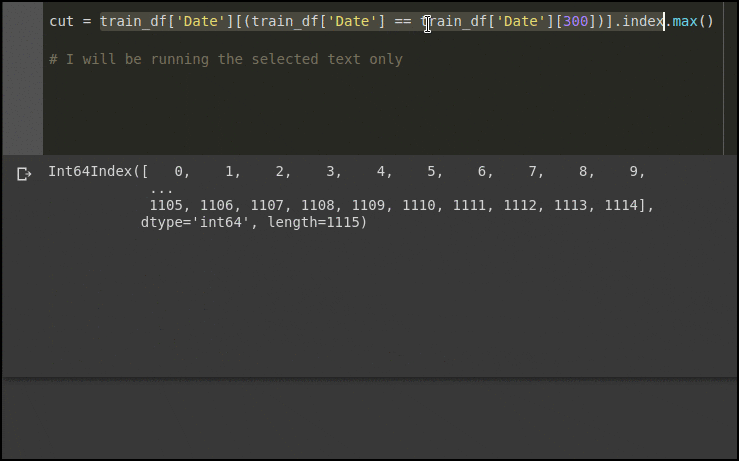
train_df['Date'][len(test_df)] returns: Timestamp(‘2015-06-19 00:00:00’)
is saying since the test_df has 41,088 observations, count back 41,088 observations from the end of the train_df and give me whatever date pops up. That date is then used for the boolean mask on the original train_df[‘Date’] series. Therefore, this segment:
train_df['Date'][(train_df['Date'] == train_df['Date'][len(test_df)])]
Ultimately just gives a series of dates from train_df that equal 2015-06-19.
Finally, the .index().max() just grabs the indexes of that filtered series and then the largest index which I assume reflects the last index in the train_df before the date switches to 2015-06-18 and is index 41,395.
This results in 41,396 observations in the validation set compared with 41,088 observations in the test set.
So at this point I think I understand what the code is doing, but I’m still a little confused on the logic. It may just be a quick and dirty way to get a validation set and I’m over thinking it, but since the desire appeared to be to match the number of observations from the test set to the validation set, this doesn’t seem to be what ended up happening, although obviously, it was very close. Am I missing something or on the right track at this point?
This weekend I’ll create validation sets that match the two approaches I thought of above to see if I can determine any material difference between the 3 approaches.
 A lot of logic is hidden in minute details.
A lot of logic is hidden in minute details.