yep the Gradient Accumulation callback is pretty easy to use ![]()
2 Likes
We use data augmentation while working with images to increase accuracy and reduce overfitting. For text, are any techniques or algorithms to augment the input text?
1 Like
I’m trying to use the ULMFiT model based on FastBook for multi-class classification and build the learner to see precision and recall as follows:
learn = text_classifier_learner(dls, AWD_LSTM, drop_mult=0.5, metrics=[accuracy, FBeta(beta=1, average='micro'), Precision(average='micro')]).to_fp16()
But when I fine-tune using fit_one_cycle I see that all the metrics accuracy, precision, and f1 score are shown as the same as follows:

Am I missing something other than setting average=micro while defining the metrics for a multi-class problem?
If you are a Google Colab diehard fan, then here is the NLP lesson for Google Colab. (only a few libraries import before hands, no other changes)
Enjoy hacking.
1 Like
maybe I misunderstood something here. The notebook talks about Text Classification, the model is called AutoModelForSequenceClassification, but the predictions (clipped) sounds to be a number from 0 to 1. Isn’t this a regression?
EDIT: nevermind, I was missing the explication of this in the end of the video, the key here as far I understand is num_labels=1 that actually turns it to a regression problem.
1 Like
Linear Model and Neural Network from Scratch Challenge
![]() The big challenge is converting Jeremy’s spreadsheet to Python code independently.
The big challenge is converting Jeremy’s spreadsheet to Python code independently.
You may attend or watch session #4. Thus, you know how Jeremy recreates it step by step with Python, Pandas, and Numpy. That is OK, but for the challenge, you can’t use the “Linear Model and Neural Network from Scratch” Jupyter Notebook on Kaggle.
If Jeremy can do it on Exel, surely you (and I) can do it with Python. The below layout is a step-by-step challenge. Re-watching session #3 is allowed (but not session #4). It is OK to use Stackoverflow and any resource on the Net.
![]() WHY?
WHY?
- If you can do this, then you are Top Gun, i.e., you understand the core concepts of Neural networks, aka Deep Learning.
- The goal is NOT to write the most compact and elegant code, but it is for YOU to understand how to code it.
- …and because it is a fun brain teaser.
I am interested in your posted solution (I think we all do). I am almost done, full of Pandas and graphs everywhere.
Happy hacking.
4 Likes
Hi @duchaba, this is amazing!! ![]()
![]() I think I’m going to try this. Seems daunting actually, but I think definitely worth trying! Thanks for making this notebook and thanks for sharing!
I think I’m going to try this. Seems daunting actually, but I think definitely worth trying! Thanks for making this notebook and thanks for sharing!
1 Like
I tried the “NLP for beginners” and was able to submit fine. However, when working through “iterate like a grandmaster” I run into issues with generating predictions.
After I train my model and right before “Improving the Model” I want to make predictions and borrow the code from NLP for beginners. It seems that preds = trainer.predict(eval_ds).predictions.astype(float)causes an error because it is non-type. It seems like the model is training fine. I feel I am missing something basic after reviewing the documentation and trying some other solutions.
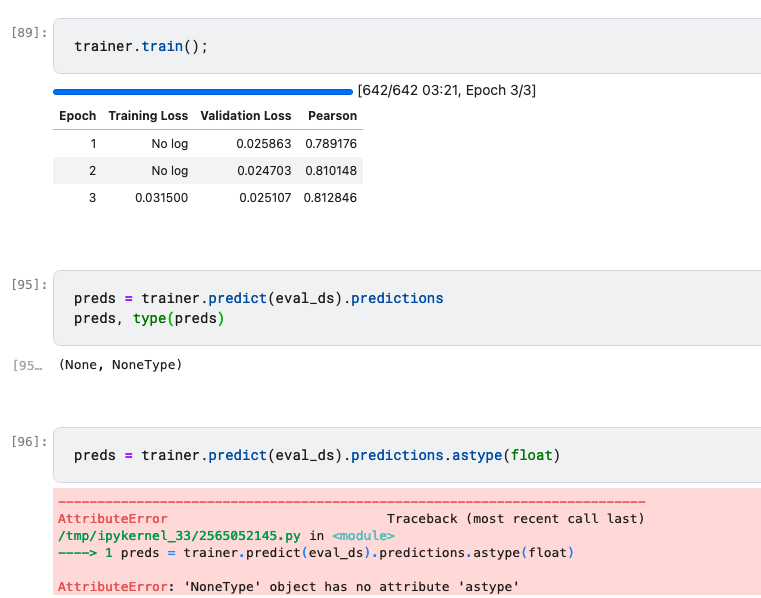
So in that notebook eval_ds was not processed in the same way as ds was. It also needs to be tokenized and such. I think you get None since the model was not applied since it didn’t see any token_ids in the dataset.
