Did you select GPU? Should be something like this …
Settings / Accelerator / Enable GPU

Setting split=2 for categorical variables would mean that every data point in the column is selected. Even setting anything greater than that would do the same. As you said, those values must just be arbitrary starting points to play with in the interact function.
1 Like
Why can an architecture like convnext train on datasets of different image dimensions? I.e. why do both 480x480 and 480x640 work out of the box?
It makes sense that it’s not a problem for the convolutional layers - the filters will just slide over the input images and return accordingly shaped feature maps - but at some point we reach a not-so-flexible fully connected layer. What happens then? Are extra neurons/weights added on the fly? Or are the fully connected layers always replaced entirely and trained from scratch?
In the “How random forests really works” notebook, the code in cell (#44) specifies the incorrect model for getting feature importance.
pd.DataFrame(dict(cols=trn_xs.columns, imp=m.feature_importances_)).plot('cols', 'imp', 'barh');
“m” is the DecisionTreeClassifier created in cell #34:
m = DecisionTreeClassifier(min_samples_leaf=50)
From the context, what was intended was to get the feature importance for the random forest, instead. The random forest model was created in cell #42 and assigned to “rf”:
rf = RandomForestClassifier(100, min_samples_leaf=5)
So, the random forest feature importance plot is displayed as follows:
pd.DataFrame(dict(cols=trn_xs.columns, imp=rf.feature_importances_)).plot('cols', 'imp', 'barh');
With this result:
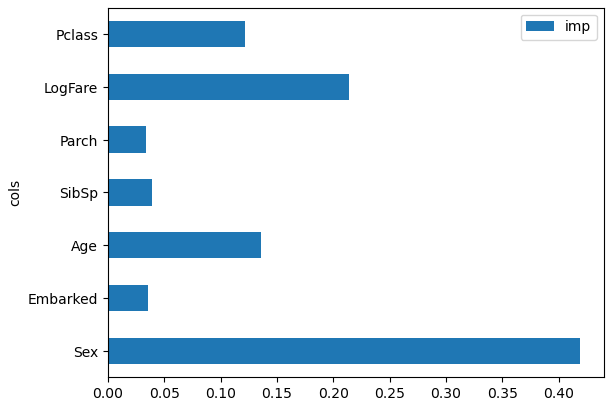
Which is substantially different from the feature importance for the single decision tree (which requires the commentary in the next text cell to be modified significantly).
For errors found in the course notebooks, is it preferred to clone them, make the fix, then make a pull request rather than just report?
Hi, Anyone has used DecisionTreeClassifier for multi class classification problem? if so is there a guide somewhere that i can read through to understand how to go about it?
Thank you!
I just used DecisionTreeClassifier and RandomForestClassifier for the first time in this notebook where I applied the fastai Lesson 6/Chapter 9 steps for this Kaggle Competition—you will likely find other people’s notebooks with similar/better examples.
There are a few key differences:
- I used accuracy instead of RMSE as a metric.
- Set
max_samplesto an appropriate value for your dataset (I used half of the dataset length as done in the text). - If you are training a neural net with
tabular_learner, when you create yourTabularPandasobject includey_block=CategoryBlock()since it’s a classification problem. - You have to map the indexes of the predicted class to the string name for Kaggle submission.
- When you do an ensemble, you can’t just take the average of the predictions, you have to stack and take the average of the probabilities and then get the index of the largest probably and map it to the class name.
Other than that I found that the lesson code was mostly reusable.
1 Like
Thank you for sharing your knowledge with me. Your insights have broadened my understanding and inspired me to learn more. NCEdCloud
1 Like
Thank you! I was working on same competition when I posted my original message. in the meanwhile I have managed to create few models using class notebooks as guidelines.
Thank you for your thoughts and sharing your notebook!
One of the things i am still trying to understand and get the feel of is hyper parameters. ![]()
1 Like
Yeah me too (regarding hyperparameters). Last night I tried out different n_estimators values (40, 60, and 80) but it didn’t really improve my accuracy, which asymptotes at 90%. I have not yet tried different max_samples, max_features, and min_samples_leaf values.
