Sylvain addressed it during the class and said it has been updated in the book(are you not seeing the changes? ) Those were the changes (-ve sign and interchanging the where arguments) 
Any tips on how to train faster?
I followed the first lectures, scrapped some data and I am trying to build my classifier. Until the dataloaders, all good. The problem comes when the actual training starts since my dataset is quite large. First, I am trying to choose a good learning rate:
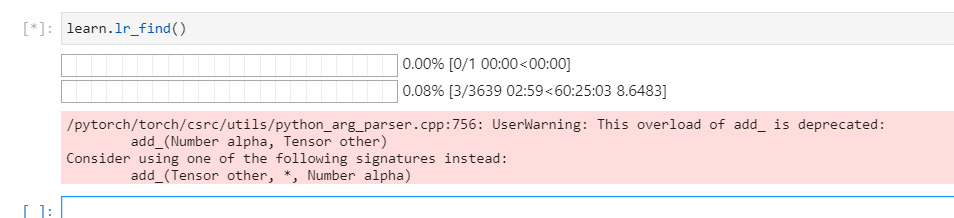
I am training resnet50 on a V100 (p3.2xlarge on AWS) with 250K images. I resized the images to 500x500 since they were really high quality and I felt it was a pity to throw this information away, i.e. downsizing. I am also using mixed-precision training like Jeremy said in this lecture… but it looks as if it will take forever. I thought… is there a way to run fastai2 on multiple GPUs? In Pytorch I would do it like this.
to_fp16() could help.
you could start. with smaller image sizes and increase them (progressive resizing)
not sure if you have already tried these
Yes you can use nn.DataParallel with fastai as shown here
1 Like
Do you know of any credible (working in production) updates to Smith’s work? Its difficult to parse the 500 citations to figure out which one is directly related to Smith’s work and which works. @sgugger @jeremy
A simple question regarding the learning rate finder:
- Which learning rate should I pick to train a model?
This paragraph in the book confuses me a bit.
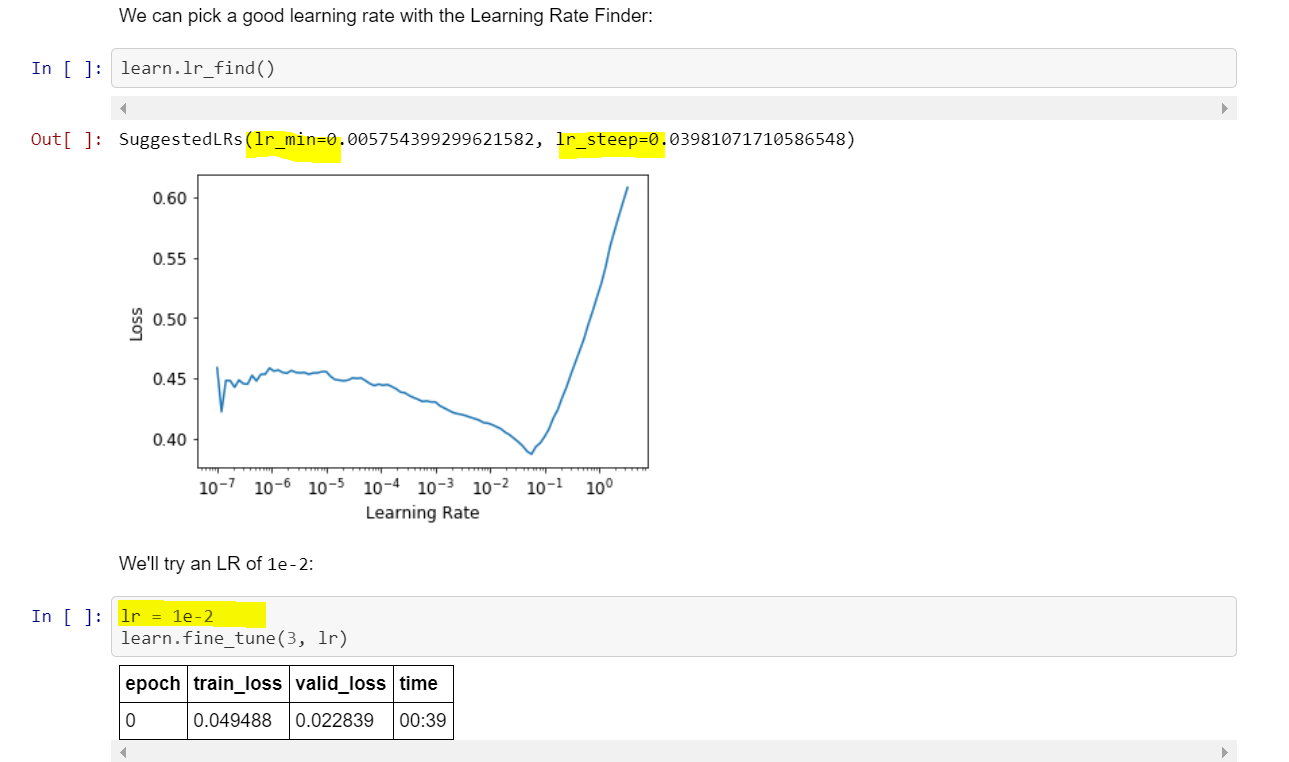
If I understood it correctly, the lr_min is actually the lr_min/10, right?
