Me thinks this is taken care of by the fact that ‘an hour’ is ‘_an’,’_hour’ the starts follow each other the ‘anatinus of’ is split as ‘_an’, ‘at’,‘inus’,’_of’, but how I have no clue.
1 Like
I just cant get to an intuition as to why you would select the approach to concatenate a string in this example problem. I know Jeremy said that “you just need to give the model information somehow”. Surely giving the model the two strings that are being compared as two seperate strings would be better? It just seems so unreliable to ask the model to figure out that the score is a measure that is comparing the strings between TEXT1: ____ and TEXT2: ___. It obviously does figure it out but it is not something I would know to choose.
1 Like
So I have this exact same feeling. However I have humbly decided that I will accept this as just true …for now. I will not give up the dream that I will uncover the next great architecture where this type of input makes much more sense…just parking it for now so that I can get the basics right ha
On a more technical note, in the subsequent notebook Iterate like a grandmaster! | Kaggle Jeremy actually uses a different approach using separator tokens that Transformer models are more “used to” interpreting.
Interestingly, I have found this is how a lot of these larger models work. Like the T5 model (now almost outdated, can find on Huggingface) works this way. Under the hood, you are mashing a prompt and some example text together, separated by some token the model knows, into one array/list and with that the model generates an answer. Very weird for a “human” analyzing it though ![]()
EDIT: for some reason this isn’t getting linked as a reply, but this was in response to @Baskoes
3 Likes
When I submitted to Kaggle, it gave me this error:
Submission Scoring Error: Your notebook generated a submission file with incorrect format. Some examples causing this are: wrong number of rows or columns, empty values, an incorrect data type for a value, or invalid submission values from what is expected.
When I look at the submission.csv, I see brackets around the prediction score.
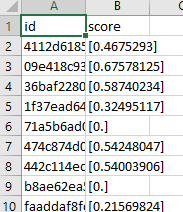
I think this is the reason why I am getting this error. Can anyone help me how to take the brackets off using this code as base?
import datasets
submission = datasets.Dataset.from_dict({
‘id’: test_ds[‘id’],
‘score’: preds
})
#submission = pd.DataFrame({‘id’: test_ds[‘id’], ‘score’: preds})
submission.to_csv(‘submission.csv’, index=False)
I tried using panda, but it returns an error saying the data has to be one dimension. Thanks!!
2 Likes
spacy is one of the frameworks that allows you to build nlp pipelines for various tasks such as text classification, extracting entities (eg: person, money) from documents. It contains components such as tokenizer, parser, tagger, entity recognizer. More details here https://spacy.io/usage/facts-figures
fastai uses spacy tokenizer as default for ‘en’ text.
Spacy recently added a wrapper around transformers in order to use various models as part of nlp pipelines. More details https://explosion.ai/blog/spacy-transformers
4 Likes
A follow up to this question.
Q: ULMFiT approach has fine tuning the language model followed by training the classifier [1]. But in case of transformers shown in the notebook, we do not have this step. Why? Would fine tuning Masked Language Model specific to our dataset benefit from this step?
[1] From ULMFiT docs Text transfer learning – fastai
We got great results by directly fine-tuning this language model to a movie review classifier, but with one extra step, we can do even better: the Wikipedia English is slightly different from the IMDb English. So instead of jumping directly to the classifier, we could fine-tune our pretrained language model to the IMDb corpus and then use that as the base for our classifier.
3 Likes
This probably is a trivial question, but has anyone been successful running " Getting started with NLP for absolute beginners" locally?