1 Like
@maritanap in case you are interested, I tried out different RandomForestClassifier hyperparameters in this post-competition Kaggle notebook and submitted their predictions to get these Private scores:
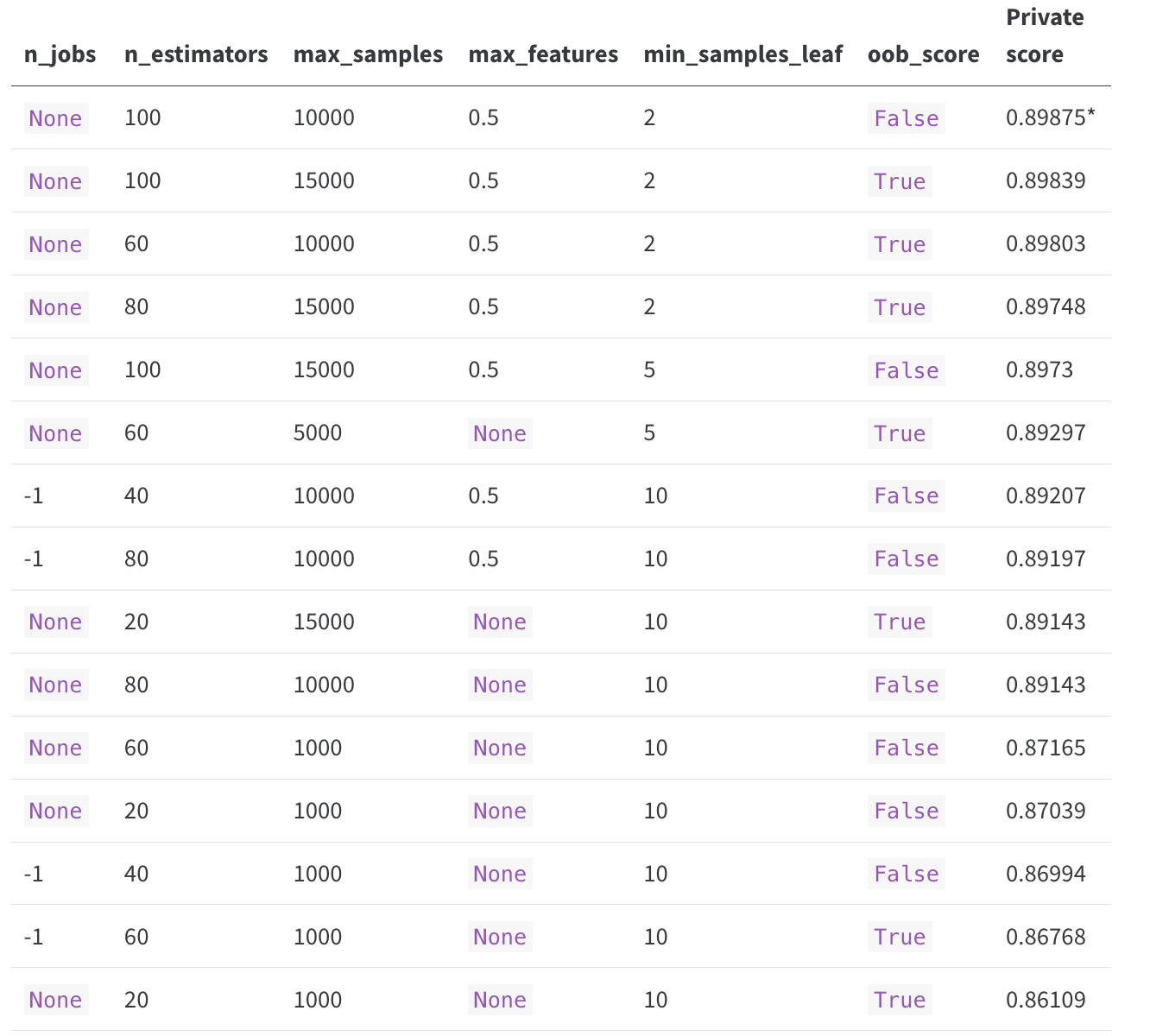
Certainly can’t make any general claims about Random Forests but note that a max_samples value of 1000 did not crack the top 10 of the 15 models I submitted and an n_estimators value of 20 or a min_samples_leaf value of 10 did not get into the top 5. I was kind of surprised as I expected too many total samples with too few minimum samples per leaf to overfit but it didn’t.
1 Like
Thank you for sharing!
1 Like
Hello everyone! I’ve been writting notebooks about lesson 6 content. I am using data from the playground series season 5 on Kaggle. Currently, I’ve written two notebooks, the first about decision trees and the second about random forests. I’d like to invite you to visit them. Any comments or feedback will be really appreciated.
great Karan I am also doing the same
Excellent Hafiz! Let me know if you share your work.
Hey guys! I just finished overhauling the Fastbook Chapter 9 notebook. Since the Dataset originally used isn’t availabe anymore, I used the House Prices - Advanced Regression Techniques. I essentially tried to keep all of the original information, and commented on it when it wasn’t applicable to the new dataset or when there were other considerations to be taken with the new dataset. However I also ran into a couple of things I was unsure about or couldn’t quite explain to myself. Feel free to have a look here.
This way you can go through all the very useful explanation, but you can also run all of the code since it’s now based on an available Dataset.