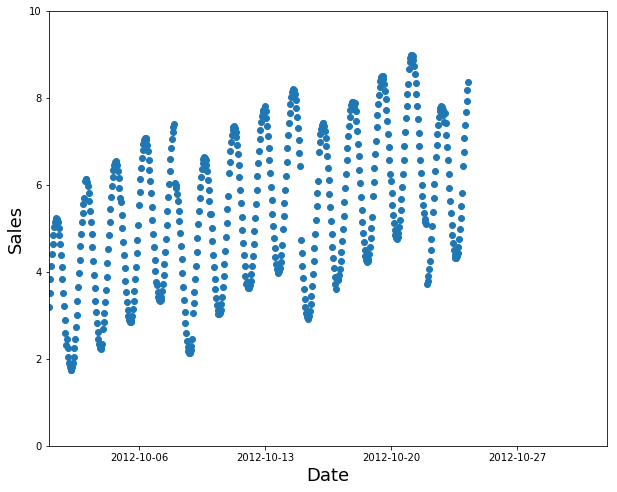
It’s explained in the linked article we’re discussing - you can’t really use cross-validation for something like testing against the last week here:
Cross-validation requires some way to randomly shuffle your data into multiple non-overlapping pieces which maintains the ability to test on out of distribution data.
True - that’s can be a useful approach. Personally I wouldn’t call that “cross validation” (since they’re overlapping subsets) but I guess I could see how it kinda fits that pattern.
While Jeremy builds and flies the F-16 Fighting Falcon plane (fast.ai), I am putting along on my homemade Wright brothers twin engines airplane, but I am proud of my baby. There are so many lessons learned when you code from scratch (without Jeremy’s notebooks)
Please ping me if you want to compare notebooks. I would like to see how you do it.
Here are a few highlights.
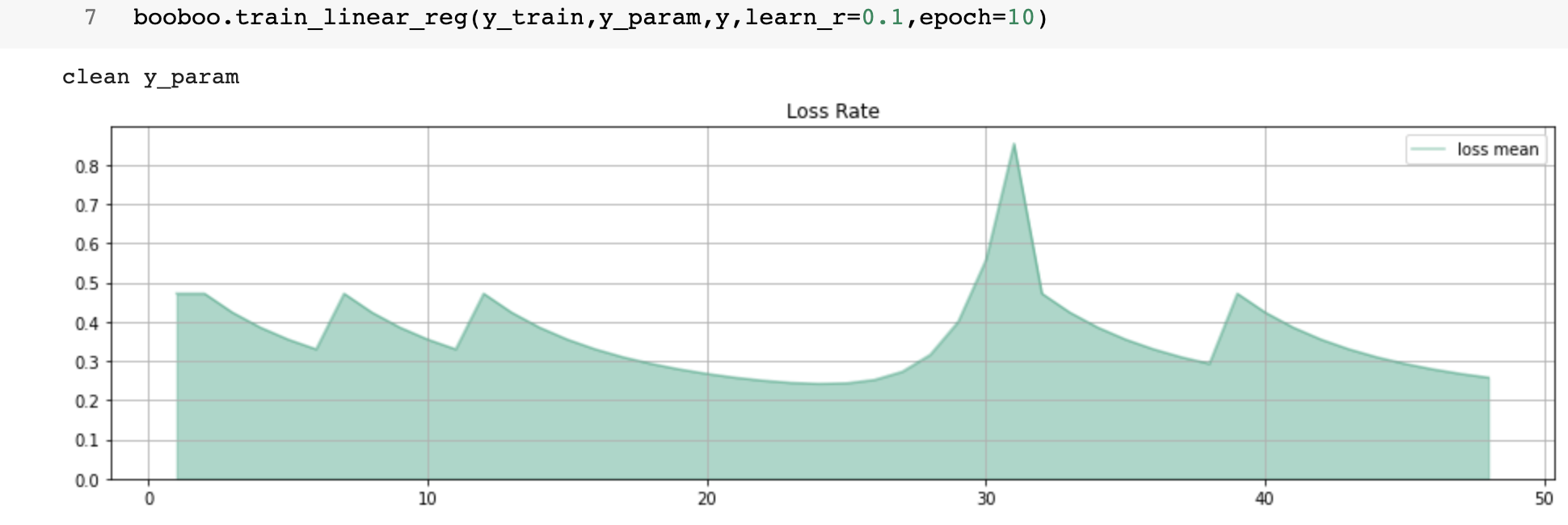
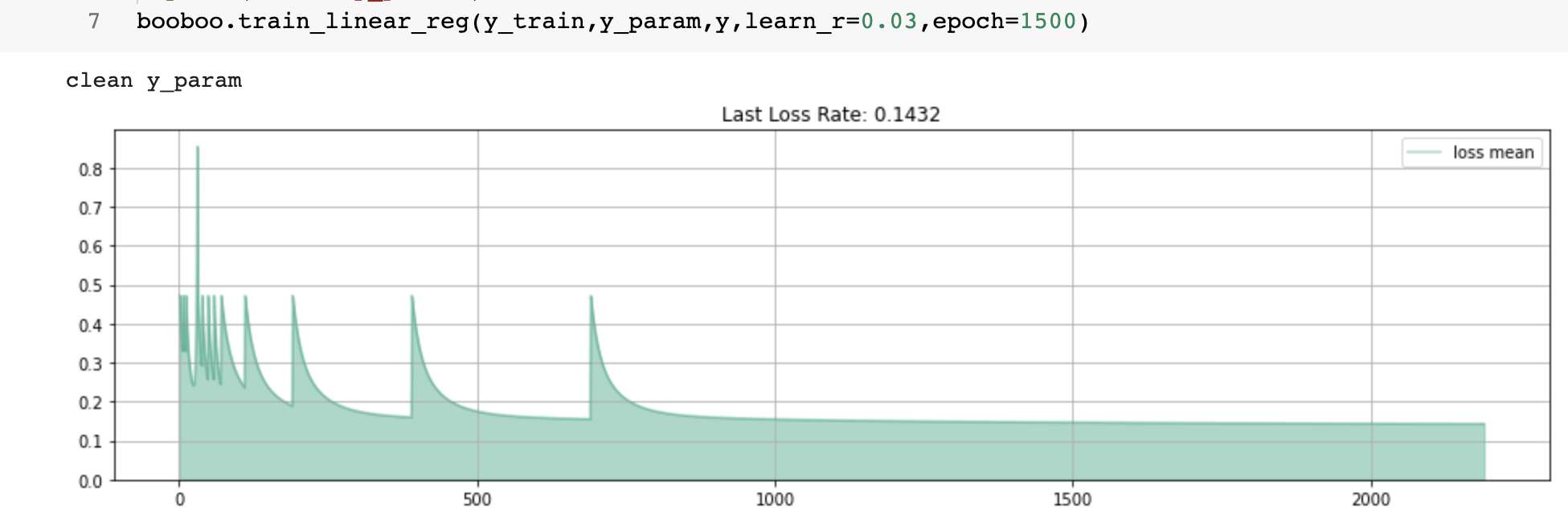