I’m struggling with the local setup and dependencies. So far I listed the below:
aiohttp==3.8.1
aiosignal==1.2.0
argon2-cffi==21.3.0
argon2-cffi-bindings==21.2.0
asttokens==2.0.5
async-timeout==4.0.2
attrs==21.4.0
backcall==0.2.0
beautifulsoup4==4.11.1
bleach==5.0.0
certifi==2021.10.8
cffi==1.15.0
charset-normalizer==2.0.12
datasets==2.2.1
debugpy==1.6.0
decorator==5.1.1
defusedxml==0.7.1
dill==0.3.4
entrypoints==0.4
executing==0.8.3
fastjsonschema==2.15.3
filelock==3.7.0
frozenlist==1.3.0
fsspec==2022.3.0
huggingface-hub==0.6.0
idna==3.3
importlib-resources==5.7.1
ipykernel==6.13.0
ipython==8.3.0
ipython-genutils==0.2.0
ipywidgets==7.7.0
jedi==0.18.1
Jinja2==3.1.2
jsonschema==4.5.1
jupyter==1.0.0
jupyter-client==7.3.1
jupyter-console==6.4.3
jupyter-core==4.10.0
jupyterlab-pygments==0.2.2
jupyterlab-widgets==1.1.0
kaggle==1.5.12
MarkupSafe==2.1.1
matplotlib-inline==0.1.3
mistune==0.8.4
multidict==6.0.2
multiprocess==0.70.12.2
nbclient==0.6.3
nbconvert==6.5.0
nbformat==5.4.0
nest-asyncio==1.5.5
notebook==6.4.11
numpy==1.22.3
packaging==21.3
pandas==1.4.2
pandocfilters==1.5.0
parso==0.8.3
pexpect==4.8.0
pickleshare==0.7.5
Pillow==9.1.0
prometheus-client==0.14.1
prompt-toolkit==3.0.29
psutil==5.9.0
ptyprocess==0.7.0
pure-eval==0.2.2
pyarrow==8.0.0
pycparser==2.21
Pygments==2.12.0
pyparsing==3.0.9
pyrsistent==0.18.1
python-dateutil==2.8.2
python-slugify==6.1.2
pytz==2022.1
PyYAML==6.0
pyzmq==22.3.0
qtconsole==5.3.0
QtPy==2.1.0
regex==2022.4.24
requests==2.27.1
responses==0.18.0
Send2Trash==1.8.0
sentencepiece==0.1.96
six==1.16.0
soupsieve==2.3.2.post1
stack-data==0.2.0
terminado==0.15.0
text-unidecode==1.3
tinycss2==1.1.1
tokenizers==0.12.1
torch==1.11.0
torchaudio==0.11.0
torchvision==0.12.0
tornado==6.1
tqdm==4.64.0
traitlets==5.2.1.post0
transformers==4.19.2
typing_extensions==4.2.0
urllib3==1.26.9
wcwidth==0.2.5
webencodings==0.5.1
widgetsnbextension==3.6.0
xxhash==3.0.0
yarl==1.7.2
zipp==3.8.0
but running into:
ImportError:
DebertaV2Converter requires the protobuf library but it was not found in your environment. Checkout the instructions on the
installation page of its repo: https://github.com/protocolbuffers/protobuf/tree/master/python#installation and follow the ones
that match your environment.
is there something like requirements.txt for this repo?
installing protobuf may help: pip install protobuf
For more information on Huggingface transformers I would highly recommend giving their awesome course a try:
7 Likes
Personally I found it difficult to intutive understanding of transformer architechture till I got to this post from peltarion.
Coupling this with the annotated transformer v2022, would get a fair idea of the inner workings.
After these, this book from Hugging Face team, opened up new understanding of concepts, which I didn’t have a understanding of.
6 Likes
A course on top of this course!
Q: During today’s lecture, if I recall correctly Jeremy mentioned that ULMFiT would perform better than the typical Transformer for long formed documents. Does anyone know why that is (or perhaps I misunderstood him) ?
4 Likes
From what I understood, the transformer based architectures loads the entire document into the GPU at once, while ULMFiT can do that in parts. So, it requires lesser memory and can learn faster.
3 Likes
I didn’t doubt that the underlying concepts like tokenisation would be the same. I was wondering if there are alternative or clever ways to learn word vectors/embeddings for these (diagnostic) codes since we don’t have an equivalent text corpus like Wikipedia in such a case.
