I have just tested @muellerzr’s notebook. It works fine. Your error message seems to be coming from fastcore, so most likely your fastcore and/or fastai2 installation(s) are not up-to-date, or they don’t have compatible versions to each other. Try upgrading/updating the installations, and run the notebook again.
I try to build a image regression model (PointBlock). If I apply aug_transforms the keypoints sometimes are outside of the actual image. Is there a way to avoid that or discard the augmented image if that happens?
Jeremy says at the end of chapter 5 in the part “Further research” that we should try to improve pet breeds model’s accuracy and search in the forum for other student’s solutions. I can’t find the solutions of other students or their accuracies.
Can someone help me please?
In the lesson for pet_breeds I noticed this about Cross Entropy Loss which I’m struggling to understand.
We’re only picking the loss from the column containing the correct label. We don’t need to consider the other columns, because by the definition of softmax, they add up to 1 minus the activation corresponding to the correct label. Therefore, making the activation for the correct label as high as possible must mean we’re also decreasing the activations of the remaining columns.
If we are only choosing the column with the correct label, wouldn’t we be maximising the loss and not minimising it?
I think if you stopped right there, yes, it would maximize the loss. But you can just define the loss as the negative values of sm_acts, and now you’re minimizing loss
Also, when we go one step further and take the negative log of the softmaxed activations, a confident correct prediction gets a small loss: -log(0.99) = 0.0101
