Hi guys,
During the fasi.ai course Lesson 5 https://youtu.be/CJKnDu2dxOE at 1:30:30 he suggest to try to create his own Linear cald My_Linear for example.
To better understand how fast.ai work I tried.
class My_layer(nn.Module):
__constants__ = ['bias']
def __init__(self, in_features, out_features,bias=True):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.Tensor(out_features, in_features))
self.bias = Parameter(torch.Tensor(out_features))
self.reset_parameters()
@weak_script_method
def forward(self, input):
y_hat = input@self.weight.t()
y_hat = y_hat+self.bias
return y_hat
def reset_parameters(self):
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in)
init.uniform_(self.bias, -bound, bound)
class My_layer(nn.Module):
__constants__ = ['bias']
def __init__(self, in_features, out_features,bias=True):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.Tensor(out_features, in_features))
self.bias = Parameter(torch.Tensor(out_features))
self.reset_parameters()
@weak_script_method
def forward(self, input):
y_hat = input@self.weight.t()
y_hat = y_hat+self.bias
return y_hat
def reset_parameters(self):
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in)
init.uniform_(self.bias, -bound, bound)
model = Mnist_Logistic().cuda()
def update(x,y,lr):
wd = 1e-5
y_hat = model(x)
# weight decay
w2 = 0.
for p in model.parameters(): w2 += (p**2).sum()
# add to regular loss
loss = loss_func(y_hat, y) + w2*wd
