I haven’t tried it myself, but this might be an option. Please let us know how it goes if you try ![]()
1 Like
Thanks @hiromi for the idea but it does not work through my Microsoft Excel online. File can not be opened (I took it from https://github.com/fastai/fastai/tree/master/courses/dl1/excel).
It turned out to be pretty easy to do this on your own. You can substitute rankings with something similar:
- advertised campaigns - sites - were there conversions
- stores - products - sales level
Anything related to your business should be just fine and probably more interesting to discover.
2 Likes
You don’t need the macros - all they do is copy the 2 output cells back to the two input cells. But you can see a full epoch in the spreadsheet without needing to do this at all.
1 Like
@jeremy - is it possible a bug has been introduced to the fast.ai data set library for collaborative filters, or is it the data in the movielens, so that whenever I follow the notebook it crashes immediately when running learn.fit, on using a pandas library?
I have restarted everything. I have tried upgrading all packages, the fast.ai library is up-to-date as is conda env. I have deleted the data directory and re-unzipped to re-create it. The steps before this run OK so the data looks OK.
I do not get this error using learn.fit with our Dogs and Cats data set - but its a different learner…
The line it fails on (I have also tried with SGD optimzer and get the same problem):
~/src/anaconda3/envs/fastai/lib/python3.6/site-packages/pandas/core/indexes/base.py in get_value(self, series, key)
2555 try:
2556 return self._engine.get_value(s, k,
-> 2557 tz=getattr(series.dtype, 'tz', None))
2558 except KeyError as e1:
2559 if len(self) > 0 and self.inferred_type in ['integer', 'boolean']:
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_value()
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_value()
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.Int64HashTable.get_item()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.Int64HashTable.get_item()
KeyError: 55759
The full trace:
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_value()
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_value()
pandas/_libs/index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.Int64HashTable.get_item()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.Int64HashTable.get_item()
KeyError: 55759
2 Likes
It is indeed possible! I’ve been fixing things up for tonight’s NLP class, and may well have caused a problem in earlier notebooks. Let me check now and get back to you…
Thanks!
I also have a problem further on when creating the examples by scratch:
fit(model, data, 3, opt, F.mse_loss)
Epoch
0% 0/3 [00:00<?, ?it/s]
0%| | 0/1251 [00:00<?, ?it/s]
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-25-09a5bc469dee> in <module>()
----> 1 fit(model, data, 3, opt, F.mse_loss)
~/fastai/courses/dl1/fastai/model.py in fit(model, data, epochs, opt, crit, metrics, callbacks, **kwargs)
83 batch_num += 1
84 for cb in callbacks: cb.on_batch_begin()
---> 85 loss = stepper.step(V(x),V(y))
86 avg_loss = avg_loss * avg_mom + loss * (1-avg_mom)
87 debias_loss = avg_loss / (1 - avg_mom**batch_num)
~/fastai/courses/dl1/fastai/model.py in step(self, xs, y)
41 if isinstance(output,(tuple,list)): output,*xtra = output
42 self.opt.zero_grad()
---> 43 loss = raw_loss = self.crit(output, y)
44 if self.reg_fn: loss = self.reg_fn(output, xtra, raw_loss)
45 loss.backward()
~/src/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/functional.py in mse_loss(input, target, size_average)
817
818 def mse_loss(input, target, size_average=True):
--> 819 return _functions.thnn.MSELoss.apply(input, target, size_average)
820
821
~/src/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/_functions/thnn/auto.py in forward(ctx, input, target, *args)
45 output = input.new(1)
46 getattr(ctx._backend, update_output.name)(ctx._backend.library_state, input, target,
---> 47 output, *ctx.additional_args)
48 return output
49
TypeError: CudaMSECriterion_updateOutput received an invalid combination of arguments - got (int, torch.cuda.FloatTensor, torch.cuda.DoubleTensor, torch.cuda.FloatTensor, bool), but expected (int state, torch.cuda.FloatTensor input, torch.cuda.FloatTensor target, torch.cuda.FloatTensor output, bool sizeAverage)
OK these should both be fixed now - thanks for reporting the problem!
