Yes you are correct! it does say NaN for 3rd epoch but ok for 1,2,4 … my notebook from that run still has the output so I’m sharing it here.
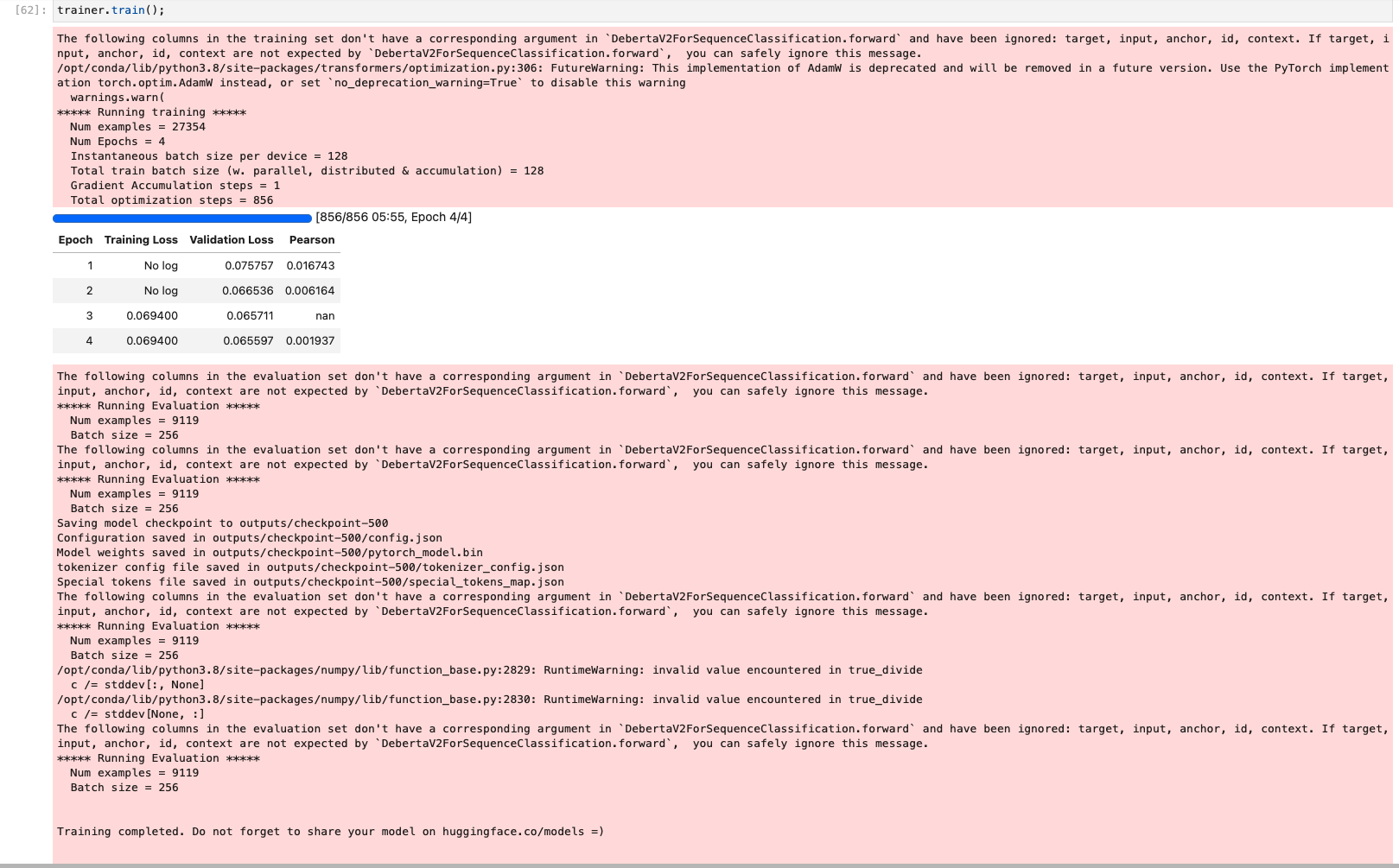
My experience is that once you get a NaN, later you will get more and more, and have to start again, but need to fix the dataset, as there is something wrong with it.
but don’t use that again, too expensive bro!!
