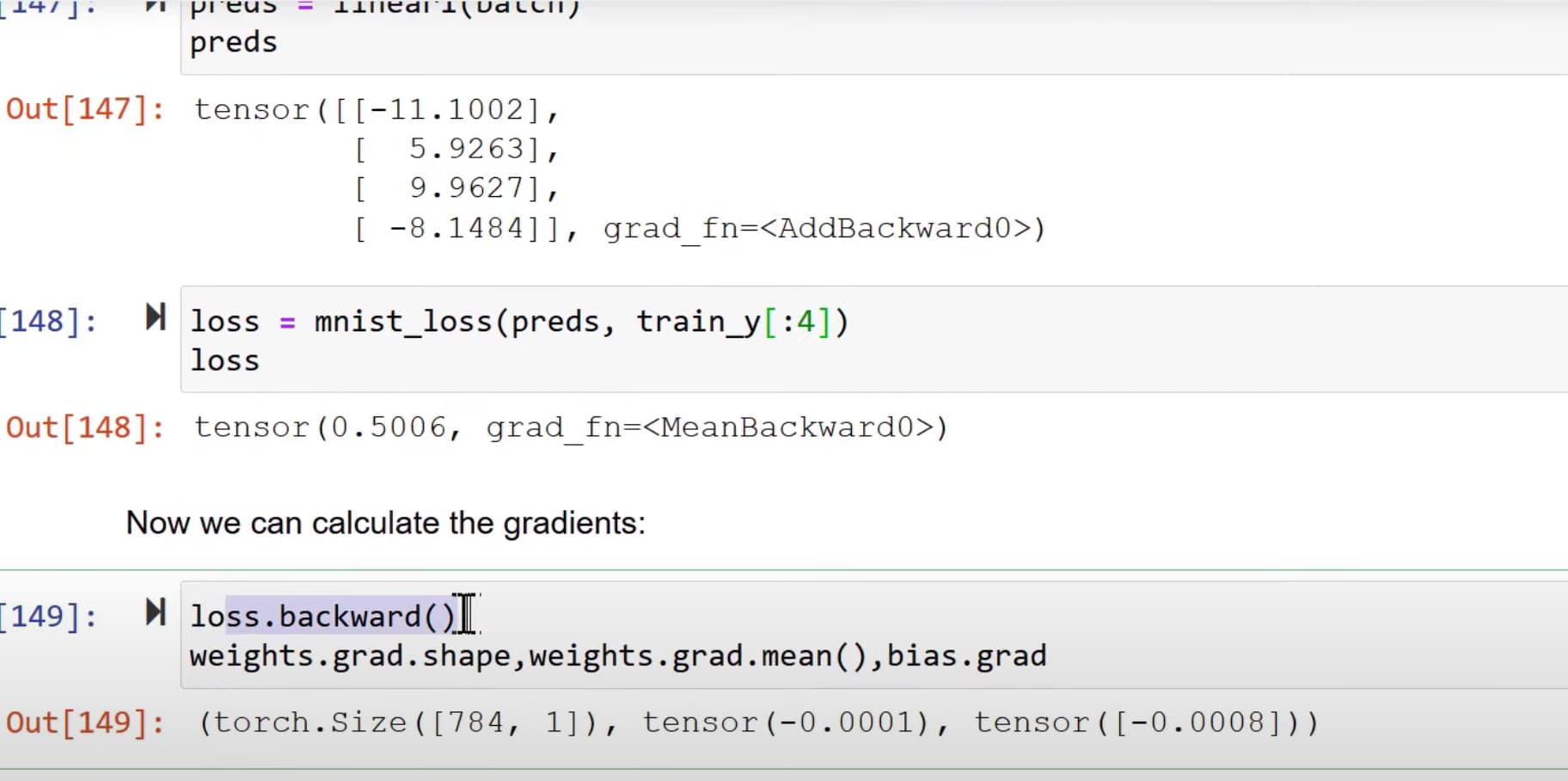
Okay, so I can follow the lesson until Jeremy calculates loss.backward()
is requires_grad_ that is input earlier the bridge between the loss function and the changing of the weights? I’m not sure where in the code the weights (and their subsequent changes) are linked to the loss function (in this case mnist_loss).
My only guess is that ‘preds’ is one of the arguments, and that is derived from the function ‘linear1’, but I’m not sure.
Just looking to have someone clarify how pytorch is calculating the 784 weights and their changes from a function that doesn’t seem to have the n-dimensional qualities I keep hearing about for a loss function. Thanks!
weights are what gets multiplied with the input (data) to obtain a prediction.
Prediction is a single value for each example.
Loss is a value you obtain by comparing the prediction(s) to the ground truth (actual values, labels of the dataset).
Gradients are quantities that express what will happen if we modify each of the weights. For some weights, if we decrease them, the predictions will improve. For other weights, if we increase them, the predictions will improve (and thus loss will go down).
Equipped with this knowledge we subtract the gradients from the weights. In fact, we subtract a smaller quantity than the graidents, gradients * learning_rate.
Once we perform the subtraction, we can run the prediction yet again (with new weights now) and hopefully we attain a smaller loss!
AFAIK, requires_grad_() tells pytorch to start tracking a variable, So to me it does seem that this is “the bridge” between predictions and how the next iteration or forward pass will go
Forward Pass → gets predictions
backward pass → use our prediction and how far off it is from the target (ie; “the loss” ) to calculate new weights (we can do this because we’ve been tracking gradients via requires_grad_()
rinse,repeat.
so I think the magic is happeing in loss.backward()