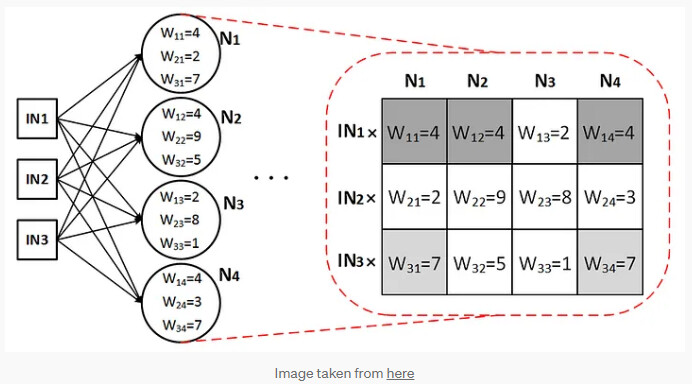
We begin by having val_indep and multiply each row of feature data with coeffs.
In the next step (before Jeremy began with Deep Learning), instead of coeff being a vector converted coeff to be a matrix and in deep learning we have layer 1 as a matrix

and then pass the output throgh ReLU like F.relu(indeps@l1)
What I need help with:
- I am not really sure what matrix means when I try to visualise in a neural network like below.
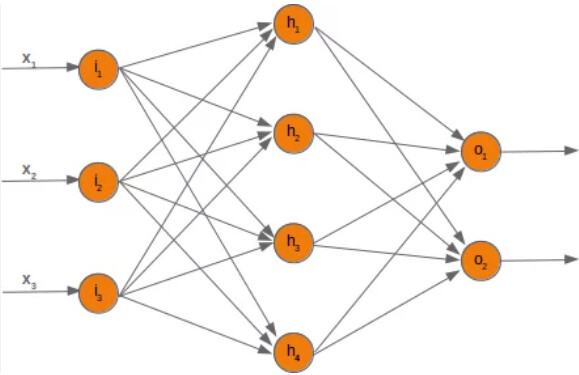
- If I change n_hidden to may be 5, how does it change the neural network physically?
- If this means that we will have 5 layers before output layer, why do we pass it through ReLU only in the end. Should’nt it be after each layer we pass through ReLU?
- Would thinking of a physical representation become a limitation when dealing with advanced stuff?