If you replicate the processing appropriately for the eval_ds it should work.
1 Like
Yep thats the issue. As I was comparing values it looked like everything done to ds was being done to eval_ds… but that was not the case.

1 Like
With the Getting Started with NLP for absolute beginners, when run on PaperSpace, did anyone run into this error:
‘SentencePieceProcessor’ object has no attribute ‘encode’
I have tried both pip install datasets and conda install -c huggingface -c conda-forge datasets, incase it is some module conflict.
The code comes to the sample tokenize text function and throws this error
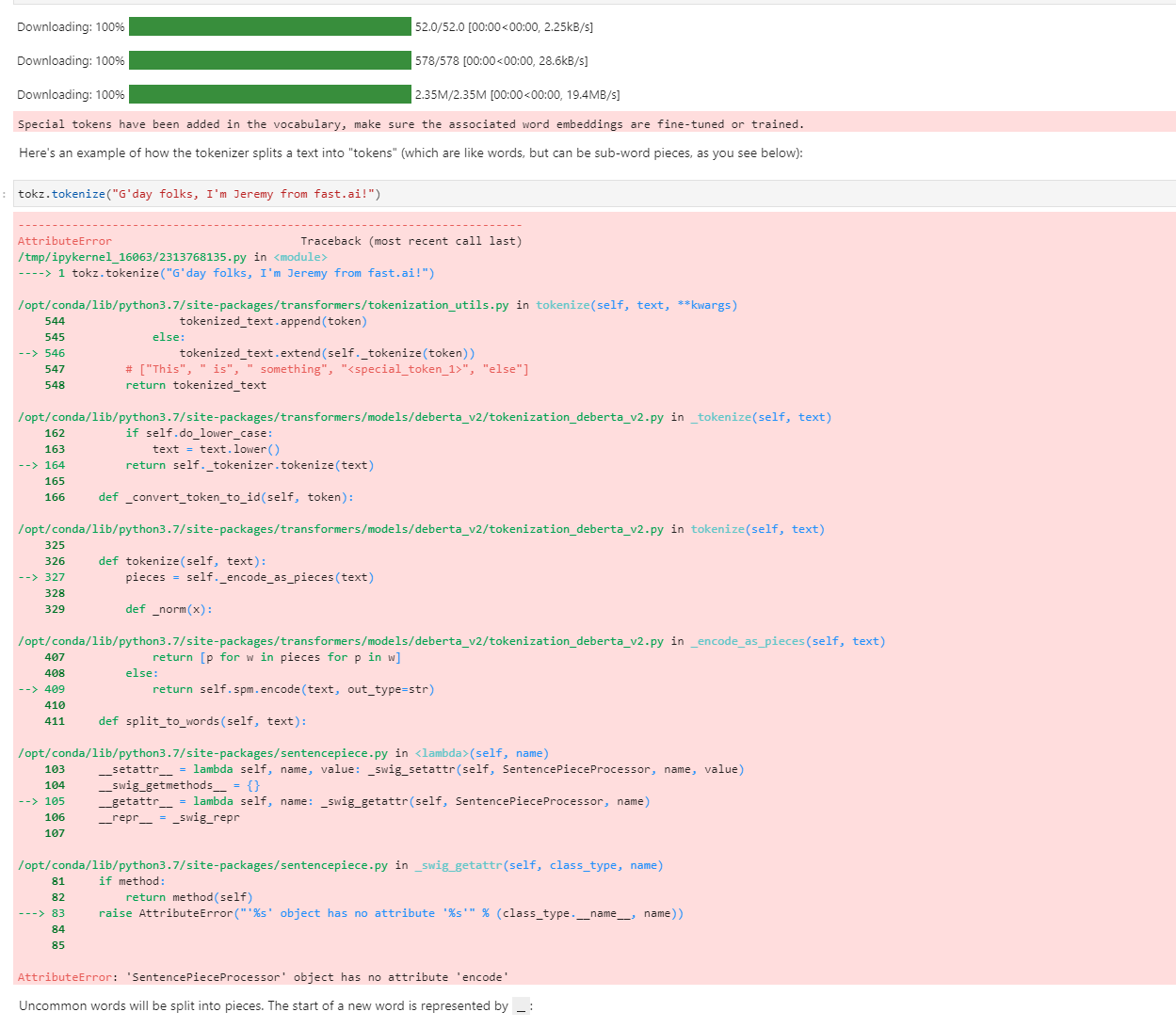
Searched on the web, haven’t got past this on Paperspace.
1 Like
When you get an error like that, try searching the forum. When I searched, I found this:
2 Likes
Thank you. Had to do with sentencepiece module was 0.1.86, required pip install sentencepiece==0.1.96
2 Likes
I am trying a project using HuggingFace. I have been able to follow the Patent Notebook regression classification and tried it with a couple of other models. All good.
I am now trying out a Twitter binary classification project using vinai/bertweet-base . (I don’t want to provide more information than needed if my problem is simple.)
I believe my model to be training as reflected by the decreasing loss function, but this is not being reflected in the Accuracy Metric. Below is the definition of compute_metrics and the results of testing it. (Borrowed from the Hugging Face forums.)
I’ve looked through the Hugging Face Fourms and consulted their online course (hosted by Sylvian). I’ve also posted a similar post there, but am a new user and am quarantined. I can’t seem to figure it out.
Any suggestions on why my Accuracy not changing?
