Hey team, I am experimenting with fine-tuning a different NLP model.
I am following the exact same code from Jeremy’s notebook (Getting started with NLP for absolute beginners | Kaggle), except using a different model name.
Jeremy’s notebook: using microsoft/deberta-v3-small.

My experiment: using distilbert-base-uncased-finetuned-sst-2-english by following instructions from here.

But whenever I call trainer.train(), I do get an error message indicating the shapes of input arrays aren’t the same.
Full Error Message:
“ValueError: all the input array dimensions for the concatenation axis must match exactly, but along dimension 1, the array at index 0 has size 1 and the array at index 1 has size 9119”
Error Screenshot:
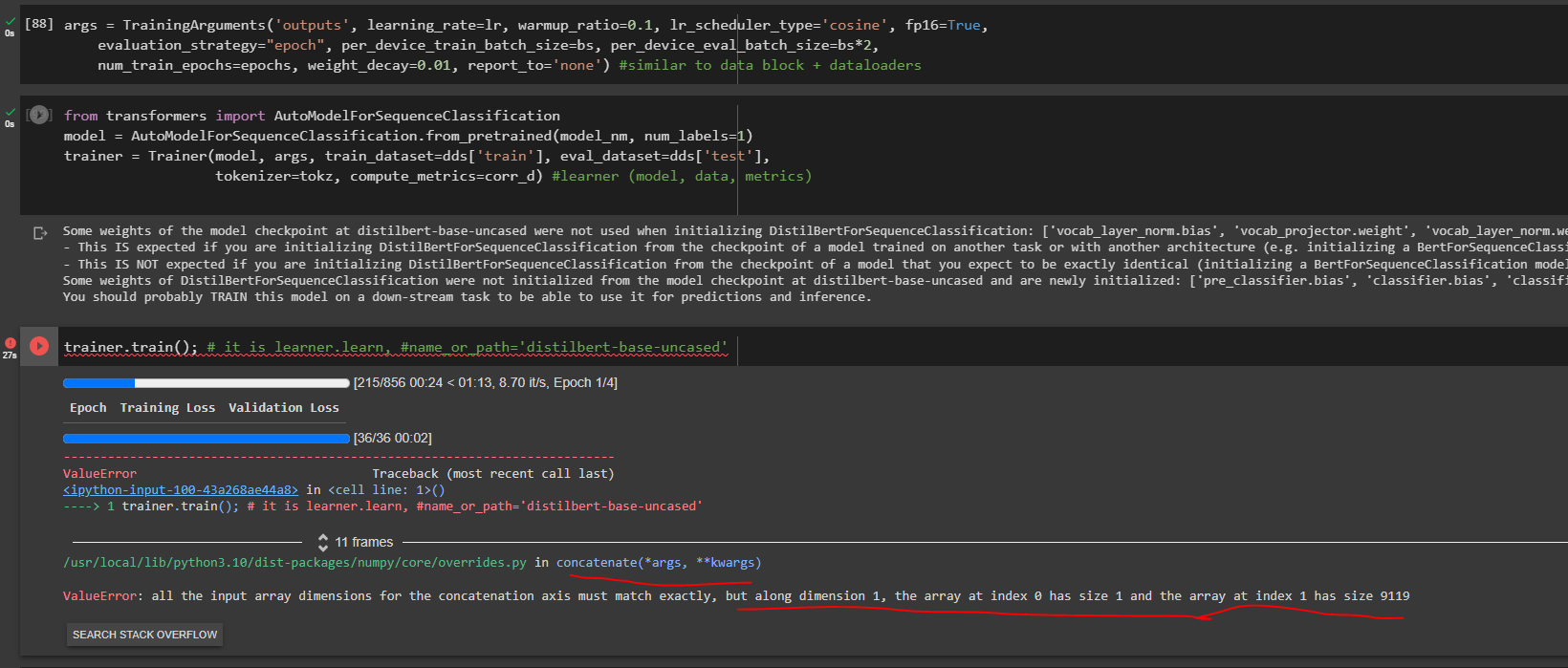
I am not quite sure which arrays have different dimensions in this case. I suspect some model configs, argument configs might need to be updated for a different model as the same configs worked for microsoft/deberta-v3-small.
I saw a similar question from the forum (Lesson 4, multi-label classification ). It did not have a solution but had a good starting point to understand the issue which is the hugging face tutorials about Transformers.
While I am learning about how to use Transformers to finetune different models correctly, has anyone encountered a similar issue before or knows some other points I can unblock myself? Any insights/ideas would be greatly appreciated ![]()
This is the link to my colab that contains all e2e code: