Just re-do the command that created your model (it may be the same one as the one that created your Learner).
1 Like
Before we unfreeze the model and check for lr again, do we need to train till the model till we get the best accuracy or do we train for a couple of epoch and search for the lr?
If only ;). You will start overfitting way before 50 epochs.
2 Likes
So why are deep neural nets able to overcome the “overfitting” problem with continued training even as as the training loss asymptotes well below the validation loss? For example, in the 05_pet_breeds notebook we see this figure:
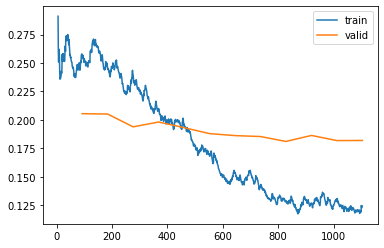
The validation loss continues to improve or stays flat, even as the training loss dips well below it.
In classical machine learning (+some deep learning problems), the validation loss begins to spiral upwards, since the training loss decreases solely because the model is starting to memorize the training examples, and cannot generalize to the validation examples as well. For example we typically see something like this (image credit):
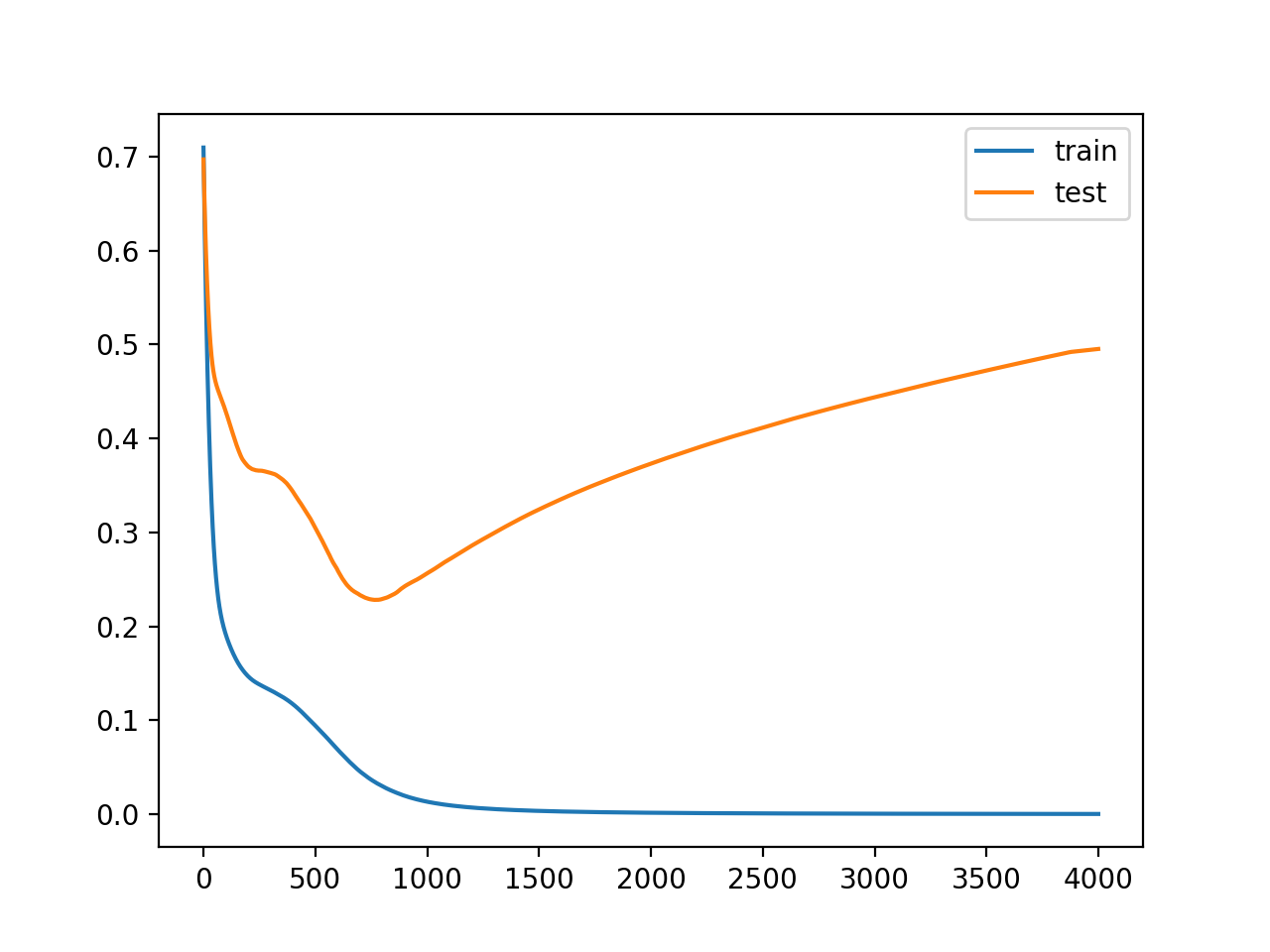
{kind=link}
I understand that some researchers are working on this (e.g., the Double Deep Descent paper) and that there may not be a clear answer yet. But perhaps there’s an intuitive reason why these two trends are so different?
4 Likes
Question for Jeremy from Larry D. (TWiML Study Group):
How do you know (or suspect) when you can “do better”?
4 Likes
Searching for the lr should be done before training, otherwise, you don’t know what to pass to your call to fit/fit_one_cycle.
No its not required. Any time you can use lr_find.
It looks like we can create sort of a gradient of learning rates using the slice function. How do we fine-tune learning rates for epochs not right at the end, like what if the epochs that needed faster learning rates were in the middle, but both the beginning and final epochs needed lower ones? Or does that not happen in practice?
ok, thank you!
What is the objective of only computing the gradients for the last layer and not do it for the earlier layers ?
I was referring to the training after the first lr_find, when we do the fine tuning and the unfreeze…
No they are not. You are not seeing overfitting because the defaults of fastai includes a few regularization techniques, or you are not training for long enough, but the seocnd curve is doomed to happen unless you use some very powerful form of regularization.
3 Likes
Is there a standard format for sharing pretrained models?
Assuming smaller batches leads to less accuracy per patch: If you use a deeper architecture but have smaller batches would that lead to a net zero gain in accuracy for your model?
1 Like
That’s only when the model is frozen, which only happens in transfer learning, when the rest of your model has been pretrained. So you don’t want to break those pretrained weights.
1 Like
Because only the last layer weights are random initialized.
1 Like
I’ve notice that the GPU memory does not seem to be cleaned or released after each training fit. Is there a way to release it/reset without the restart?
That’s python getting in our way. It usually gets released once you replace it with a new model/fit, but not always.
Does dropping floating point number precision (switching from FP32 to FP16) have an impact on final loss?
4 Likes
Previously, it was suggested that using .to_fp16() actually decreased error rate? Am I misremembering that, or has fastai’s thinking changed?
I think it was something to do with the time spent optimizing numbers that didn’t make a difference in the end?