I believe it’s 5000(vocab_size) x 32(Embeddings for each unique word).
I am also getting utmost 88%. One thing to note is, I am using weights from glove website not the pre processed ones. Need to try if I can reproduce the accuracy with preprocessed ones although I do not think that should make a difference.
Even when using 1D conv, you would still have [Size] x [Filters] parameters which needs to be flattened out. Where size in the imdb example is 500.
I was getting 0.83 accuracy result until I started the embedding layer as being trainable, and then set it to non-trainable after a couple of epochs. And then I could get the same results as Jeremy around 0.90 percent. You can try this to see if it improves your result.
1 Like
try starting the embedding layer as being trainable, and then set it to non-trainable after a couple of epochs. It improved my accuracy from 0.83 to 0.9. Nothing else did.
1 Like
Some questions from me:
-
I thought I understood during the class, but cant seem to figure out where 10304 parameters came from in Conv 1D layer.
-
Movie lens questions:
2.1. Do we download dataset from https://grouplens.org/datasets/movielens/?
2.2. The way we got top N movies does not seem right? count == highest # of times rated, not necessarily best rated?
2.3. What does a higher bias for a movie mean?
2.4. Using this CF, can we predict for new user/movie? But where do latent factors come from in that case?
2.5. For already present user, movie where user did not rate the movie, the rating prediction is close to zero, representing that user does not like the movie. Is this not a problem? Especially in sparse dataset? -
IMDB questions:
3.1. Simplified dataset - motivations: I understand why we need a fixed dimensions matrix for collaborative filtering but not sure of why we chose these parameters:
3.1.1. Reduce corpus to most frequent words - 5000 words. How did we come up with 5000 number?
3.1.2. All infrequent words replaced with word at 4999? How does this compare with replacing it with 0(tried but noticed not much difference, but still curious), which keras does by default in load()
– Note: Seems like there is a bug in keras implementation where it does this replacement only for the training set and not for validation/test set
3.1.3. Any one tried with bigger /shorter word length than 500? Here is the histogram of sizes
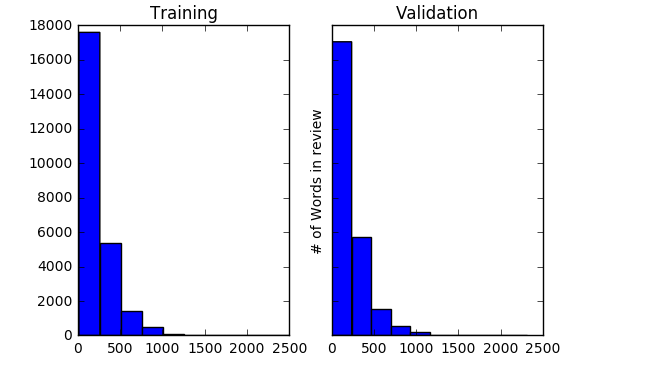


What are the best practices for choosing a vocab size?
In particular, I’m wondering what kind of NLP tasks work best with a limited vocab and what kind of problems may work better with even a full set?
Hi @jeremy
In lesson 4 notebook cell 57
get_movie_bias = Model(movie_in, mb)
movie_bias = get_movie_bias.predict(topMovies)
movie_ratings = [(b[0], movie_names[movies[i]]) for i,b in zip(topMovies,movie_bias)]
Here we are getting biases of the movies, but we are not using the model that we trained. This is just returning the bias at that movie index. This is not a trained model. Wouldn’t it return random bias as we are not using trained model to get the bias.
1 Like
This probably is a stupid question - but if I want to evaluate real movie reviews (paragraphs of text), how do I translate these text into word indexes so I can feed them into the model?
I’ve tried using keras.preprocessing.text.Tokenizer, but I quickly realised that it outputs irrelevant word indexes because they are different from the indexes from the imdb training word indexes…
Using NLP CNN as a replacement for fulltext matching?
Praise
Hi there, first @jeremy thankyou so much for making this course available. I have been lurking around the edges of Kaggle (and ML) for years unsure of finding my way in. I have tried many courses but never really stuck with them.
This course really takes the high priesthood out of it and has opened the door for me.
Question
Would it be possible to use an NLP CNN to do something similar to the following:
Build a model based on a dataset similar to the following (huge wine, liquor database)
product_id, keywords
- wine sparkling dom perignon oenotheque rose champagne bottle france 2003 ml 750 sparkling champagne champagne rose france champagne
- wine sparkling dom perignon oenotheque rose champagne bottle france 2004 ml 750 sparkling champagne champagne rose france champagne
- wine sparkling dom perignon oenotheque rose champagne bottle france 2005 ml 750 sparkling champagne champagne rose france champagne
Ask the model to predict the product_id based on the following text dom perignon oenotheque 2005
Apologies if this is off topic for the lesson, but I am trying out one of the homework assignments:
use your own text classification dataset
Hi @sravya8 here are few answers I could come up with,
- each word is an embedding of length 32 in a review.so, so for 1 filter the number of of weights is 532, which is 160, and we are using 64 such filters so 16064 = 10240 plus 64 biases which results to 10304
2.3) I think higher bias for a movie means that it was rated high universally by all kinds of users irrespective of their preferences
2.4) I think the ratings are normalized before training, so for a new user it will simply predict average rating of the movie I guess
Hi all,
In the create_emb() function in notebook 5, the pre-trained embeddings were divided by 3. Can anyone explain why ?