I have really come to appreciate how much I like the fastai libraries. The default behaviors and tolerances to different data types is so appreciated!
from datasets import load_metric
def compute_metrics(eval_pred):
metric = load_metric("accuracy")
preds, labels = eval_pred
preds = np.argmax(preds, axis=1)
return metric.compute(predictions=preds, references=labels)
x = np.array([[.2,.8],[.3,.7],[.6,.4]])
y = np.array([1,1,1])
compute_metrics([x,y])
Out[103]:
{'accuracy': 0.6666666666666666}
Here are the training results:
Execute Training
In [109]:
trainer.train();
executed in 2m 54s, finished 17:36:39 2022-05-31
The following columns in the training set don't have a corresponding argument in `RobertaForSequenceClassification.forward` and have been ignored: handle, __index_level_0__, input. If handle, __index_level_0__, input are not expected by `RobertaForSequenceClassification.forward`, you can safely ignore this message.
/home/cdaniels/mambaforge/envs/fastai/lib/python3.9/site-packages/transformers/optimization.py:306: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(
***** Running training *****
Num examples = 12827
Num Epochs = 4
Instantaneous batch size per device = 128
Total train batch size (w. parallel, distributed & accumulation) = 256
Gradient Accumulation steps = 1
Total optimization steps = 204
/home/cdaniels/mambaforge/envs/fastai/lib/python3.9/site-packages/torch/nn/parallel/_functions.py:68: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.
warnings.warn('Was asked to gather along dimension 0, but all '
[204/204 02:51, Epoch 4/4]
Epoch Training Loss Validation Loss Accuracy
1 No log 0.154567 0.586997
2 No log 0.127953 0.586997
3 No log 0.125629 0.586997
4 No log 0.124032 0.586997
I appreciate all thoughts and suggestions.
