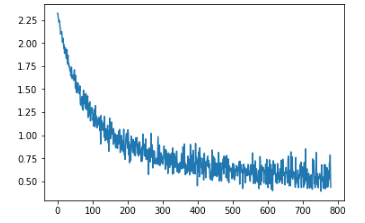
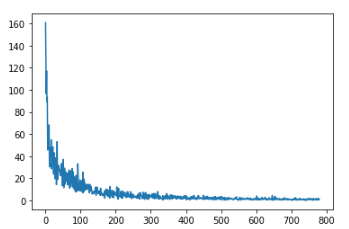
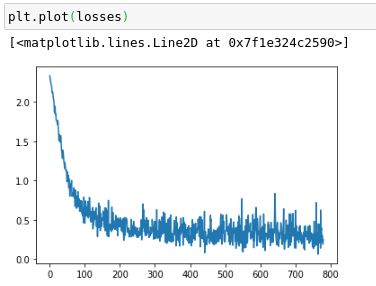
I’m looking at this snippet from the class notes for lesson 2, since i needed to review for lesson 5.
def update():
y_hat = x@a
loss = mse(y, y_hat)
if t % 10 == 0: print(loss)
loss.backward()
with torch.no_grad():
a.sub_(lr * a.grad) // this line!!!
a.grad.zero_()
What I’m not understanding is how does a.grad get populated. a is not passed into loss.backward() and I don’t see how it could reference it. If anyone has a suggestion on understanding this line, it would be appreciated.
As Jeremy asked in the Lesson 5,
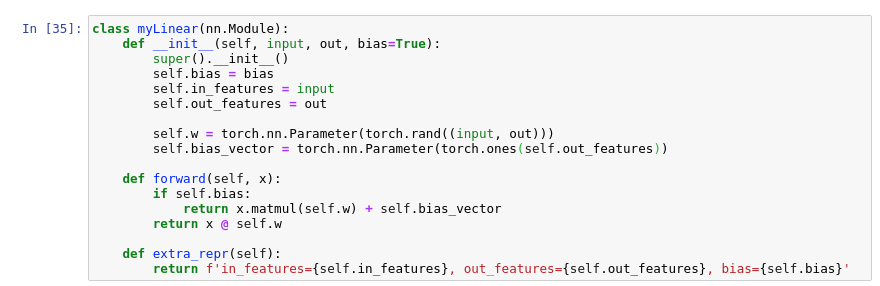
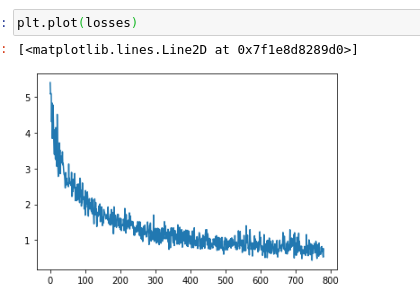
I just re-created the NN.linear class and Adam optimizer from scratch.
The only blurry part is the first weights update.
Since Adam relies on having previous update vectors to process the new updates, I used regular SGD for the first update.
But how is this normally done?
Of course feel free to criticize my code and the way I mad it work.
I’m not fully understanding it myself but from what I actually understood:
The parameters of the NN layers are matrices of weights and bias stored as Pytorch Tensors.
When a tensor is created there is a boolean parameter called ‘Requires_grad’.
Here comes the blurry part for me so take it with a grain of salt (I have to digg in the source code of autograd):
If ‘Requiers_grad’ is set to True, the tensors is created with an extra “grads matrix” of same size and empty.
Then, when you call “loss.backward()”, Pytorch is somehow able to go back to the formula that produced ‘Loss’ and find the tensors involved for which “requiers_grad=True”.
Pytorch then processes the partial derivative for each entry in the tensor and stores the result in the extra “grads matrix”.
So when you call ‘a.grad’ you are indeed only looking in this “grads matrix” attached to ‘a’.
Is that somehow clear?
This is the formula to update the parameters of the neural net with the SGD method.
Maybe you’ll understand it better like this:
new_parameter = old_parameter - learning_rate * parameter.grad
parameter: the matrix of weights or biases stored in the layer
learning_rate: is just a scaling value so the model will not move the weights too fast. (Jeremy talks about this one at great length in all the lessons)
parameter.grad : is the ‘partial derivative’ of the loss when you move just a little bit each separate weight.
So for each weight: it takes it’s partial derivative to the loss (what we call ‘grade’), scales it with the Learning_rate, and substract all this to the present weight to get the new weight.