loss.backward()
with torch.no_grad():
for p in model.parameters():
p.sub_(lr * p.grad)
p.grad.zero_()
return loss.item()
losses = [update(x,y,lr) for x,y in data.train_dl]
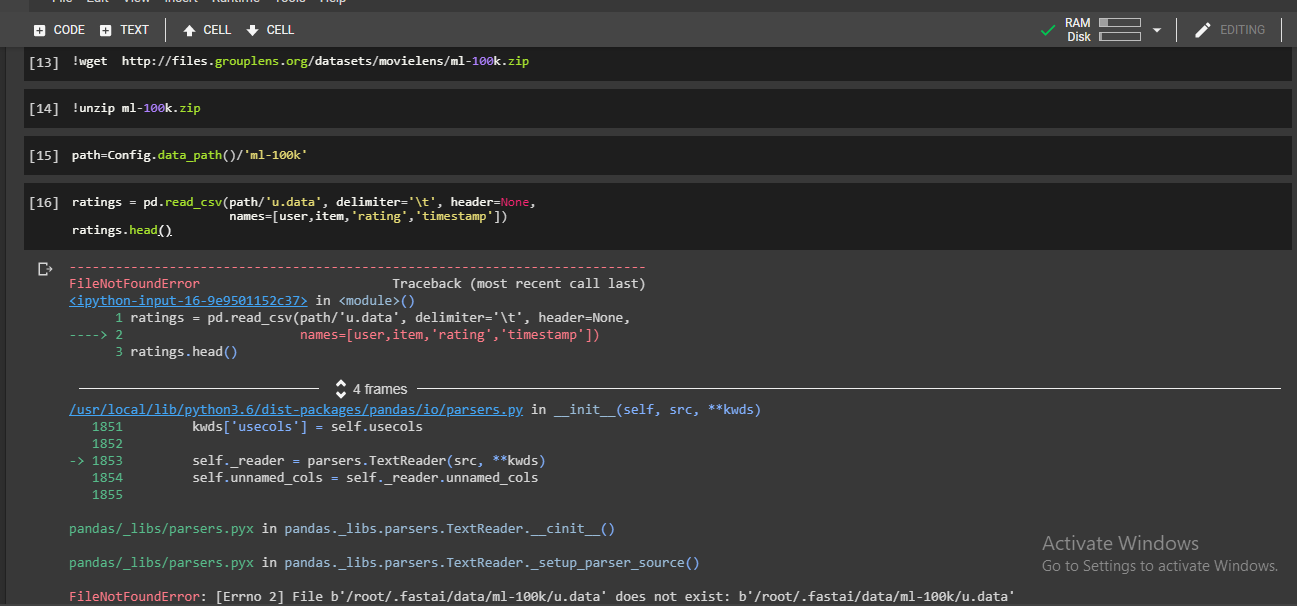
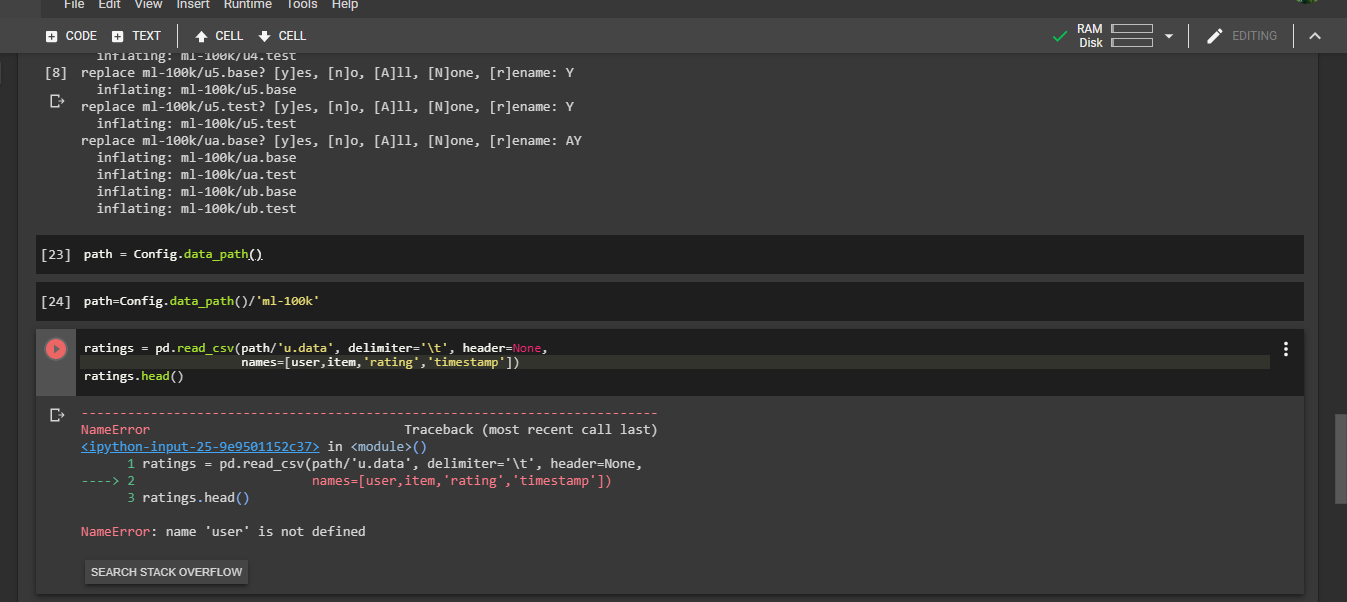
And I have this error
Traceback (most recent call last):
File "/opt/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 677, in __del__
Traceback (most recent call last):
File "/opt/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 677, in __del__
self._shutdown_workers()
self._shutdown_workers()
File "/opt/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 659, in _shutdown_workers
File "/opt/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 659, in _shutdown_workers
w.join()
File "/opt/anaconda3/lib/python3.7/multiprocessing/process.py", line 138, in join
w.join()
File "/opt/anaconda3/lib/python3.7/multiprocessing/process.py", line 138, in join
assert self._parent_pid == os.getpid(), 'can only join a child process'
assert self._parent_pid == os.getpid(), 'can only join a child process'
AssertionError: can only join a child process
What I understood it is that the weight are normalize during the init part and during the training (forward) the weight are updated.
I had an error before (tensor size mismatch) but it was because I forgot to transport self.weight.
But then this error happen but I don’t understand what I missed.
Thanks for your help.