Shouldn’t num_labels be 5 [0, 0.25, 0.5, 0.75, 1] instead of 1? Is n’t the target a categorical or we consider this as a regression problem ?
model = AutoModelForSequenceClassification.from_pretrained(model_nm, num_labels=1)
Shouldn’t num_labels be 5 [0, 0.25, 0.5, 0.75, 1] instead of 1? Is n’t the target a categorical or we consider this as a regression problem ?
model = AutoModelForSequenceClassification.from_pretrained(model_nm, num_labels=1)
NLP is an area with huge opportunity for new businesses, but don’t companies with very large language models have an advantage?
Yeah I think since you are looking at correlation and higher value means higher similarity, regression may make more sense here…
In practice I have found that it was easier to translate the text I wanted to classifiy from german to english first and then use a pretrained english LM than using a german LM
Some of them go API/Hub route, providing tools rather than products. So still, could be a good opportunity. Also, there are more and more open-sourced models, like HF’s Big Science that is trained right now.
Pearson only makes sense with a regression task.
With that said, you could try to put this as a classification task and see how well your results fare on the LB. You could also use the predictions and thresholds to predict those 5 classes and see how that fares as well.
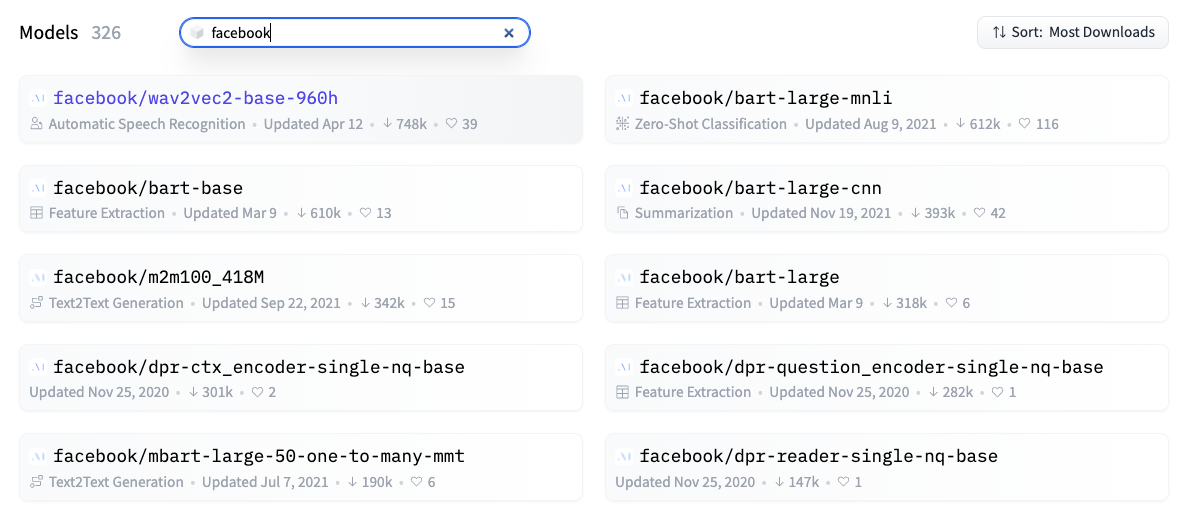
Are there any ‘best practices’ for choosing Hugging Face Transformers models for NLP when doing different projects, as the Hugging Face hub has 44,748 models.
So for example, should the general models be tried out first in general, and then domain-specific, etc?
Also, since not all are peer-reviewed, how can the ones that are reviewed be found easily on the Hugging Face Hub, without needing to go to each one and possibly checking whether they are reviewed, or not, etc - basically the different categories…
I think that a good starting point is to start with “official” models published by companies/research institutes. Also, you can order them by the number of downloads, and in this way, keep narrowing the scope.
Yeah - how do you check or filter this in Hugging Face Hub?
Frequently, number of downloads will do the trick.
Not quite clear on the ‘what should I have studied / understood’ from this lesson. Aside from the Kaggle notebook showcased in the lesson, what else would it be an idea to learn? And should we continue onwards and reach chapter 5 of the book now?
Since we’re talking about classification today … deberta and roberta are good starting points.
In general:
Okay I agree - but just thought if there was some way to first filter by the ‘official’ ones, it may have helped - and any other best practices besides filtering by number of downloads, descending.
Is it correct that Seq-2-Seq is both Encoder and Decoder? Like both parts?
I think one of the main things is to dive into some of the resources folks have posted here about transformers so you can understand what’s happening under the hood.
The content in tonight’s lecture was really trying to give an overview of how tokenization etc looks and works “in practice” on a “live” Kaggle challenge. As Jeremy noted, it’s SOTA stuff and not yet directly incorporated into fast ai.
Dive into the resources in this thread and play around with the models on HF model hub and you will have a great basis to begin making your own applications / fine-tuning existing models for your own purposes
Generally, my filter is to start by clearly understanding the task i’m trying to solve. Your best bet is to start with paperswithcode.com and figure out some general approaches for your problem. Once you’ve identified some models / architectures, then it’s a good time to head to the HF model hub and begin searching through applicable models.
Don’t go off model popularity in the first instance. Always start with a task-oriented approach. Understand your problem. Understand the constraints. Vitally, understand your features and the real-world context and dynamics they occur in.
What I tried (and will continue to as I have hit a large immovable wall of understanding) is to get the same result of this notebook (and the partner notebook to this one) but run with fastai instead of the HF trainer.
A good point! I would say that if you know for sure what kind of problem you have and already established some baseline, you may want to start picking architectures, but not earlier.
Like, let’s say you’re working on CV task. Then you can go with very basic resnet18/34 architecture without worrying too much about the state of the art. As you need to make sure that your data and target achievable. Like it was mentioned in the Drivetrain approach to data projects. When you have some working MVP, you can start iterating architectures. This approach definitely works for Kaggle, I would say. Also, it helped me multiple times in production and moving products from PoC into regularly working pipelines.
Hugging Face Transformers has the following resources, I thought I’d share them here ![]()
Came across this journal article:
HuggingFace’s Transformers: State-of-the-art Natural Language Processing
The book:
Natural Language Processing with Transformers: Building Language Applications with Hugging Face