Linear means to me that the parts of an equation or calculation are added or subtracted. The parts are products of values. (https://en.wikipedia.org/wiki/Linear_algebra)
1 Like
How do we know how big the Weight and Bias matrix need to be to approximate a specific problem ?
How do you view the learning after each epoch? To visualize the errors/
You really don’t know in advance.
In most cases it is just a matter of trial and error, figuring out what works best.
SGD gives a way to refine the parameters but how to guess how large a model is needed to solve the problem at hand ?
How could we use what we’re learning here to get an idea of what the network is learning along the way – like Zeiler and Fergus did, more or less?
3 Likes
Start from literature to understand if your problem has already been studied by someone else.
If yes, copy what has already been done, otherwise you just have to experiment yourself.
1 Like
Interestingly, didn’t see any difference in accuracy using nn.LeakyReLU() in place of relu.
2 Likes
Did we just replace Sigmoid with ReLU?
1 Like
Where did this name “itemgot” come from? (having hard time remembering…)
2 Likes
Yes. Swap it out and see what happens. 
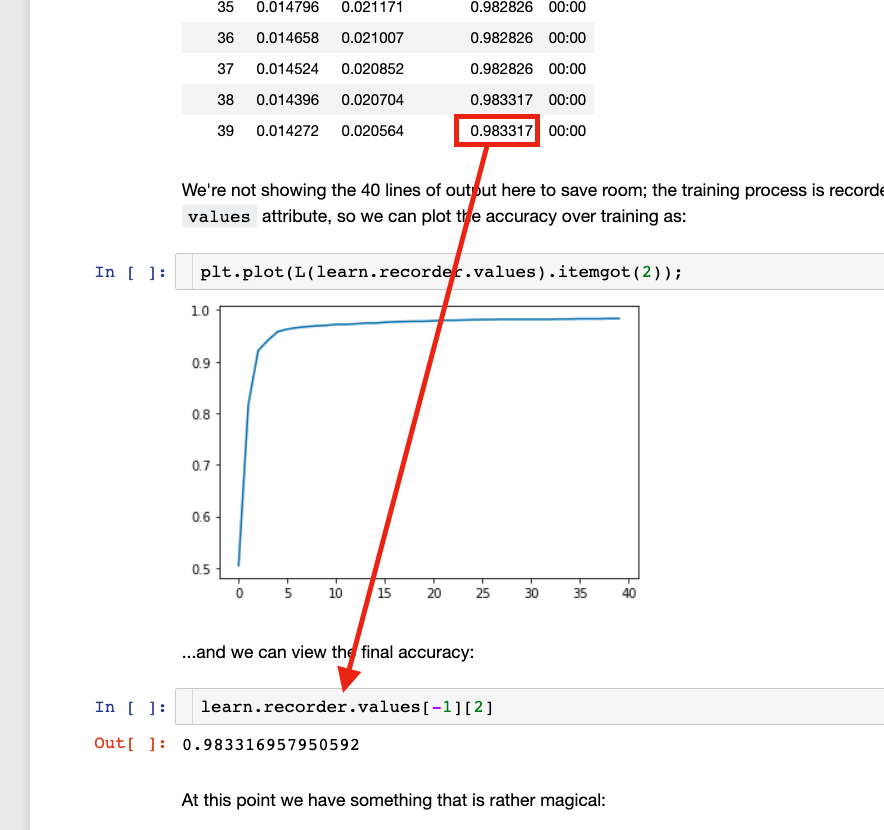
can you explain again what does this line of code doing? learn.recorder.values[-1][2]
1 Like
It’s a method of L, which returns the i-th value of each element inside.
1 Like
In the first week I learned you can copy past multiple cells, TIL you can select multiple cells and run cells together 
1 Like
Is there a rule of thumb for what nonlinearity to choose given there are many?
No, the sigmoid is applied at the end in order to ensure that predictions are between 0 and 1, which is the case for our binary classification task. Sigmoid is used at the end of the network in the loss function (to be more precise) whereas the ReLU is used in between layers.
3 Likes
That will give you a good starting point but wont that search of the model space be directionless … SGD gives a way to search the parameter space ensuring progress in local optimal direction. But for model size, topology if we can only come up with better guess then finding a improved model is just pure chance isn’t it?
It is grabbing the accuracy metric of the last epoch. [-1] is the last epoch, [2] is the third item from the learn.fit table that is generated.
2 Likes
I don’t think we know that prior but we can take a guess therefore we have a prior, the data is something we are trying to solve and we also have a generative model. All that is check. We could look into Bayesian optimization. Please look into this notebook. Thanks to @muellerzr
4 Likes
You wait for Quoc. Le to evolve the new state of the art architecture 
2 Likes