Works for me also.
1 Like
Thanks Jeremy. I have added explanation on how i made it to work offline in the kaggle notebook:
Let me know if you have any questions or comments. Thanks!
cc: @Mattr
4 Likes
Maybe I did not understand your question fully so ignore if this doesn’t make sense. So, if we want to memorise the data then I would use just the document and do any calculations required in the usual programming way. No machine learning required as there is nothing to “learn”.
do you have any particular case in mind? Maybe we could run an experiment and see.
Is anyone having the same problem?
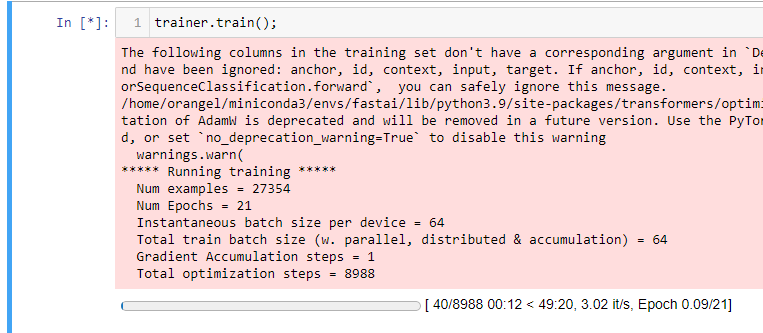
I am trying to compile the NPL notebook on my computer, using the deberta-v3-large, the system stops training and doesn’t run further without any error.
The model deberta-v3-small trains with no problem.
1 Like
How do we know the system has “stopped training”? Because if it stopped, it would have either given an output or an error. Does it run out of VRAM and hang and you have to restart the system?
Since it runs fine on a modest VM on Kaggle, I’d say it probably has something to do with the local setup. I would check the library versions and GPU RAM utilization using nvidia-smi as a first step.
1 Like
@mike.moloch thanks,
1.- It only uses 12G out 24 I have, I can see it on nvidia-smi, I tried on my WSL, on Linux and kaggle, on kaggle gives me an error, on a local machine just hangs.
2.- It does not stop just hangs. nothing else happens.
I can create a new conda env, has anyone know of a set of good instructions on how to install in a local machine?
Hi @orangelmx , you may want to run it in the free instance of paperspace. I will try to run it on my local setup later today and see if I get the same error. I see that you’re using bs=64 (vs 128 in Jeremy’s notebook) not sure if it has any impact though.
Hi @mike.moloch
I reduced the batch size to see if that was the problem… tried different ones, 16,32,64,256…and in everyone it hangs.
can you tell me how was that you did your local setup?
Thanks.
I haven’t run this notebook on my local setup, but my local setup for other experiments has just been a linux box (Ubuntu LTS 20.04) and I use the paperspace container from their docker hub.
ahhh, ok ok
I have the same Linux OS version, let me try that! but do you have any problems using docker with your GPU? in the past I could not get docker to work with my GPUs.
it will be nice if you can set it up on your local box and let me know how it does.
thanks.
In fact I ended up using docker precisely because I couldn’t get all the pieces going on the linux itself. It’s a roundabout way of doing this but seems to work for me (I’m not a docker expert, but muddled my way through by looking at various howtos and whatnot last year and it’s been holding together – fingers crossed ![]() )
)
When I tried running deberta-v3-large on Kaggle, I got an out of memory error. My local GPU is only a 1070ti (8GB) so I’m sure it won’t go anywhere with that either.
BTW, how do you search for what models are available? is that information in the datasets.list_datasets() function? because I don’t see the deberta-v3-small (or large for that matter) listed in the output of that function.
@mike.moloch yes I was looking for something similar to Which image models are best? for NPL and Tabular datasets, but never got a response.
I believe if you use CoLab you get to have 12G of memory, on kaggle with the large model, I lowered the batch size but gave me an error too, but at least run… jeje
sorry I just meant how do i search for a model in the available model sets. For example, where is it provided that the model name will be “microsoft/deberta-v3-large” etc? do you just search for it on the huggingface website?
I think the v3-large model tries to allocate a lot (>10GB) vram in one go and so it fails. It doesn’t take long to fail either, it fails imediately so, whatever it’s sending to the GPU from the get go is so huge that it fails on the first try (for the kaggle 16GB gpu).
Maybe the deberta-v3-large needs to have more resources than are available to mere mortals? I mean a 3090 is a big card, but maybe it needs baseline 40+ gb ? not sure.
@mike.moloch I have 49 G on GPU RAM, but I don’t think that is the problem should be able to run by just changing the batch size, e.i. 16,8,4… or even 2 or 1, even though I have found that a very low batch size will not give you a good generalization.