1 Like
Thanks @jeremy - all good for the first part, but again with the “from scratch” area of my notebook I got the cuda error - but then saw that you had replaced y = ratings[‘rating’] with y = ratings[‘rating’].astype(np.float32) - implementing this fixed things.
I guess anyone running old code based on the previous version of the noteboook will still get those cuda errors…
Hi guys!
Is there a way to calculate the accuracy of the CollabFilter? Just by the validation loss is difficult to understand how good is the algorithm, especially when you are using your own dataset and don’t have a benchmark.
I tried to use the accuracy_thresh(0) that uses accuracy_multi behind the scenes, but the result is always the same 0.3414.
I used:
- AUC for 2 class CF
- % of correctly classified in each bucket for multiclass
Video timelines for Lesson 5
-
00:00:01 Review of students articles and works
- “Structured Deep Learning” for structured data using Entity Embeddings,
- “Fun with small image data-sets (part 2)” with unfreezing layers and downloading images from Google,
- “How do we train neural networks” technical writing with detailled walk-through,
- “Plant Seedlings Kaggle competition”
-
00:07:45 Starting the 2nd half of the course: what’s next ?
MovieLens dataset: build an effective collaborative filtering model from scratch -
00:12:15 Why a matrix factorization and not a neural net ?
Using Excel solver for Gradient Descent ‘GRG Nonlinear’ -
00:23:15 What are the negative values for ‘movieid’ & ‘userid’, and more student questions
-
00:26:00 Collaborative filtering notebook, ‘n_factors=’, ‘CollabFilterDataset.from_csv’
-
00:34:05 Dot Product example in PyTorch, module ‘DotProduct()’
-
00:41:45 Class ‘EmbeddingDot()’
-
00:47:05 Kaiming He Initialization (via DeepGrid),
sticking an underscore ‘_’ in PyTorch, ‘ColumnarModelData.from_data_frame()’, ‘optim.SGD()’ -
Pause
-
01:00:30 Improving the MovieLens model in Excel again,
adding a constant for movies and users called “a bias” -
01:02:30 Function ‘get_emb(ni, nf)’ and Class ‘EmbeddingDotBias(nn.Module)’, ‘.squeeze()’ for broadcasting in PyTorch
-
01:06:45 Squeashing the ratings between 1 and 5, with Sigmoid function
-
01:12:30 What happened in the Netflix prize, looking at ‘column_data.py’ module and ‘get_learner()’
-
01:17:15 Creating a Neural Net version “of all this”, using the ‘movielens_emb’ tab in our Excel file, the “Mini net” section in ‘lesson5-movielens.ipynb’
-
01:33:15 What is happening inside the “Training Loop”, what the optimizer ‘optim.SGD()’ and ‘momentum=’ do, spreadsheet ‘graddesc.xlsm’ basic tab
-
01:41:15 “You don’t need to learn how to calculate derivates & integrals, but you need to learn how to think about the spatially”, the ‘chain rule’, ‘jacobian’ & ‘hessian’
-
01:53:45 Spreadsheet ‘Momentum’ tab
-
01:59:05 Spreasheet ‘Adam’ tab
-
02:12:01 Beyond Dropout: ‘Weight-decay’ or L2 regularization
6 Likes
Thanks @sermakarevich!
Embedding Dimensions:
In the Excel spread sheet the Embedding for movies is a 5x15 matrix (before the bias is applied) and the user Embedding matrix is 15x5.
However the Embedding matrices used in the Lesson5 Notebook seem to be off where users is 671x50 and movies is 9066x50. I thought to multiply matrices the number of columns must match the number of rows vice versa…

It seemed like Jeremy first multiplied the movie embedding and user embeddings to (replacing empty ratings with zero) to determine the first initial predictions and to update the factors in the embedding matrices.
Do I have this right?