I am setting a new environment and following the hugging face installations Installation
(npl) orangel@Mikael:~$ python3 -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
No model was supplied, defaulted to distilbert-base-uncased-finetuned-sst-2-english (https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 255M/255M [00:11<00:00, 24.3MB/s]
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48.0/48.0 [00:00<00:00, 28.0kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 226k/226k [00:00<00:00, 1.69MB/s]
[{'label': 'POSITIVE', 'score': 0.9998656511306763}]
it looks like is good, going to run notebook give me 20
@mike.moloch I got it working
Installations steps I took:
0.- conda create -n npl python=3.9
- install pytorch – conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch ( this need to be first)
2.- pip install git+https://github.com/huggingface/transformers
3.- pip install datasets
3.- conda install -c anaconda protobuf (needs to be from conda, if you install from pip will not work)
4.- conda install -c conda-forge sentencepiece
5.- test installation with – python -c “from transformers import pipeline; print(pipeline(‘sentiment-analysis’)(‘I love you’))”
result == [{‘label’: ‘POSITIVE’, ‘score’: 0.9998656511306763}]
6.- install jupyter notebook lib’s – conda install nb_conda
7.- this is a yml file
dependencies:- jupyter
- scikit-learn
- scipy
- pandas
- pandas-datareader
- matplotlib
- pillow
- tqdm
- requests
- h5py
- pyyaml
- flask
- boto3
- pip
- pip:
- bayesian-optimization
- gym
- kaggle
Then run jupyter notebook and trained model_nm = ‘microsoft/deberta-v3-small’
result:
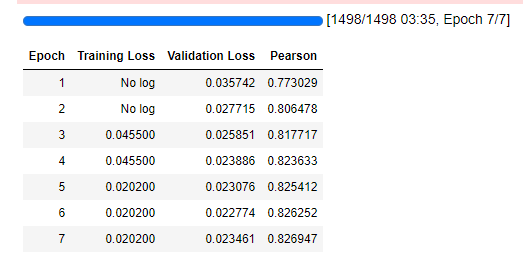
it kind overfit very fast.
using model_nm = ‘microsoft/deberta-v3-large’
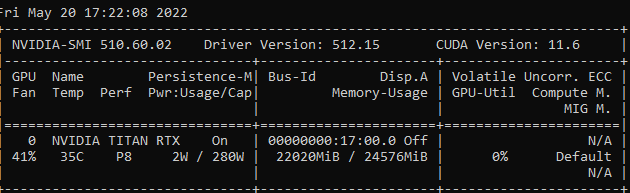
Just freezes …
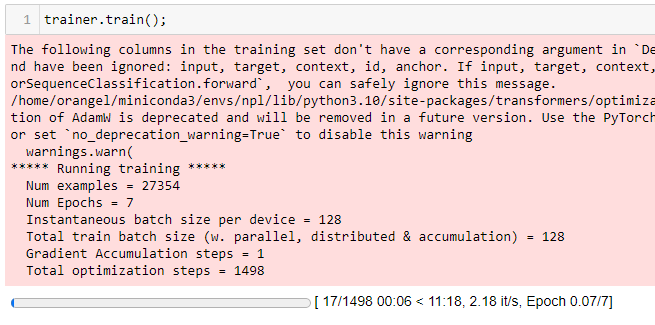
as you can see there is 22G used but no GPU activity.
1 Like
using microsoft/deberta-v3-base it runs no problem, maybe there is a problem with the v3-large model. But I don’t understand why the training loss is “No log” and only uses 12,208G of GPU RAM
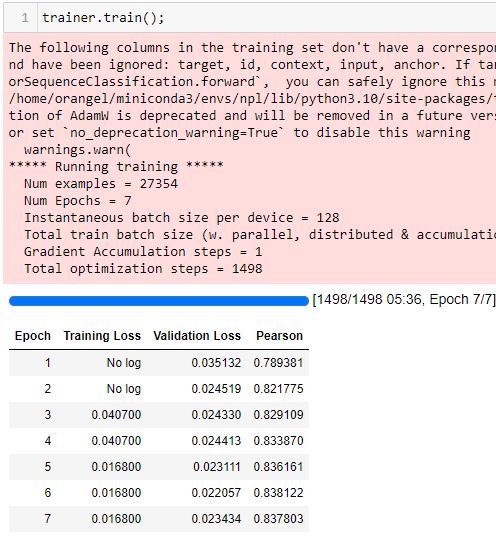
Yay! and thanks for posting your working setup details, it will be helpful for others.