and a wrong prediction (the correct class has a low probability) gets a high loss: -log(0.01) = 4.6052
Remember, nll_loss does not calculate the log despite its name.
I ended up punching -log(0.09) vs -log(0.9) in a calculator last night and it made sense.
I’m trying to get an intuition for this and it makes sense now. When we take the negative, it minimizes the loss and if we take the log of that, it helps make the function sensitive to small difference such as 0.99 and 0.999 (which is really a 10X improvement).
I get the step is actually log_softmax followed by nll_loss despite the name.
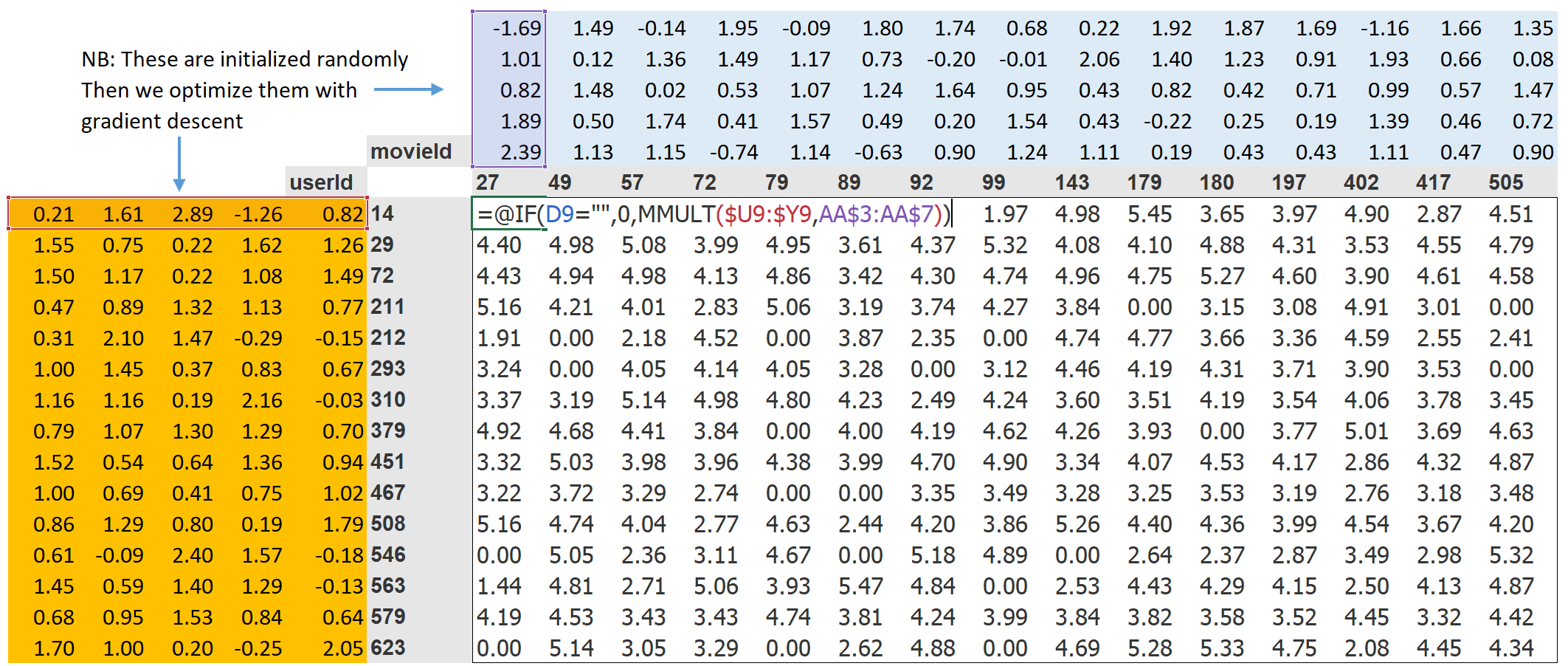
Here, Jeremy took a batch of 15: so 15 movies and 15 users, and 5 latent factors. Jeremy then calculated the predictions by taking the dot product, yielding 15x15 predictions. I am clear till here.
we are using (users * movies).sum(dim=1) that yields a shape of batch size. So for a batch of 15, it would yield a tensor of 15 predictions. Shouldn’t it be 15 x 15, a prediction for each combination of user and movie?
Hi,
I also didn’t find other students solutions, I’m sure there is an official topic somewhere and if someone can point to the link it will be very helpful
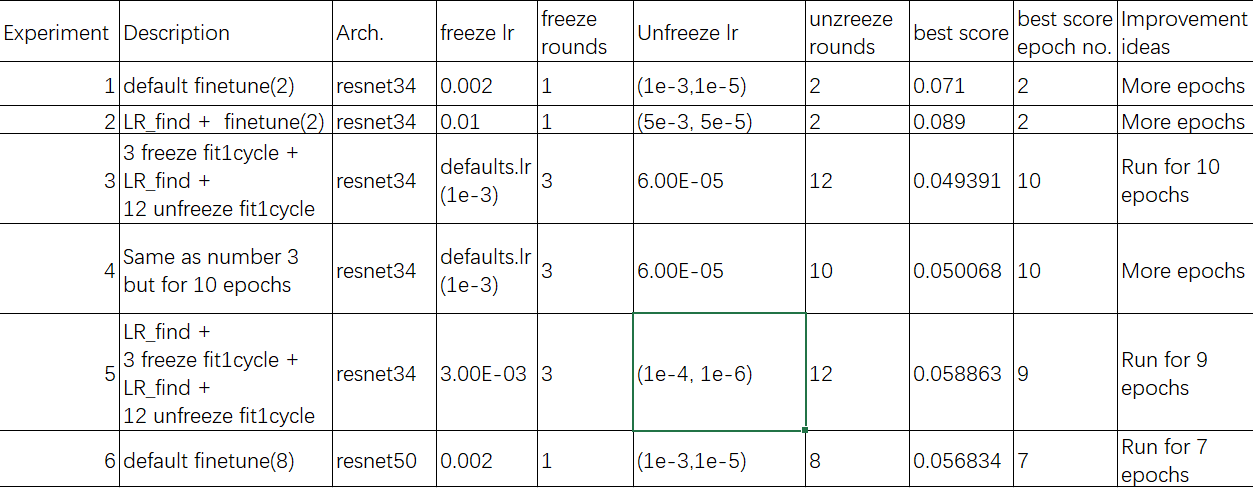
For myself I just tried to experiment according to Jeremy’s suggestions, I did manage to improve the model but I think it’s mostly a “lucky run” given the stochastic nature of the algorithm.
I summarized my experiments in this Excel table (and added some suggestions for further experiments based on the results), if someone interested I will clean the notebook and prepare a more detailed blog post about this task: