Perhaps you can base the importance on the relative probabilities of the classifications. So if the sigmoid gave 99% probability that the image contains a dog, and 75% probability that the image also contains a fish, you might decide that the dog is more important than the fish.
I think you’ll still be evaluating these losses in mini-batches, so there’s no need to worry about memory problems if you were able to train your model!
You could write a dataset object that grabs the data from disk as necessary. Maybe optimize the “shuffle” so that you can have as few reads as possible?
I was just comparing the binary_cross_entropy and nn.BCEWithLogitsLoss and found there to be a significant difference in the loss calculated as shown below…

Am I doing something wrong here?
1 Like
ok then how to ‘stitch’ it all back up into one fully trained model?
This might be a dumb question, but is this a generator reading from the source file(s) and yielding data “as you go”, or is it loading it all into memory up front?
1 Like
Since the training set has already been “used” to derive the model parameters, it somehow doesn’t feel “kosher” to use the training set again to tune the hyper-parameters. I have to think more to come up with a more principled reason, though.
In practice you could reserve a test set in addition to the validation set. Tune your model hyper-parameters (such as the threshold) on the validation set, then refit the tuned model with all the data from the training and validation sets.
1 Like
Oh that sounds like a bug. Note that a - is missing, but it should give the opposite of PyTorch. Will look at it tomorrow.
2 Likes
If we’re talking about the hyperparameter optimization represented in this graph:
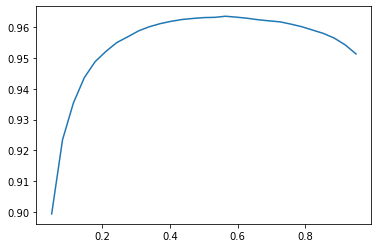
then the important part to remember is that the model parameters are done training. What we’re optimizing now, rather than the model, is the hyperparameter for the accuracy_multi metric.
No it’s not loading upfront, it’s loading as needed.
1 Like
Sigh, another example of data set impermanence… 
4 Likes
is radam optim independent of learning rate ?
is it implemented in fastai?
1 Like
What happens if you have two inputs (e.g. dots and faces) and you want one output (e.g. is the dot over the face?)
It’s not clear to me how get_items expands to accept multiple inputs?
RAdam is in fastai. And no, it’s not independent of the learning rate.
Checked and we mixed where to put inputs and 1-inputs, that’s where the bug is. Correct implementation is
-torch.where(targets==1, inputs, 1-inputs).log().mean()
10 Likes
Thanks for bringing up splitting by people as well! I found a lot of people were having this issue in the class.
1 Like
Can you provide “images” with an arbitrary number of channels as inputs? Specifically, more than 3 channels?
4 Likes
When you use data augmentation on biwiki dataset, wouldn’t the center of the image change, thus the y label would be different?
1 Like
So it is possible in fastai to train a multi-point regressor (predicting more than just the center of the person)?
1 Like