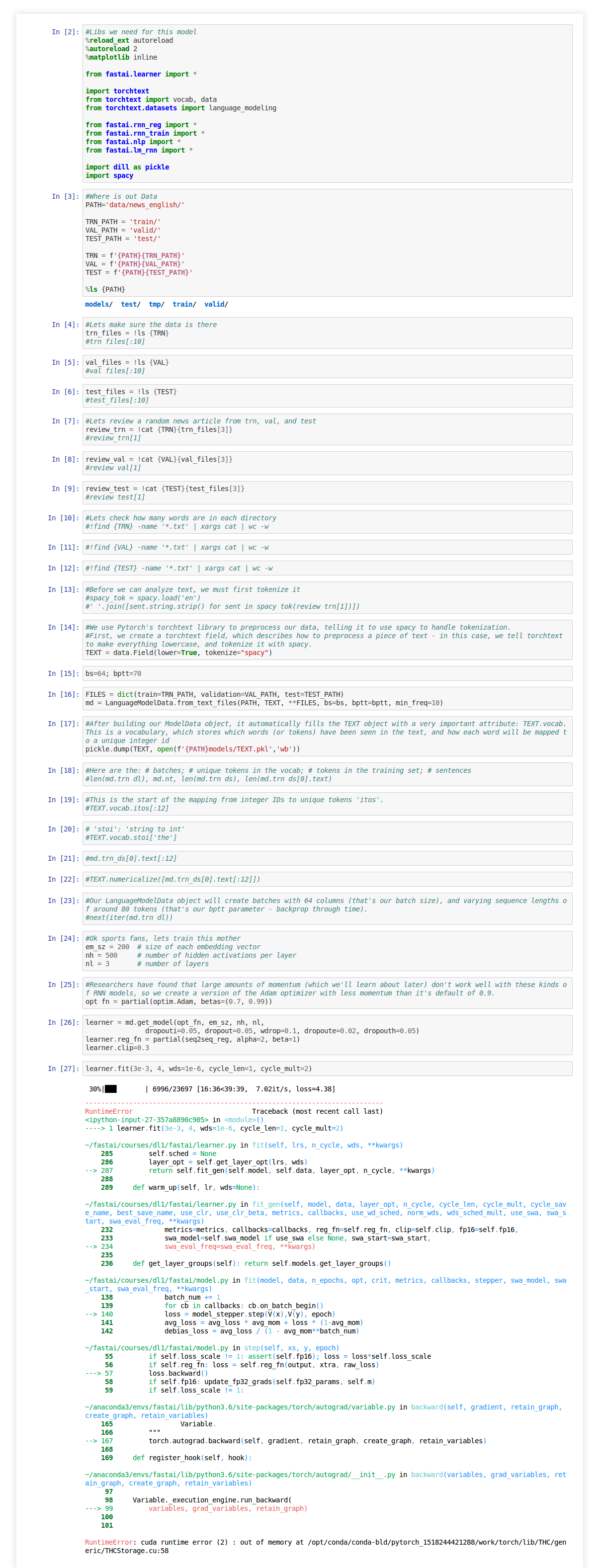
I am trying to build a language model from lesson 4 in English. The only difference from class is the data. My data is ~100k random news articles. Each article is a .txt file at least 1kb in size. I split the corpus into 3 dirs: /train ~60k /test ~20k /valid 20k. My problem is when trying to run the same code as in Lesson 4 (lesson 4-imdb) I run out of memory at 30% into my first run. I am using a single 1080ti (11GB mem).
My question is should I change some of the code for example the batch size or should I cut the data set in half, train the model, then train it again on the second half?
P.S. if I change the batch size to something like 32 or 16 or 8, should I also change the back prop through time also to save memory or would that harm the learning? Is there a batch size width to bptt height sweet spot or best practice ratio?