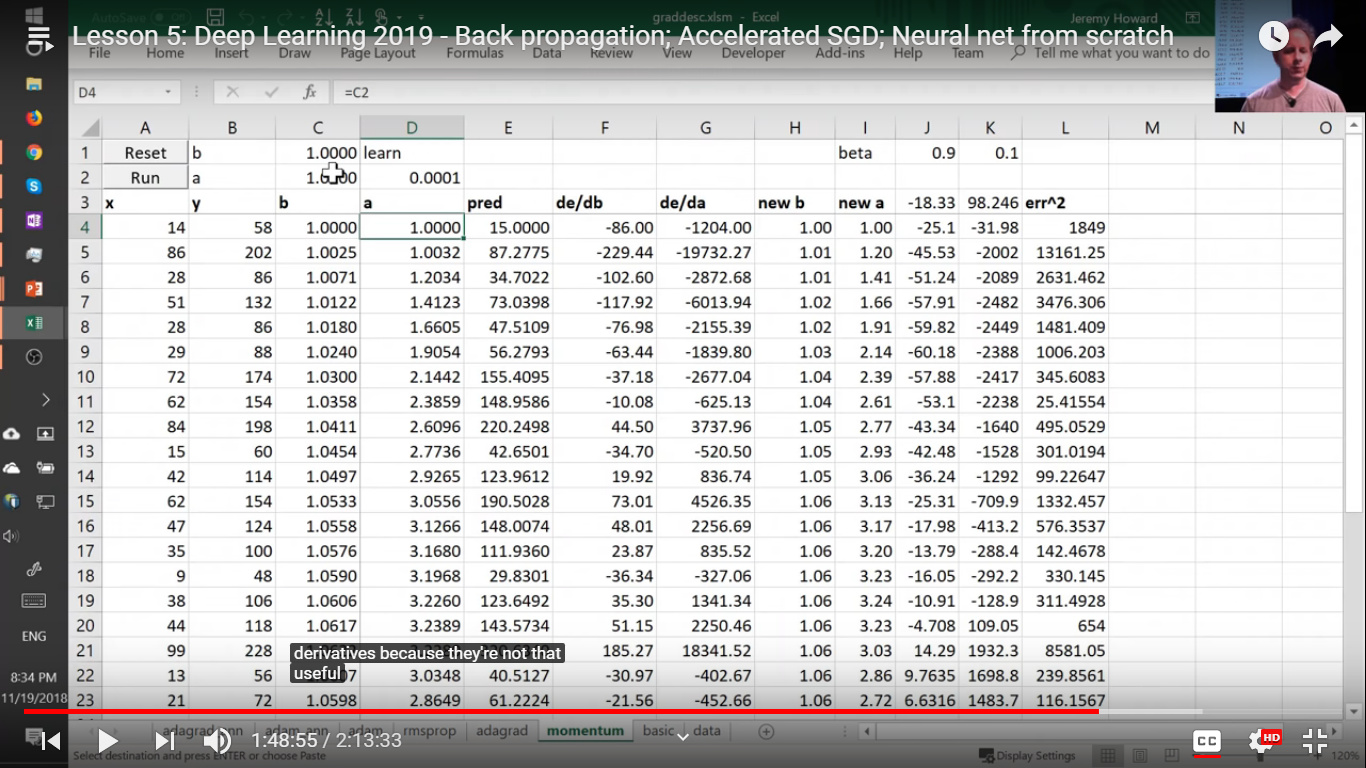
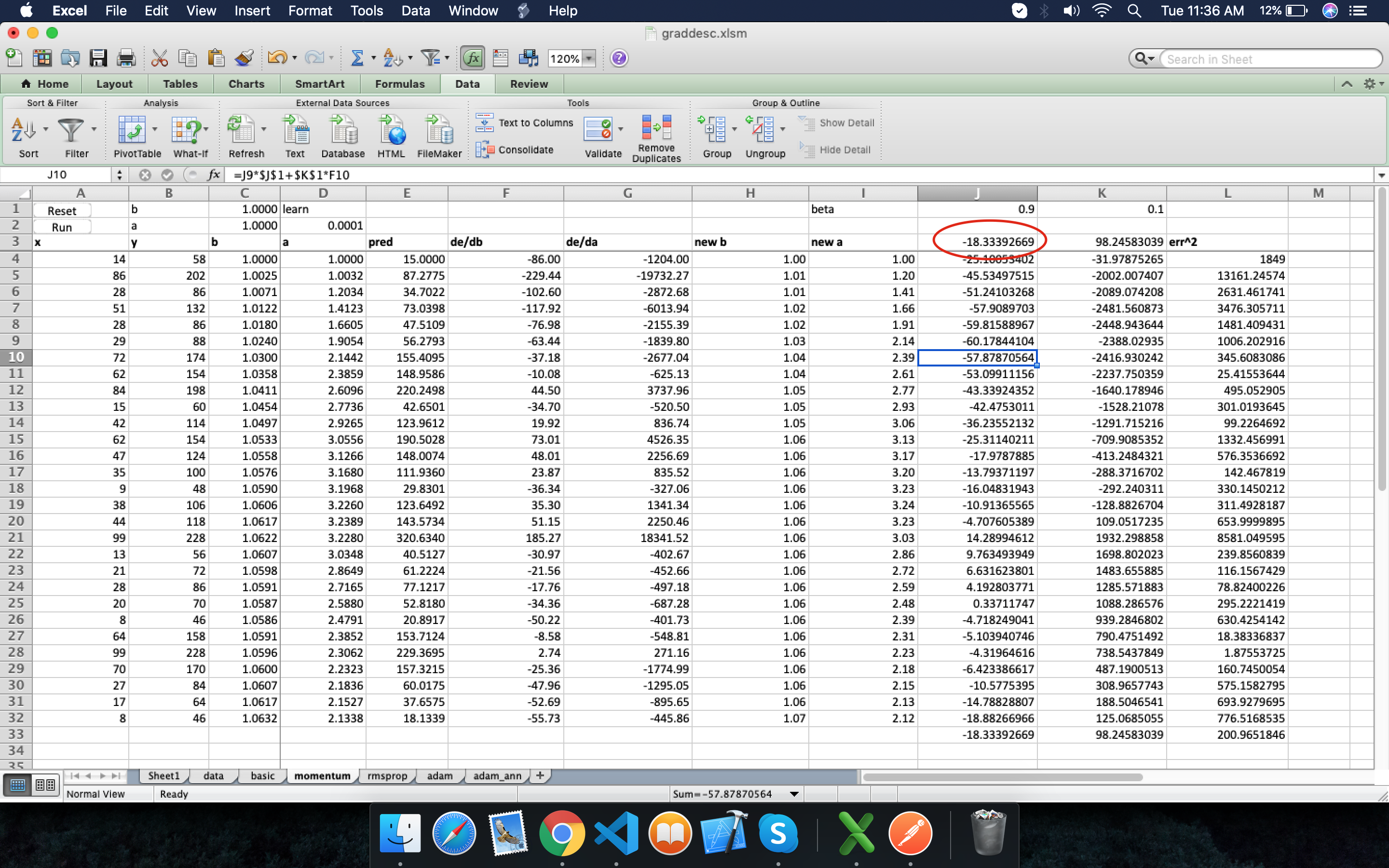
at 1:48:55 mark of Lesson 5 video, how are J3, K3 cell values chosen initially for the first time? Here they are -18.33,98.246 but what were their values initially?
Hi, I have a question on optimisers. specifically i don’t get how we are getting the exponentially weighted average’s initial value from… the other ones goes back to preceding and multiply by 0.9(momentum constant) plus with gradient of the current time step.(Correct me if i am wrong on this one…)
But the initial value as i pointed on the excel cell does it appear randomly or how?
If anybody is having trouble to run custom networks, make sure you are passing a data loader (e.g. data.train_dl) to your update function. If you mistakenly pass a dataset (e.g. data.train_ds) you might get a error such as:
RuntimeError: Expected object of backend CPU but got backend CUDA for argument #2 ‘mat2’
This happened to me a couple of times and I solved it by checking lesson’s notes.
I was trying to implement the collaborative filtering notebook in Google Colab, with the original movielens-100k dataset. But whenever I am trying to run this line “movie_bias=learn.bias(top_movies,is_item=True)”
I am getting an error You’re trying to access an item that isn’t in the training data. If it was in your original data, it may have been split such that it’s only in the validation set now.
TypeError: embedding(): argument ‘indices’ (position 2) must be Tensor, not NoneType
Can someone please help me where I am going wrong and how to implement it correctly?
Thanks in advance.
I similarly ran into this issue and it looks like it’s based on the weight / bias initialization. This blog post goes it into more detail and explains the PyTorch implementation:
It looks like it’s using a more complex initialization pattern (Kaiming initialization) but based on the PyTorch docs:
During the estimation of the gradient, why is the 0.01 added on the intercept instead of adding it to the input prior multiplying with the slope? (f((x+0.01)a + b) - f(xa+b))/0.01
Hi vthommeret Hope all is well!
I read your post it was informative and concise.
I added this line from pathlib import Path to avoid a Config error on google Colab
I ammended this line self.lin = nn.Linear(784, 10, bias=True).cuda() to avoid this error RuntimeError: Expected object of device type cuda but got device type cpu for argument #1 'self' in call to _th_addmm
Great post!
Cheers mrfabulous1