I’m trying to run the “Getting Started with NLP…” Kaggle notebook on Paperspace, but I’m having issues with toks.tokenize, not sure what’s causing an error for deberta-v3-small:
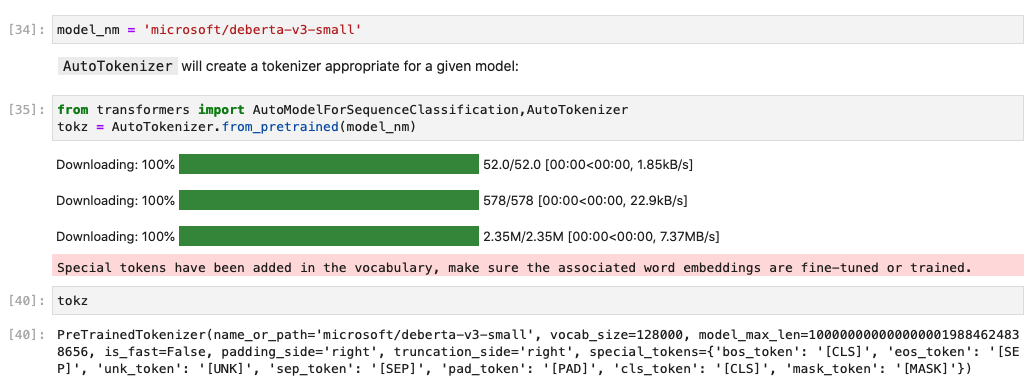
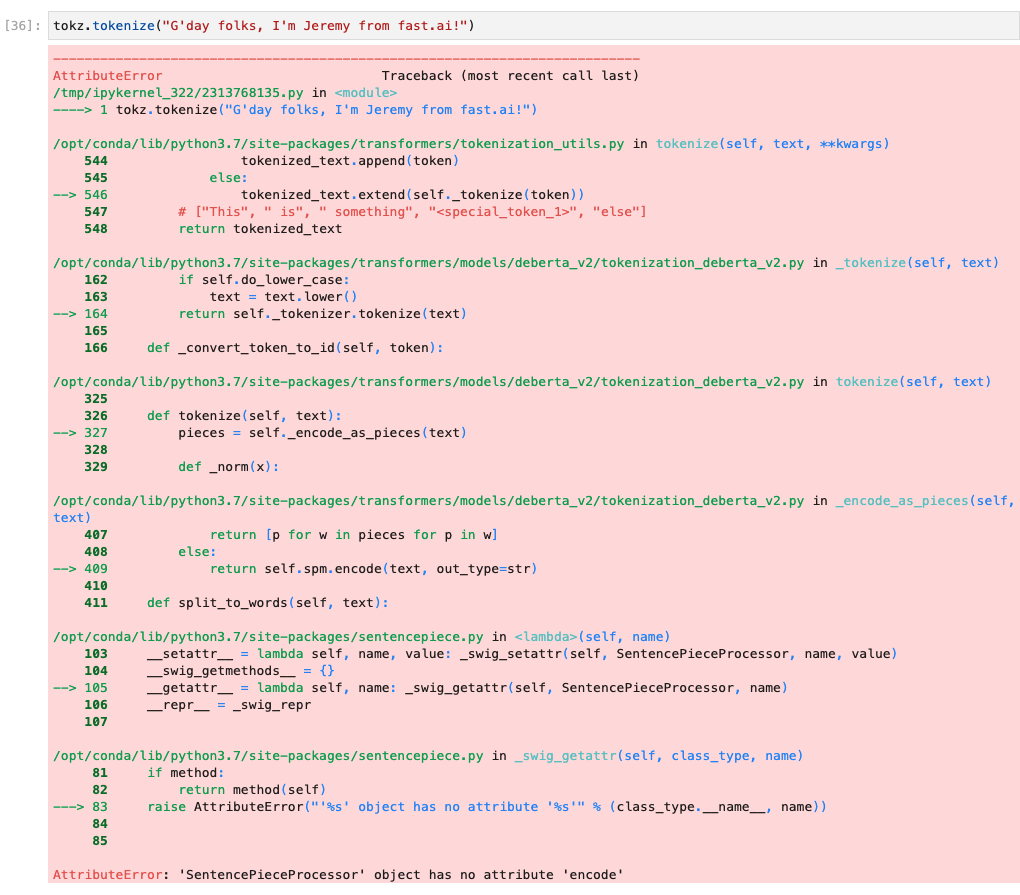
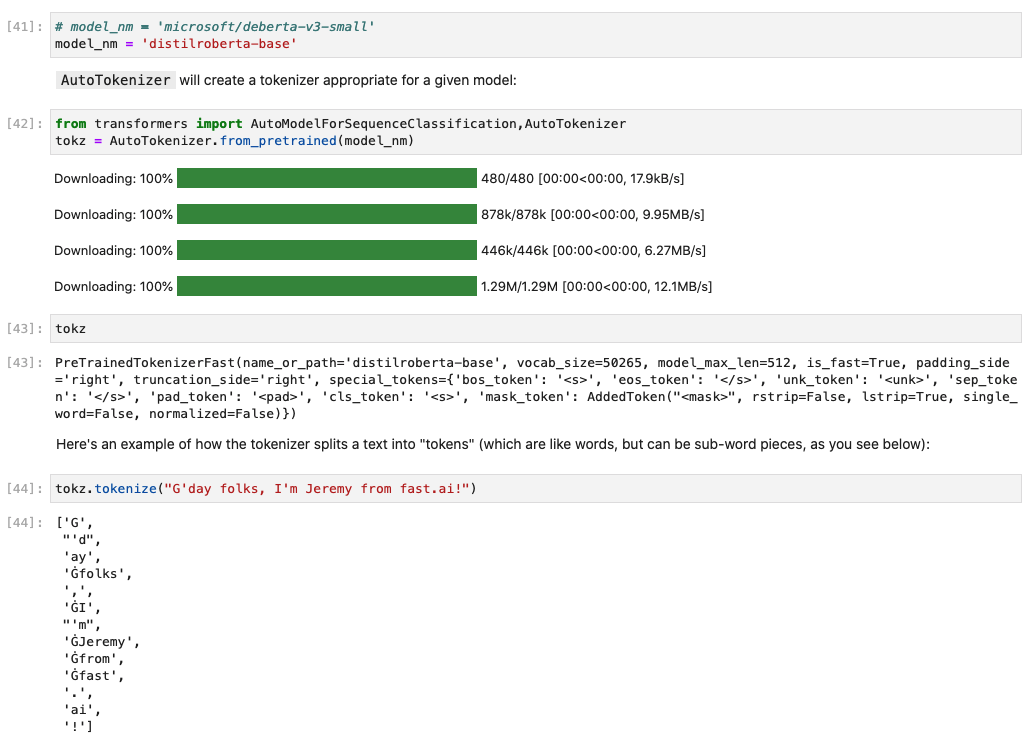
Changing the model to distilroberta-base doesn’t throw an error like above but adds Ġ and other spurious characters to the tokenization:
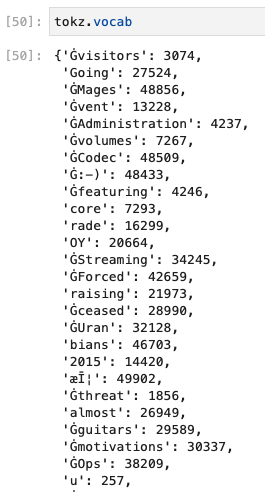
1 Like
I had this same error. I have to pip install the sentencepiece library when I first open a notebook in a new Paperspace session and then restart the kernel. Installing without restarting the kernel won’t work
2 Likes
I wouldn’t recommend doing that at this stage. There’s very limited upside to studying the details of architectures for most people for most situations. It’s fun and interesting, but is only needed if you start building custom code that interacts with the parameters inside the model.
3 Likes
That might turn out to be true - but then that wouldn’t be a classification model! Since classification models are so widely available and easy to use, and work so similarly between image and nlp models, I’d start there if possible. Generally my experience is that more custom approaches are not necessarily better, but they are more work!
If you want to try the separate-strings approach, have a look at “sentence transformers”, which can do this. Remember though you’ll also need a way to use the “context” field.
3 Likes
It’s what humans do though, right? When we do q&a we just have a stream of tokens coming into our brain (we’ll initially it’s stuff we see or hear, but we recognise the individual words that are said), and things like pauses, inflections, or changes of speaker indicate where sections start and stop.
5 Likes
Yes generally that gives an additional improvement.
1 Like