By the end of step #9, I have created the first train method for regression.
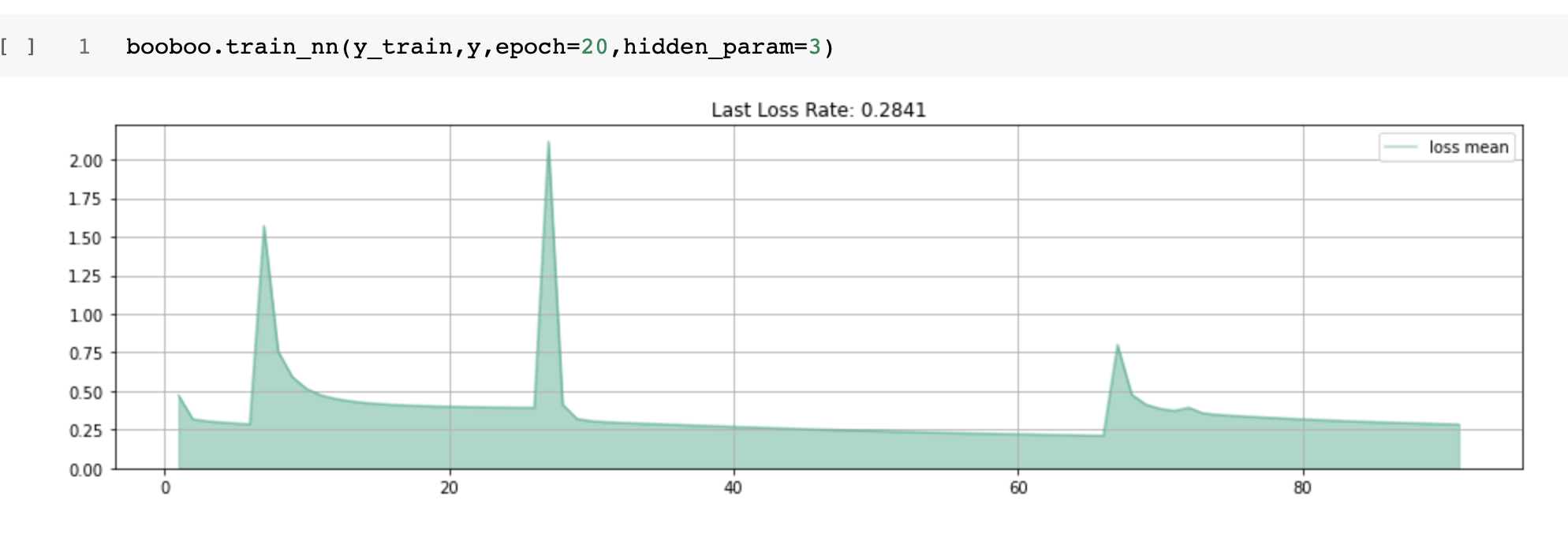
def train_linear_reg (self, y_train, y_param, y, learn_r=0.03, epoch=5):
I use the same “y_param” (or weights) and different " learn_r, and epoch." Images below show a collection of all runs, and every new run starts with a peak and lower loss rate.
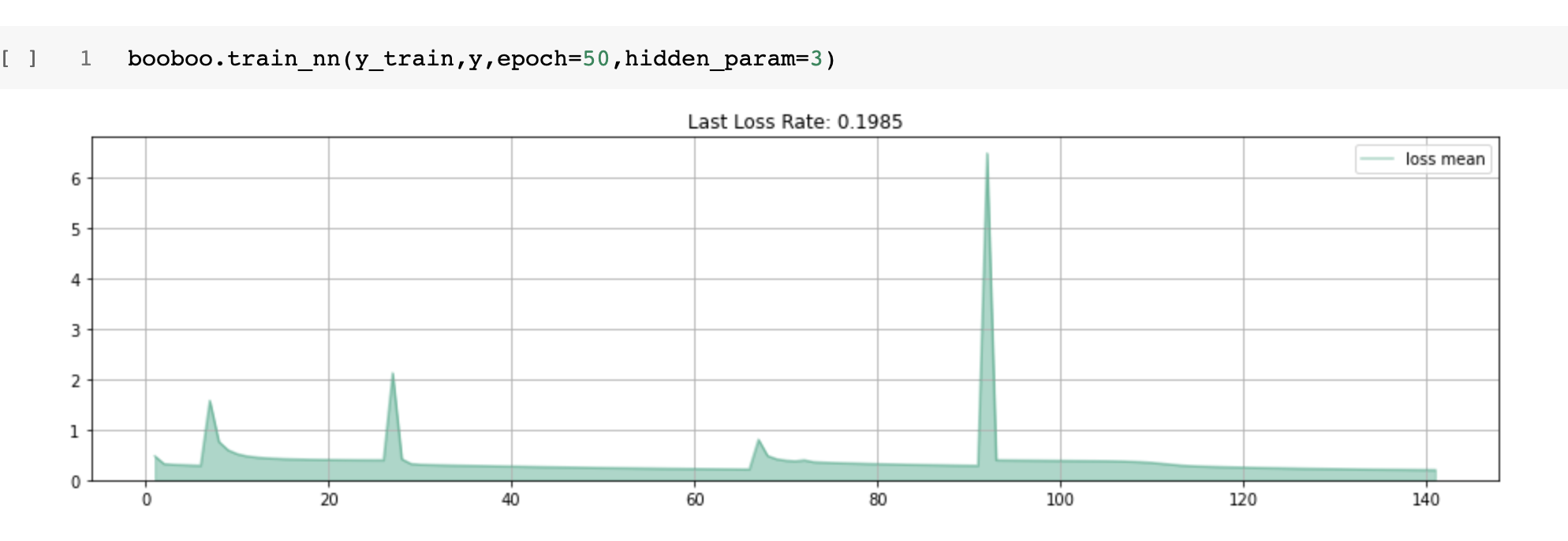
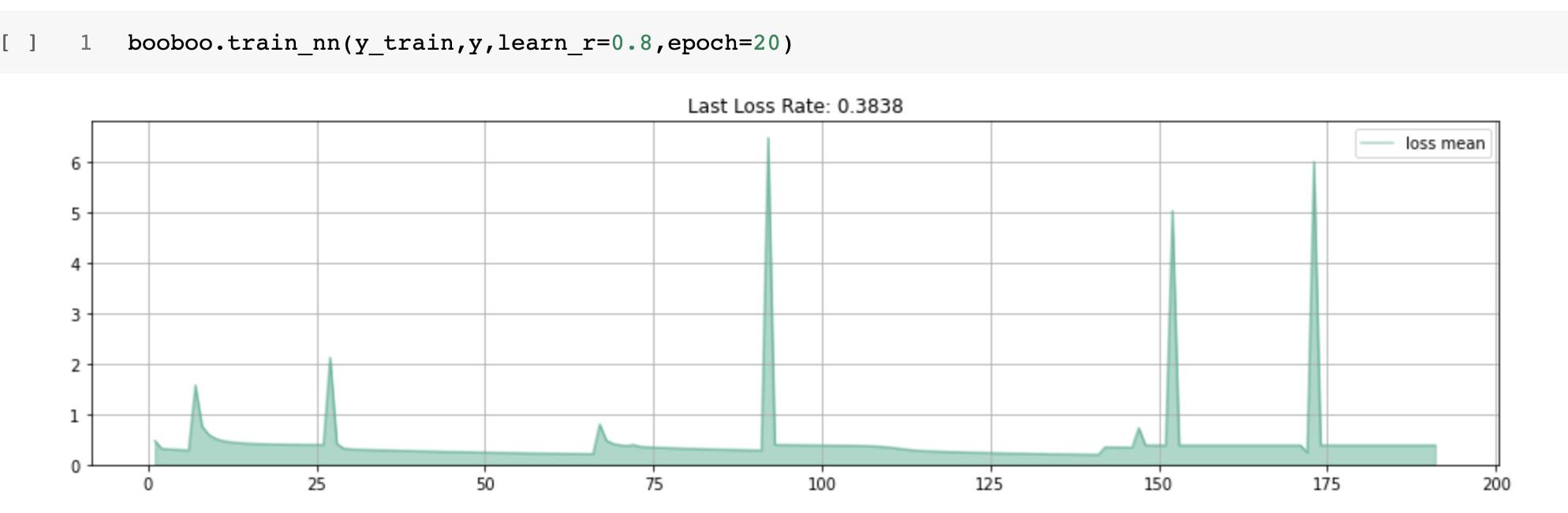
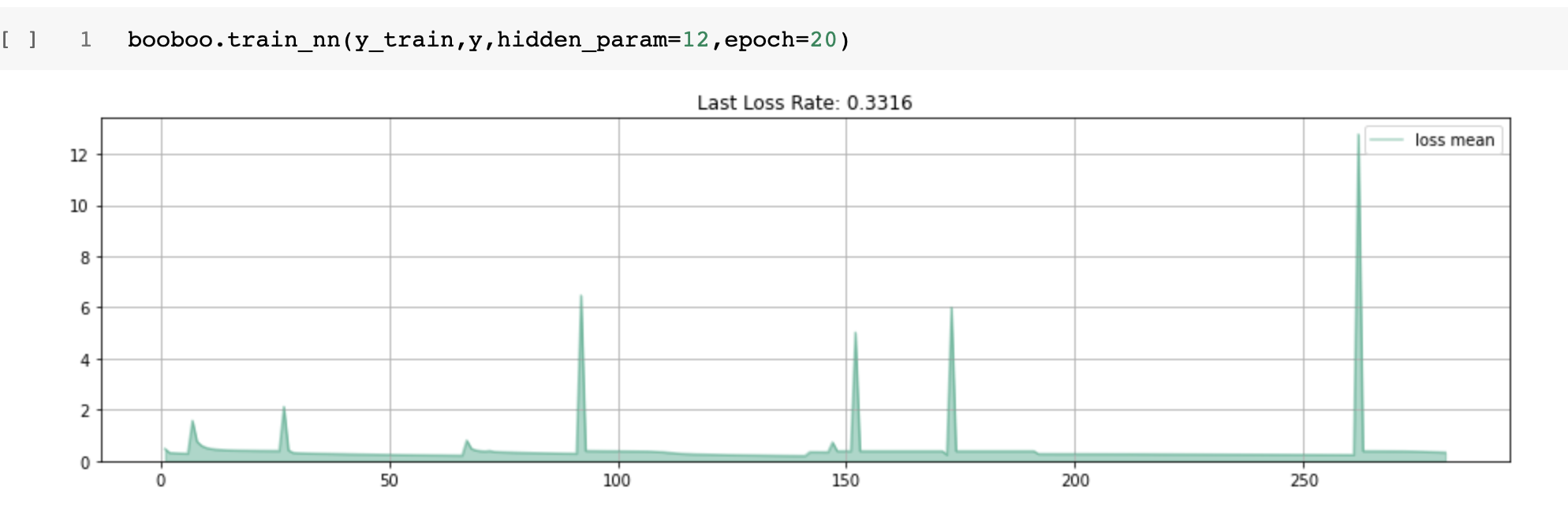
By the end of step #13, I had created the final train method. The only difference from the above method is the "self.predict_y_nn(y_train, y_param) and the new self.fetch_hidden_param(y_train, hidden_param)
def train_nn (self, y_train, y, learn_r=0.03, epoch=5, hidden_param=2):
I run it many times with different parameters. Images below show a collection of all runs, and every new run starts with a peak and lower loss rate.
Notice, it does not matter how many random parameters (hidden layers). Keep training with many epochs, and the error rate goes down.