BTW, I think it needs more memory than your card may have. IIRC, you have a 2x3090 setup? If it’s not setup with NVlink, I don’t know if it can split the load across two cards. From what I’ve seen, it shoots up to 22GB then 24 then 27 or so before the first epoch finishes and by 3rd epoch it stabilizes at 29GB. It does seem like you’re hitting GPU RAM ceiling. Maybe more experienced users like @balnazzar can comment on this behaviour?
1 Like
Please don’t at-mention me except for admin stuff which no-one else can fix.
1 Like
Something I’m struggling a lot with for this lesson is hitting CUDA out of memory errors pretty much wherever I tread. Currently, I’m trying to train a model, following the pattern of Jeremy’s Kaggle NLP notebook very closely.
I have my own dataset which I’m using, and the big difference is that the input for each row is not tweet-length but page-of-text length. (Each row consists of the text extracted from documents page by page).
I’ve tried training on bigger machines, but more or less immediately I’m hitting ‘CUDA out of memory’ errors. I found the forum helpful in figuring how how to re-run my notebook, but not much sense of how I can think about debugging or thinking through how to get past this issue.
Things I can think of:
- keep lowering the batch size
- use a machine with larger RAM
I guess somehow I want the equivalent of the batch resize that goes on for images so that they don’t take up too much RAM.
Any thoughts or suggestions on this? How are you all managing to train your models on new data and avoiding ‘out of memory’ issues along the way?
Thanks in advance!
UPDATE: Got it working with one of @VishnuSubramanian’s JarvisLabs 24GB GPU RAM machines and a batch size of 4. Still feels like maybe I’m doing something wrong here, or there’s some trick to being more efficient?
UPDATE 2: I quite quickly maxed out the storage space on the instance as the trainer seems to save all the model weights at the end of each epoch and apparently after 5 or 6 epochs that amounts to 20 GB of space!
UPDATE 3: I think I have my answer (in the update section of my blog on the whole process of training this model): Redaction Image Classifier: NLP Edition | mlops.systems TL;DR: my documents are quite long and this causes issues with RAM and with the model metrics / performance.
3 Likes
There’s also the 48GB GPU machine. The trick is to get all your ducks in order on a base level machine. Then pause it, then restart it with a bigger GPU like a A6000 with 48 GB VRAM and then quickly run your model through. You can also up the number of CPUs and RAM if you need it for pre-processing before feeding it to the GPU.
I was pleasantly surprised on how seamless the Jarvislabs experience was. I’ve worked with Paperspace instances before but always felt overwhelmed with the amount of choice etc. Jarvislabs seems to be hitting the sweet spot when it comes to “less is more.”
And of course, YMMV! ![]()
5 Likes
@mike.moloch, but I said before if you lower your batch size you won’t be hitting your GPU memory selling.
I just Bought my NVlink, haven’t gotten it yet, the thing I don’t understand is how just text occupies so much memory! I thought it was something just with images because 128 batch size how much text data it is ? anyone?
But previously in this thread you indicated you weren’t able to train for deberta-v3-large regardless of how small you made the batch size.
Are you saying with your new conda setup, you’re able to train with for 4+ epochs on a 3090 with 24GB ? if so at what batch size?
P.S. I’m just indicating to @strickvl that 48GB instances are also available and they are reasonably priced (if jused judiciously and if it’s not reserved instance) With the couple experiments I did, it cost me about 0.50 cents, which is not bad since it would be prohibitively expensive for me to have an A6000 setup at home.
3 Likes
An important point I mentioned in the last lesson: generally ULMFiT is going to work better for long documents. As you’ve noticed, memory is an issue otherwise. Also ULMFiT generally is more accurate for long documents.