You can search here:
1 Like
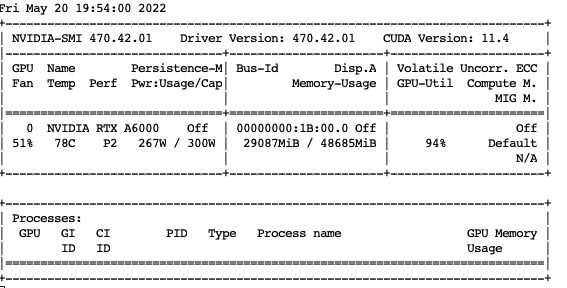
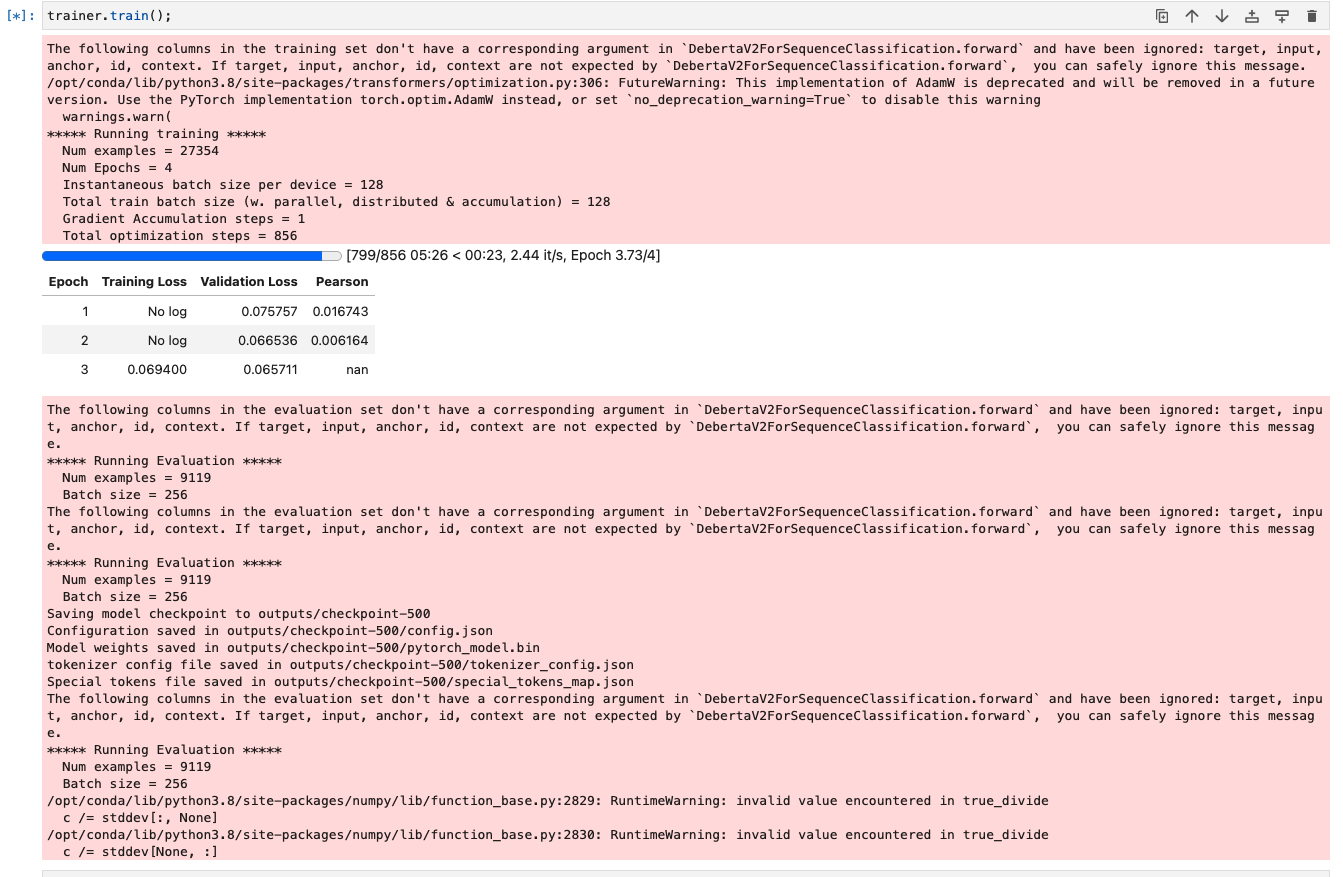
Well, I’m running it on a Jarvislabs A6000/48GB GPU and as soon as I started (bs=128) GPU usage shot up to 24GB and then by the end of 1st epoch it stabilized around 29GB as you can see below :
1 Like
Nice!!! @mike.moloch, can you lower the batch size to 64 and see what happens? did the model train to the end ?
I get the same thing “nan” all the time, anyone?
Thanks.
1 Like
Yes, the model trained to the end for 4 epochs. Unfortunately I didn’t take a screenshot before I stopped the machine. I’m note sure if it’ll be there if I restart it. By halving the batch size, do you expect to see it train for longer?
EDIT: re: the NaN , I thought it was there because the epoch wasn’t complete yet. As you can see the 3rd epoch was in progress when the screenshot was taken and maybe that’s why the pearson number hadn’t been calculated. Not sure tbh.
I believe that the 3rd epoch is finished and there is a problem, that is why you see the NaN. I couldn’t make it work with docker, I really don’t know much about it and don’t have much time for that, I will create a new fresh env on conda and see