I am running out of space on Kaggle and I can’t figure out how to remove old checkpoints mid train. Any advice? I assumed it has something to do in the trainer with callbacks but havent found the right setting.
For example, I want to remove checkpoint 500 to free space.
I use JupyterLab in Paperspace to run lesson 4 notebook. I encountered this error when importing kaggle.
ValueError: Error: Missing username in configuration.
I found the following approach solving this issue.
install kaggle
upload the kaggle.json file to the current working dir
run the following code
# The next two lines make a directory named kaggle and copy kaggle.json file there.
! mkdir ~/.kaggle
! cp kaggle.json ~/.kaggle/ # The next line change the permissions of the file.
! chmod 600 ~/.kaggle/kaggle.json
! kaggle datasets list
Old bump but this answer was very helpful. Basically with a few HuggingFace args you can save only the best/last model. Playing with these args you can save more/different combo of checkpoints:
The only tokenized and numericalized column in our data is the new input field we created. (Using the tok_func function I omitted here)
The other fields like context etc are still in text format.
When we pass in our train_dataset in the Trainer, we don’t specify the input field, we just pass in dds[train] which is the train split of our data.
So my question is,
How does the Trainer know specifically which field it should consider the input? Is it the same case where it expects the target to be called labels hence we should always called our input field inputs or it just checks for the numerical field and uses it as the input, or is there something I am missing somewhere?
I have been researching this question and finally found an answer! I will leave the answer here in case someone else has the same question as I did.
The answer is quite simple actually, in the HuggingFace ecosystem, when fine-tuning a pretrained transformer, we can check the names of the fields that the model expects in its forward pass using the tokenizer.
As you remember, we can automatically load the tokenizer of a model using the AutoTokenizer class
from transformers import AutoTokenizer
model_nm = "microsoft/deberta-v3-small"
tokenizer = AutoTokenizer.from_pretrained(model_nm)
We can then check what fields the models expect using the following code:
tokenizer.model_input_names
Which, for our example above, outputs several things including the input_ids field that we got after tokenizing. So basically after tokenization your inputs will have the fields required by the model.
Has anyone tried changing the default fastai tokenizer to use a subwords tokenizer instead of a word tokenizer like Spacy? If you have, where did you fit it in the ULMFit process?
Also, it’s taking so long to fit_one_cycle the language model on the IMDB dataset using google collab, about 2 hours and the model is still at 8%, is there any way to go faster?