7 Likes
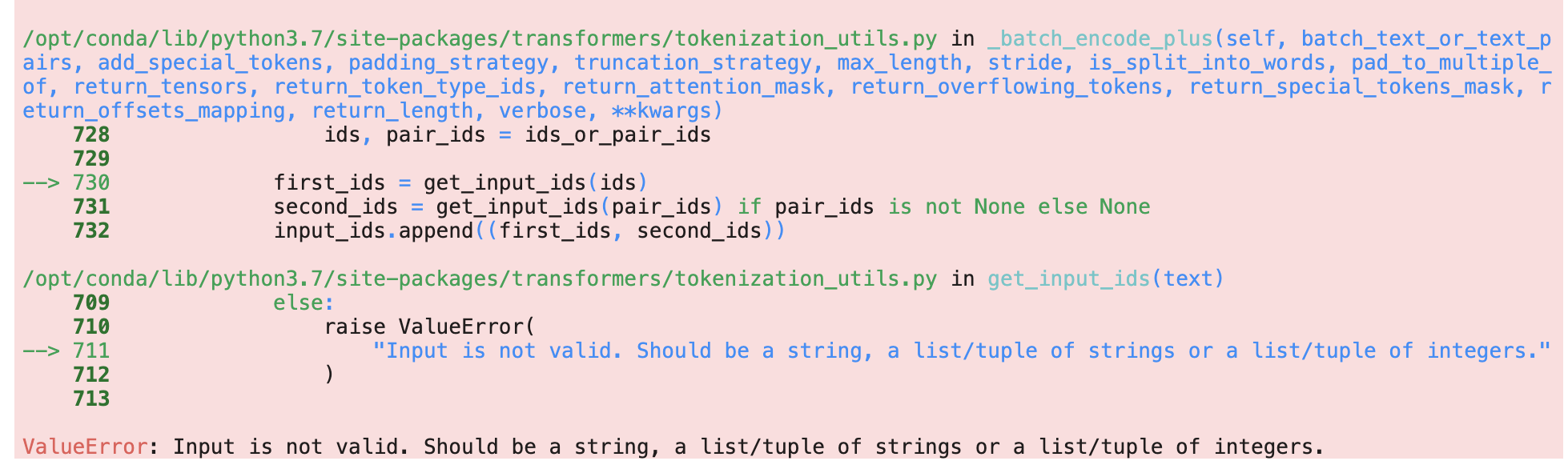
For anyone else that ran into this error: Input is not valid. Should be a string, a list/tuple of strings or a list/tuple of integers. Don’t forget to drop the null columns! Took me a moment to figure that out.
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.dropna.html
Help needed!
New error: “mse_cpu” / “mse_cuda” not implemented for ‘Long’. Anyone have insight? I believe Long is a datatype in Pytorch but I’m not familiar enough with Hugging Faces to know what to change.

There are some good blogs if you google that error message. I had the same issue. I think it boils down to you having a categorical output/label value and as a result with the same settings etc you’ll need to convert your labels column into something that can be expressed as a float. At least, that was how I solved it on my end when I encountered that.
1 Like
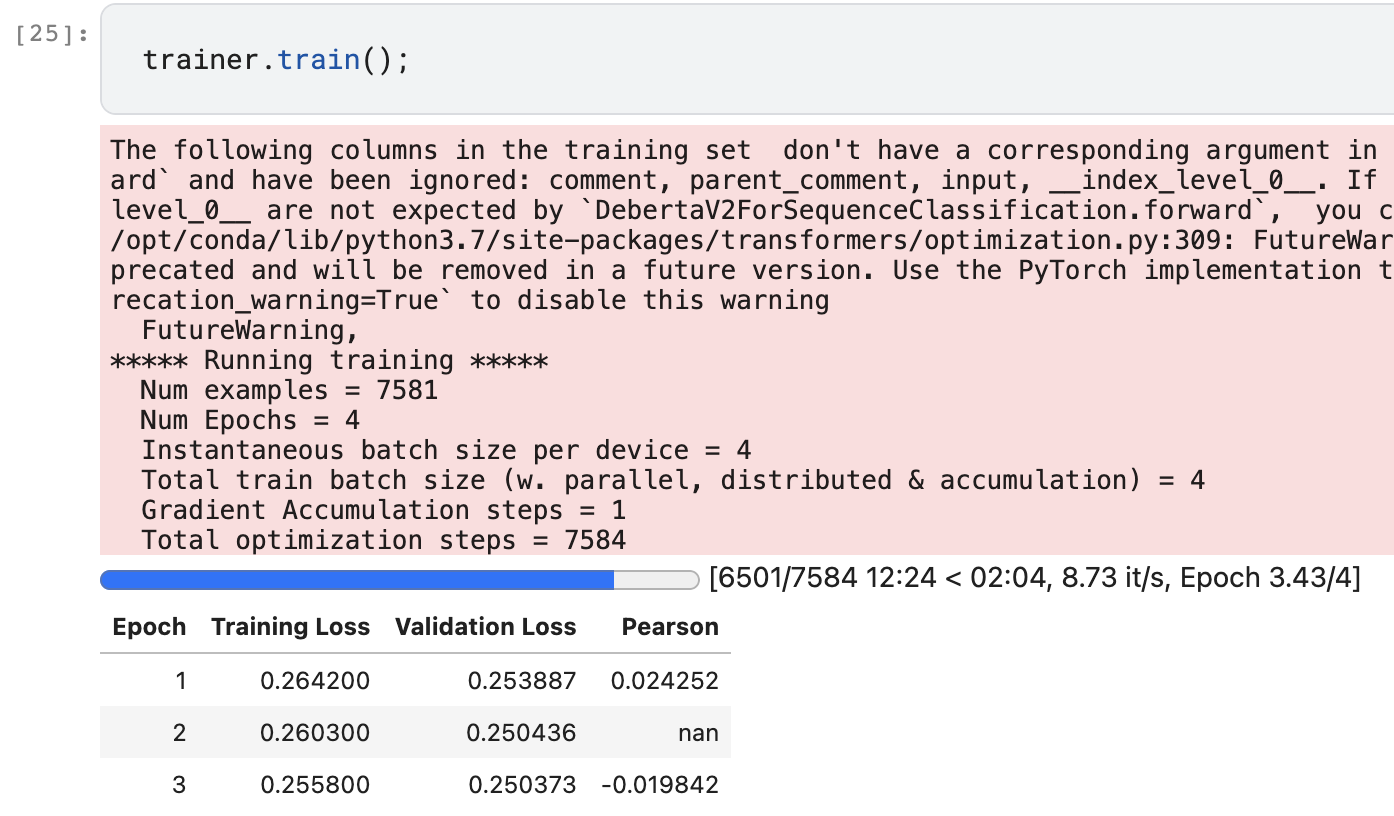
I’m having trouble creating and using a test set with ULMFiT. I have trained the model and have been able to test it on individual documents, but I am having trouble validating the model on a larger test set . As can be seen below, I believe I need to create a new dataloader for the test set. This is the piece that I am not sure about. I can provide more detail, but would appreciate any help, as this has already consumed several hours of time . . . Thank you in advance.
from fastai.text.all import *
inference_2019 = load_learner("blue-or-red-2019.pkl")
df_2022 = pd.read_csv("blue_red_training_valid.csv")
df_2022.describe()
text party
count 9057 9098
unique 9027 2
top Democrat
