a question on the sequence of words fed into the RNN.
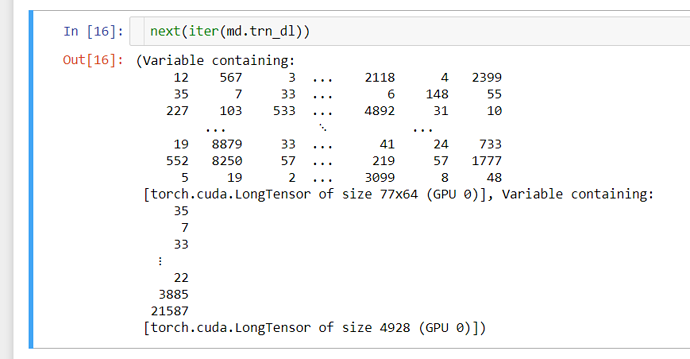
In the image below, the words (corpus of IMDB reviews) are first arranged in continuous columns. However, when the words are flattened into a 1d vector, they are flattened horizontally. (i.e. 35, 7 33 … 22, 3885, 21587). If i am not wrong, this is not a comprehensible sequence of words fed into the RNN. Could I know why is this so?
This is a screenshot from Jeremy’s notebook and in the video lecture, he said that the corpus was arranged continuously in vertical columns. I.e. column 1 is one long sentence while column 2 continues where column 1 ends. Hopefully I am not wrong at this.
However, the lower part of the image shows that the 77x64 array is flattened into a size 4928 vector, in the order of 35,7,33…22,2885,21587 . My question is that this doesnt seem to be a comprehensible (at least to human) way of arranging the words fed into the RNN. Is there a reason for this?
so they have the same size. just the second one is flattened. 77x64 = 4928
in the first matrix, sequences are ordered from top (first word) to bottom (77th word), while each column is a batch that gets computed in parallel.
the second matrix represents the first matrix shifted by one one element in each sequence. so the top row of the top matrix is shifted out of the matrix.
if you look at the sequence of numbers in the second matrix. 35, 7, 33… and then look at the numbers in the second column of the first 35, 7, 33… you’ll see they match. when the second matrix was flattened the elements will be ordered one row after the other.
if you’re saying looking at those numbers is like looking at the matrix and that it’s impossible to easily see what they are. then yes. it’s not really human readable.
but you can look at the TEXT.vocab.itos and stoi dictionaries to figure out what words are actually represented in the array. there are a couple of samples in the notebook for converting arrays to strings.
 o?
o?