Moreover, why is Jeremy taking another value?
So the code is suggests automatically computed upper and lower bounds for the learning rates. lr_steep is the learning rate at which the slope is steepest, and is about 0.04 for this case.
But our learning curve has a weird kinky shape, with the maximum slope occurring just to the left of the learning rate minimum.
So we ask ourselves: should we trust the suggested value?
Is lr_steep = 0.04 a good choice for the learning rate?
After some thought, we realize that it is not, because there is no room to learn – SGD will immediately take you to the minimum, and then will be stuck there. So Jeremy pulls back to lr = 0.01, which is still on the steep part of learning rate curve, but not right next to the minimum, so that the model will be able to learn.
2 Likes
Thanks a lot @jcatanza!
(…) the code suggests automatically computed upper and lower bounds for the learning rates.
I would have said, lr_steep should be the lower bound and lr_min the upper bound but since we are dividing it by 10 it is the other way around, right?
In addition, from what I understood, you are saying that generally we want to take lr_steep as the learning rate (not lr_min) although in this case we are just ignoring the recommendation due to the reasons you stated.
Yes. So when do we use lr_min?
lr_min comes into play for transfer learning, which is the process of applying weights from a pretrained model to solve a more specialized problem.
The procedure is, roughly:
- Import weights from the pre-trained model
- Chop off the the head (last layer) from the pre-trained model, replacing it with a custom head that is appropriate for our specialized problem.
- Freeze all the weights except the weights in the custom head
-
Train the last layer with the learning rate set to
lr_steep. - Unfreeze all the weights
- Separate the neural net into layer groups, from shallow to deep
-
Fine-tune the weights by training the network with differential learning rates that progressively decrease from
lr_steepat the last layer tolr_minfor the deepest layers.
The reason for progressively decreasing the learning rate towards the deeper layers is this: we expect that the deeper the layer, the closer the pretrained weights are to their optimal values, and the more gently they need to be trained. Whereas we want the last layer to be trained hard, i.e with the highest learning rate possible.
5 Likes
Hi Joseph,
During transfer learning of resnet, I noticed the batchnorm layers don’t become frozen even if you do learn.freeze(). You have to manually turn off the gradients for the batchnorm layers, if you want everything frozen.
Do you know why the batchnorm layers are not frozen? Is it to get better statistics of the inputs when transfer learning?
Thanks,
Daniel
1 Like
This is interesting! I didn’t know this, and don’t yet know why batchnorm is implemented this way.
@DanielLam, @jcatanza, The short answer is: by unfreezing batchnorm our model get a better accuracy.
Now the why:
When we use a pretrained model, the batchnorm layer contains the mean, the standard deviation, the gamma and beta (2 trainable parameters) of the pretrained dataset (ImageNet in the case of images).
If we freeze our batchnorm layer with our dataset, we are feeding our model with our data (our images) and normalizing our batch with ImageNet mean, standard deviation, gamma and beta: Those values are off specially if our images are different from the ImageNet images. Therefore, your normalized activations are also off which leads to less than optimal results.
We keep the batchnorm layer unfrozen because while we are training the model and for each batch we will calculate the mean, the standard deviation of the activations of our data (batch of images), and updating (training) the corresponding gamma and beta, and using those results to normalize our activations of the current batch: The normalized activations are therefore more aligned with our images (dataset) as opposed to those obtained with a frozen batchnorm.
5 Likes
Thanks @farid, excellent explanation!
1 Like
Hi All,
I am trying to use multi-label classification for the bear classification example. When I use the MultiCategoryBlock , I get labels with 11 classes (corresponding to the unique alphabets in the class names) rather than the expected 3.
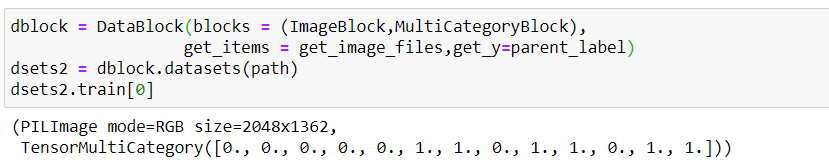
What am I missing?
Hi,
Thanks for the reply. Do you know if this has been published somewhere or a notebook showing the differences?
I’m quoting Jeremy from lesson 12 about batchnorm:
“Anytime something weird happens to your neural net it’s almost certain it’s because of the batchnorm because batchnorm makes everything weird!”
To answer your question, you might check out the 11a_transfer_learning.ipynb from lesson 12 - Part-2 2019 course. You can also jump to lesson 12 video portion where Jeremy explains the effect of the mean, the standard deviation, and the batchnorm trainable parameters on training a custom model that I am referring to in my previous post.