freq 5 5234
inference_2019.predict(df_2022.text[9097])
Out[12]:
('Republican', TensorText(1), TensorText([0.0779, 0.9221]))
dls_test = TextDataLoaders.from_df(df_2022,text_col='text', label_col="party")
preds,_ = inference_2019.get_preds(dl=dls_test)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
/tmp/ipykernel_2896616/3606503127.py in <module>
----> 1 preds,_ = inference_2019.get_preds(dl=dls_test)
~/anaconda3/lib/python3.9/site-packages/fastai/learner.py in get_preds(self, ds_idx, dl, with_input, with_decoded, with_loss, act, inner, reorder, cbs, **kwargs)
261 res[pred_i] = act(res[pred_i])
262 if with_decoded: res.insert(pred_i+2, getattr(self.loss_func, 'decodes', noop)(res[pred_i]))
--> 263 if reorder and hasattr(dl, 'get_idxs'): res = nested_reorder(res, tensor(idxs).argsort())
264 return tuple(res)
265 self._end_cleanup()
~/anaconda3/lib/python3.9/site-packages/fastai/torch_core.py in tensor(x, *rest, **kwargs)
134 else as_tensor(x.values, **kwargs) if isinstance(x, (pd.Series, pd.DataFrame))
135 # else as_tensor(array(x, **kwargs)) if hasattr(x, '__array__') or is_iter(x)
--> 136 else _array2tensor(array(x), **kwargs))
137 if res.dtype is torch.float64: return res.float()
138 return res
~/anaconda3/lib/python3.9/site-packages/fastai/torch_core.py in _array2tensor(x)
120 if sys.platform == "win32":
121 if x.dtype==np.int: x = x.astype(np.int64)
--> 122 return torch.from_numpy(x)
123
124 # Cell
TypeError: can't convert np.ndarray of type numpy.object_. The only supported types are: float64, float32, float16, complex64, complex128, int64, int32, int16, int8, uint8, and bool.