My guess is that your model is always predicting a single label. Try generating some predictions and take a look at them to see.
In general, the best way to debug a model is to carefully look at the inputs and outputs.
I’m a little behind with the course and just watching Lesson 4. I stumbled upon the part where Jeremy cautions us about using cross-validation, saying that “cross-validation is explicitly not about building a good validation set”. ![]()
In the blog post from Rachel, I also found this paragraph which may explain better the point.
However, the problem with cross-validation is that it is rarely applicable to real world problems, for all the reasons described in the above sections. Cross-validation only works in the same cases where you can randomly shuffle your data to choose a validation set.
I don’t agree with this point though. Those examples listed in the “New people, new boats, new…” section of the blog are data leaks, as much as many other famous examples in other tabular Kaggle competitions. Some of these data leaks are hard to identify and only become apparent when comparing performance between CV score and Private Leaderboard (or the production environment in the industry).
As a matter of fact, in competitions and real-world applications, we often use stratification and grouping (among other techniques) to guarantee our validation strategy does not suffer from these type of leaks.
I would rephrase this sentence as
Simple k-fold cross-validation only works in the same cases where you can randomly shuffle your data to choose a validation set. In all other cases, special attention must be paid to remove possible data leaks.
The role of cross-validation is to validate the performance of our model on data and conditions similar to the one it will see in production.
Perhaps I completely misunderstood Jeremy and Rachel’s message. After all, fastai goes a step ahead and requires practitioners to always have a validation set.
Related to the post above, but IMHO deserving its own post, I have a question. Why we don’t automatically report in fastai the training score? The validation score is definitely what we are more interested in, I can see that. However, comparing training and validation score would allow us to assess the variance (overfitting) problem.
Being able to measure if we have a bias or variance problem would help practitioners to identify what is the best next step to improve model performance.
No that’s not really correct - when you expect your inference time data to be from a different distribution to your training time data (which is very common) you need to reflect this in your validation set. It’s not a data leak, it’s an actual design issue.
2 Likes
Overfitting occurs when the validation error starts getting worse, and isn’t related to what’s happening in the training set.
Solved:
Ok finally figured it out. Here are my notes for the next person :
- Specify num_labels=2, i.e.,
model = AutoModelForSequenceClassification.from_pretrained(model_nm, num_labels=2) - The exact name of the labeled data needs to be: Labels (Jeremy mentioned this in his lecture.)
- Only use Integers as
Labels. I had Strings aslabelsand for the longest time 0.0 and 1.0 ,which I had need asfloatsto fix another problem. - Transformers are very picky about data types!
I tried all of these solutions independently: Floats, Strings or Integers as Labels and num_labels=1 or num_labels=2, but it took me two days to get Integers as Labels and num_labels=2.
This really makes me better appreciate the thought and care that has gone into fixing all of these sharp edges and corners in the fastai library!
My Challenge with Binary NPL Classification using Transformers
Thanks! That suggestion really helped me figure out what was happening. Per the attached, I am getting back preds of shape 512x1. As is a binary classifier, the shape of preds should be 512x2. Accordingly, the reason the Accuracy wasn’t changing in my model was because there was only one class, not two as expected. (The np.argmax function had only one argument to choose from.)
I implemented my model based upon the notebook you discussed in class: getting-started-with-nlp.ipynb . I now realize that it was a regression model and what I’m doing is a classification, which is inherently different. I believe I need to have a second class of labels. Does this mean I should be doing one-hot-encoding, one column for each of the two class?
Thanks,
In [223]:
preds = trainer.predict(eval_ds).predictions.astype(float)
preds
Out[223]:
array([[-0.01423645],
[ 0.02276611],
[ 0.02436829],
...,
[ 1.02539062],
[ 1.02832031],
[ 1.02441406]])
2 Likes