5 Likes
In the sentiment analysis example, I tried running a few more epochs using the single hidden layer model.
If I am reading these results correctly, the model achieved an astonishingly high performance (see below).
Is it really this easy to get to a ‘perfect’ model?
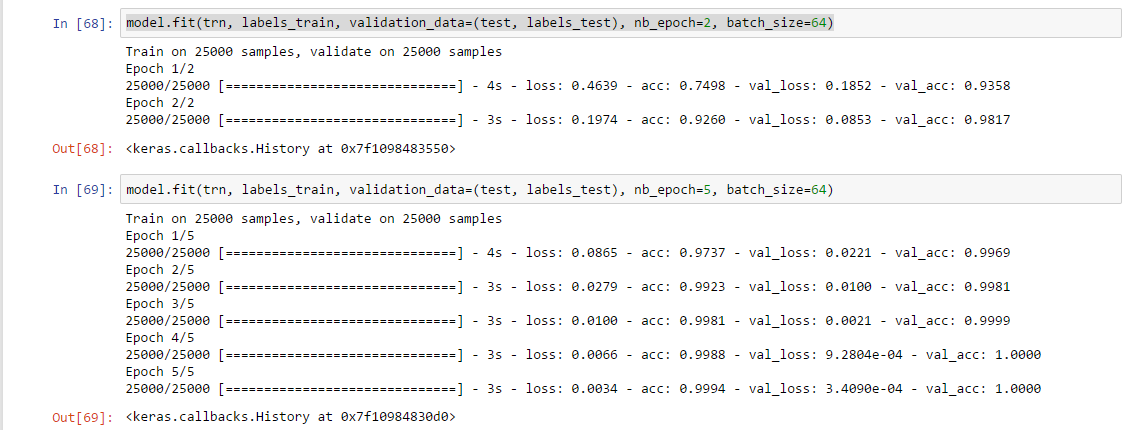
If this is the imdb dataset, it seems unlikely. Perhaps you’ve mixed your test and training sets together by mistake?
I did… 
Good catch
Oh well, at least it shows I tried to wrote the code myself… 
thanks for your help
1 Like
Ditto feedback from Iayla - that also worked for me.
I am using a mac (macOS Sierra) and am currently running the codes on the CPU instead of GPU.
For lesson 5, while trying to load the pre-trained word vectors, I am getting the following error :
OSError: /Users/kaustabh/test/data/glove/results/6B.50d.dat is not a regular file
Could anybody please point out, what’s wrong?
1 Like
Hi everyone,
Wondering if anyone else has run into this issue. Perhaps it’s because of Python 3, or some small change to the architecture in one of the libraries, but when I run
model.fit(trn, labels_train, validation_data=(test, labels_test), nb_epoch=2, batch_size=64)
I get this error:
Exception: ('The following error happened while compiling the node', GpuElemwise{RoundHalfToEven}[(0, 0)] ... '[GpuElemwise{RoundHalfToEven}[(0, 0)](<CudaNdarrayType(float32, matrix)>)]')
Googling around, it seems like the problem is with the round function being used in the theno backend. I’m not sure how or why this is popping up. I’m going to keep trying to solve this – in the meantime if anyone else finds themselves in a similar situation and figures it out, I’d love to know.
EDIT
Upgrading (at least in my case) appeared to resolve the issue:
pip install Theano==0.9
Has anyone ran into this issue. When I tried fitting the model, I ended up getting this error.
ImportError: (‘The following error happened while compiling the node’, Elemwise{Composite{EQ(i0, RoundHalfToEven(i1))}}(dense_2_target, Elemwise{Composite{scalar_sigmoid((i0 + i1))}}[(0, 0)].0), ‘\n’, ‘DLL load failed: The specified procedure could not be found.’, ‘[Elemwise{Composite{EQ(i0, RoundHalfToEven(i1))}}(dense_2_target, <TensorType(float32, matrix)>)]’)
I never had any issues in the past. Any idea what happened?
Is there a way to assign more weight to some specific word filters than just taking word filter randomly? If yes, would it be a smart choice, or the CNN will learn to capture the right ‘weight’ of words in order to predict the label (i.e. positive vs negative reviews). Think of that as pointing the model to pay more attention towards specific words used together, as they reveal the meaning of the review ( think of a model trying to label positive versus negative reviews) more than all the other words of the paragraph.
My intuition is that adding weights ‘manually’ could be useful when these words, for whatever reason, are not so common in the reviews we are trying to learn. Thus, the model cannot learn the pattern. Yet, we know that if these words are written together they have a pos/neg meaning.
For example, there is a phrase in Italian meaning, more or less, ‘going well’. If you take a pre-trained word vector model, it’s hard to associate them to negative feeling. However, often it is used in a sarcastic way meaning the opposite of ‘going well’.
Would a CNN learn this?