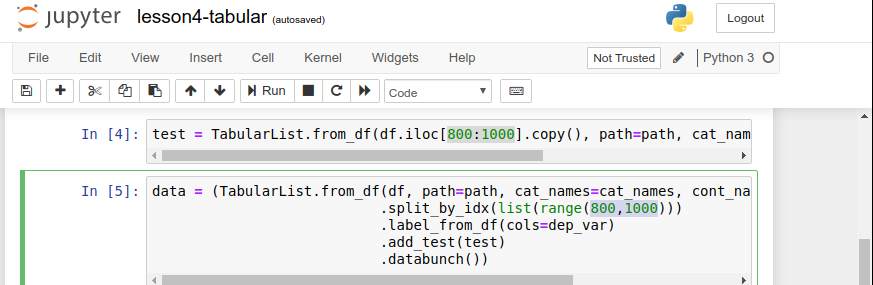
From the Lesson 4 section on Tabular Data preparation, is there an error when creating the test and validation sets?
The test set is created with the following code:
df.iloc[800:1000]
As I understand that, it is selecting lines 800 - 1000 from the df object and setting them as the test set.
In the next cell, the code to create the validation set is:
.split_by_idx(list(range(800,1000))
Is that not selecting the same data for the test and validation sets?
If you print out the data object, the validation and train sets look identical (photos below):