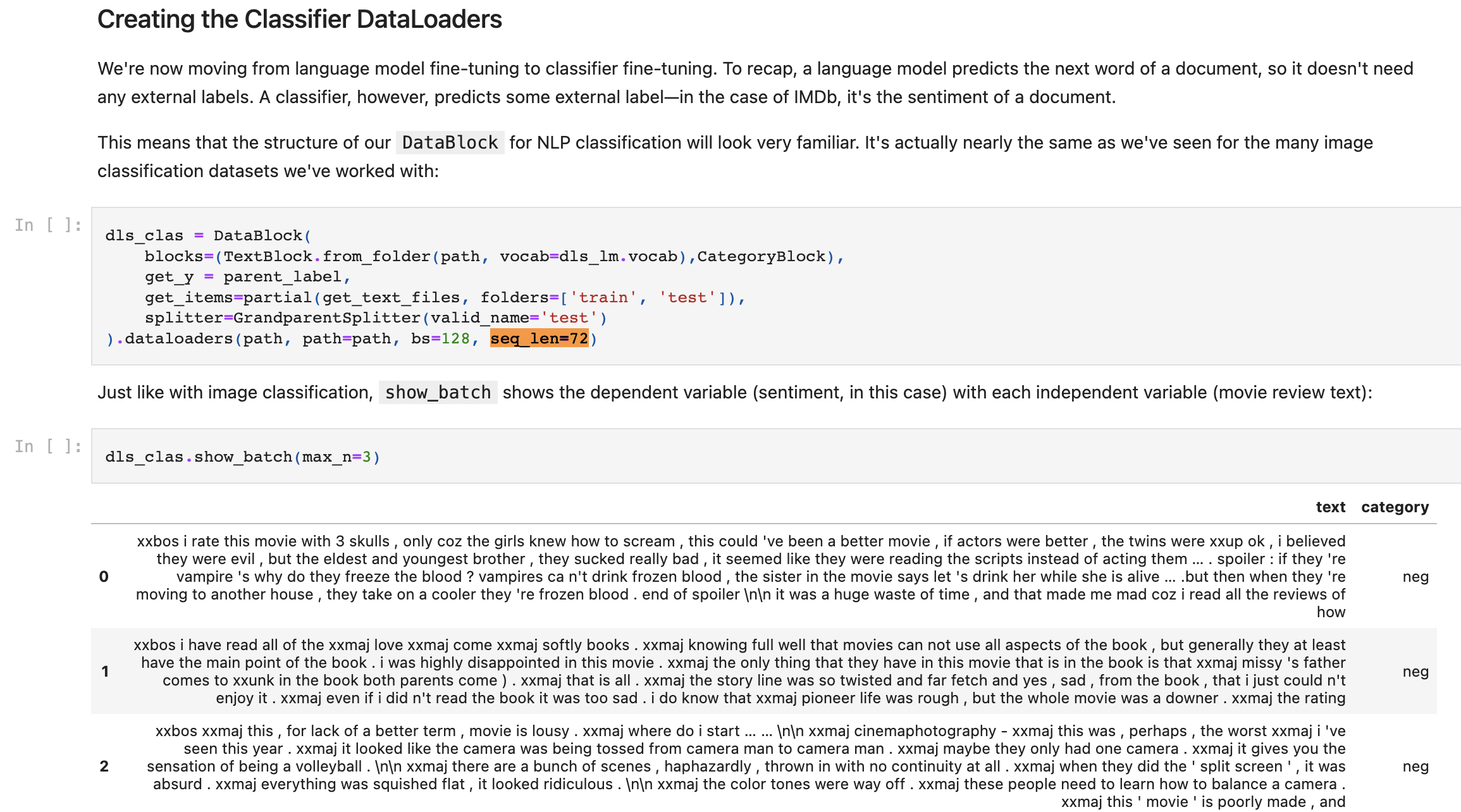
I have a question about the ‘seq_len’ in DataBlock.dataloaders() in the section of ’ Creating the Classifier DataLoaders’ from 10_nlp.ipynb
seq_len is set to 72, but in the result of the following show_batch(), each of the 3 documents has 150 tokens, not 72. (please see the screenshot below). Why is this?
@ns8wcny, I probably don’t have the knowledge to help, but just a tip… You’ll likely get a better response if you reduce the burden on readers to understand your question. i.e not having to guess where to hunt down the notebook you are referencing. A link to the full notebook wold be useful, plus code extracts and the output of code execution.