1 Like
I had the same issue with the Rossman Notebook, I fixed by replacing:
md = ColumnarModelData.from_data_frame(PATH, val_idx, df, yl, cat_flds=cat_vars, bs=128, test_df=df_test)
with
md = ColumnarModelData.from_data_frame(PATH, val_idx, df, yl.astype(np.float32), cat_flds=cat_vars, bs=128, test_df=df_test)
until (I think) it will modified directly inside the method ![]()
Thanks !
I agree, would be better if the method coped with the data type and ensured it is correct - seems awkward to have to explicity cast it this way… Hopefully @jeremy will tidy it up after the “dust has settled” - though I figure that he is incredibly busy all of the time!
Variation in result of movielens
While nb has validation loss of 0.767

my validation loss is .894 which doesn’t get a better solution than previous benchmarks. My RMSE is .945 vs .91 of best. Fastai’s nb has RMSE of .881
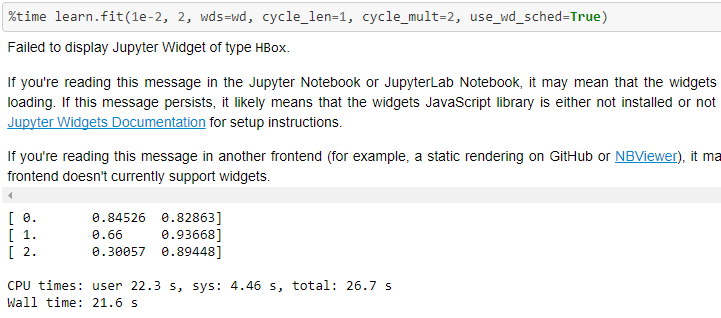
Q1. What could be the reason behind this variation?
Link to my nb
Q2. There training loss seems to be drastically changing from .84 to .3 in just 3 epochs vs .81 to .6 in fastai nb.
1 Like
I’d like some clarity as well, but this is what might be happening:
The results that you see in the notebook are from a previous run when we were using SGD with momentum as the optimizer (the previous default in fastai).
The notebooks were updated recently with AdamW implementation (as did the fastai code) to reflect the new optimizer usage, but doesn’t seem to have been rerun. So you see the old results with new code changes.
Owing to this, I’d expect to see some variation. But it seems to kinda start overfitting after only 1 epoch. 
[Edit]: If I do learn.lr_find(), it seems to indicate that an lr of 1e-2 might be high.
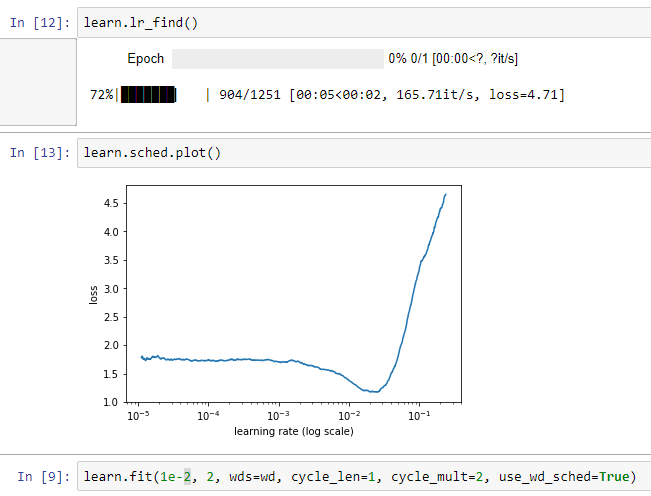
Somewhere around 3e-3 or 4e-3 seemed to work better.
1 Like
I’m blind to overfitting. 
But, I’m curious to know what would be optimal lr in this case?
xe-3 would have been a better choice because we want the weights(ultimately the loss I mean) to converge slowly and steadily or otherwise we might end up jumping around the two cliffs as Jeremy said…(if we choose the lr to be too close around the sunken part in the graph)
Our motive is to select the best possiblelr which will help us to converge and I always do a lr/10 of the value shown in the graph(min value) and it seems to work but sometimes need to play around with it also as loss didn’t converge when it goes to high…
Please correct me if I understood it incorrectly…
2 Likes