Here a little summary about the experiment that he showed in that video:
1 - He created a custom head for his model
2 - He froze the whole body (including the batchnorm layers) of the pretrained model.
3 - He trained his model for 3 epochs, and he got 54% accuracy
4 - He unfroze the whole body, and train the model for 5 epochs, and he got 56% accuracy (which was surprising low)
Then, he decided to unfreeze batchnorm from the beginning (meaning while training the custom head). He showed the following steps:
1 - He froze the whole body except the batchnorm layers of the pretrained model.
2 - He trained his model for 3 epochs, and he got 58% accuracy (which is already better than above)
3 - But more importantly, when he unfroze the whole body, and train the model for 5 epochs, he got 70% accuracy (and that’s a huge jump)
5 Likes
Interesting. Thank you for the response.
1 Like
I believe that yes, this is a binary classification task. You could get pictures of people wearing eyeglasses and people not wearing eyeglasses, using one of the imagenet trained models you should get great results.
I am still struggling with this. Given the above approach failed, I tried renaming all the files so that I can use the RegexLabeller approach to get the class names. This didn’t work.
I then tried re-running @muellerzr notebook
But I get the same error when I try to create the dataloaders. Is this an issue with paperspace?
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in
----> 1 dls = pets_multi.dataloaders(untar_data(URLs.PETS)/“images”, bs=32)
/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/data/block.py in dataloaders(self, source, path, verbose, **kwargs)
96
97 def dataloaders(self, source, path=’.’, verbose=False, **kwargs):
—> 98 dsets = self.datasets(source)
99 kwargs = {**self.dls_kwargs, **kwargs, ‘verbose’: verbose}
100 return dsets.dataloaders(path=path, after_item=self.item_tfms, after_batch=self.batch_tfms, **kwargs)
/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/data/block.py in datasets(self, source, verbose)
93 splits = (self.splitter or RandomSplitter())(items)
94 pv(f"{len(splits)} datasets of sizes {’,’.join([str(len(s)) for s in splits])}", verbose)
—> 95 return Datasets(items, tfms=self._combine_type_tfms(), splits=splits, dl_type=self.dl_type, n_inp=self.n_inp, verbose=verbose)
96
97 def dataloaders(self, source, path=’.’, verbose=False, **kwargs):
/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/data/core.py in init(self, items, tfms, tls, n_inp, dl_type, **kwargs)
272 def init(self, items=None, tfms=None, tls=None, n_inp=None, dl_type=None, **kwargs):
273 super().init(dl_type=dl_type)
–> 274 self.tls = L(tls if tls else [TfmdLists(items, t, **kwargs) for t in L(ifnone(tfms,[None]))])
275 self.n_inp = (1 if len(self.tls)==1 else len(self.tls)-1) if n_inp is None else n_inp
276
/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/data/core.py in (.0)
272 def init(self, items=None, tfms=None, tls=None, n_inp=None, dl_type=None, **kwargs):
273 super().init(dl_type=dl_type)
–> 274 self.tls = L(tls if tls else [TfmdLists(items, t, **kwargs) for t in L(ifnone(tfms,[None]))])
275 self.n_inp = (1 if len(self.tls)==1 else len(self.tls)-1) if n_inp is None else n_inp
276
/opt/conda/envs/fastai/lib/python3.7/site-packages/fastcore/foundation.py in call(cls, x, args, **kwargs)
39 return x
40
—> 41 res = super().call(((x,) + args), **kwargs)
42 res._newchk = 0
43 return res
/opt/conda/envs/fastai/lib/python3.7/site-packages/fastai2/data/core.py in init(self, items, tfms, use_list, do_setup, split_idx, train_setup, splits, types, verbose)
208 if isinstance(tfms,TfmdLists): tfms = tfms.tfms
209 if isinstance(tfms,Pipeline): do_setup=False
–> 210 self.tfms = Pipeline(tfms, split_idx=split_idx)
211 self.types = types
212 if do_setup:
/opt/conda/envs/fastai/lib/python3.7/site-packages/fastcore/transform.py in init(self, funcs, split_idx)
167 else:
168 if isinstance(funcs, Transform): funcs = [funcs]
–> 169 self.fs = L(ifnone(funcs,[noop])).map(mk_transform).sorted(key=‘order’)
170 for f in self.fs:
171 name = camel2snake(type(f).name)
/opt/conda/envs/fastai/lib/python3.7/site-packages/fastcore/foundation.py in sorted(self, key, reverse)
346 elif isinstance(key,int): k=itemgetter(key)
347 else: k=key
–> 348 return self._new(sorted(self.items, key=k, reverse=reverse))
349
350 @classmethod
TypeError: ‘<’ not supported between instances of ‘int’ and ‘L’
Does anyone have a working notebook demonstrating how to do this? I have been stuck at this for a while due to an error I am getting when creating the data loaders as described here