1 Like
Thanks! Will try that out. I’d love to see what blogs you found. When I searched for that yesterday I only found a Chinese blog that had no information. Only the error message
Update:
Apparently you can get a Pearson score in the negatives! Kept running out of memory to the point where I eventually trimmed my dataset to a random 1% (still 10,000+ comments). Not sure if I’m doing something wrong but I’m guessing it’s just a hard NLP classification problem
2 Likes
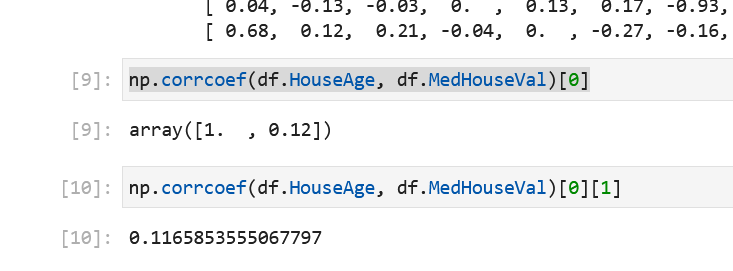
I am suprised why 0th row 1st colum is not actually 0.12, but 0.1165? Any idea why results occur like this?
2 Likes
This is just data types and display of precision.
The array you returned is type np.ndarray and the single coefficient is type float64
You can get the display precision behaviour you want in your arrays (say, display 2 digits) in NumPy by using:
np.set_printoptions(precision=2, suppress=True)
Here are some examples you can run:
In [1]: import numpy as np
In [2]: np.set_printoptions(precision=2, suppress=True)
In [3]: test_array = np.array([1,0.116585])
Out[3]: array([1. , 0.12])
In [4]: np.set_printoptions(precision=5, suppress=True)
In [5]: test_array
Out[5]: array([1. , 0.11658])
In [6]: test_array[1]
Out[6]: 0.116585
In [7]: type(test_array[1])
Out [7]: numpy.float64
In [9]: np.set_printoptions(precision=2, suppress=True)
In [10]: test_corr = np.corrcoef([[0.12732, .32457, .20909, 0.42110, 0.81011], [.23389, .18090, .56124, .61112, .12928], [.94121, .31230, .60164, .51051, .30010], [.341054, .75555, .91923, .19898, .21200]
In [11]: test_corr
Out[11]:
array([[ 1. , -0.34, -0.73, -0.52],
[-0.34, 1. , 0.21, 0.16],
[-0.73, 0.21, 1. , -0.05],
[-0.52, 0.16, -0.05, 1. ]])
In [12]: np.set_printoptions(precision=5, suppress=True)
In [13]: test_corr
Out[13]:
array([[ 1. , -0.34044, -0.73084, -0.51668],
[-0.34044, 1. , 0.21133, 0.16159],
[-0.73084, 0.21133, 1. , -0.05371],
[-0.51668, 0.16159, -0.05371, 1. ]])
In [14]: test_corr[0][1]
Out[14]: -0.34044188343772125
5 Likes
Thanks for the excellent explanation @n-e-w
1 Like
Hi Tanishq, thanks a lot for these resources. I’m coming from a medical background, and relatively new to NLP. Is there a sort of beginner-friendly biological/medical dataset that I can experiment with, just to try out the things I learn in the course?
2 Likes