I was also confused, so I went back to the workbook to look at the actual python definitions:
def mae(preds, acts): return (torch.abs(preds-acts)).mean()
def quad_mae(params):
f = mk_quad(*params)
return mae(f(x), y)
# earlier we defined y as a list of noisy measurements
# y = add_noise(f(x), 0.15, 1.5)
I think confusion might arise (as it did for me) because quad_mae uses y (which is all of the noisy measurements) without it needing to be passed in as a parameter.
Hope this helps!
Hi. As an exercise for chapter 4 of the book I’ve tried a simple model to classify the full MNIST dataset. I’m getting about 92% with logistic regression and above 95% with a two layer model. Feedback is more than welcome: Fastbook ch4 MNIST complete | Kaggle
These concepts are no less relevant in the era of vibe coding. I am looking to make this learning experience more social and evenly-paced, if anybody would like to join me. I live in a UTC-4 timezone.
If anyone looking for a refresher in calculus before doing the book chapter or even this lecture
3b1b
have a good playlist, the first 2 chapters is enough. You could watch it all would give a lot of intuition and visual representations.
Hi all,
In the microsoft excel exercise, Jeremy shows a gradient descent on two sets of parameters. If I want to visualize it in terms of a neural network architecture, would it be a neural network with one layer and two neurons as there are two sets of parameters and two outputs which we are summing up?
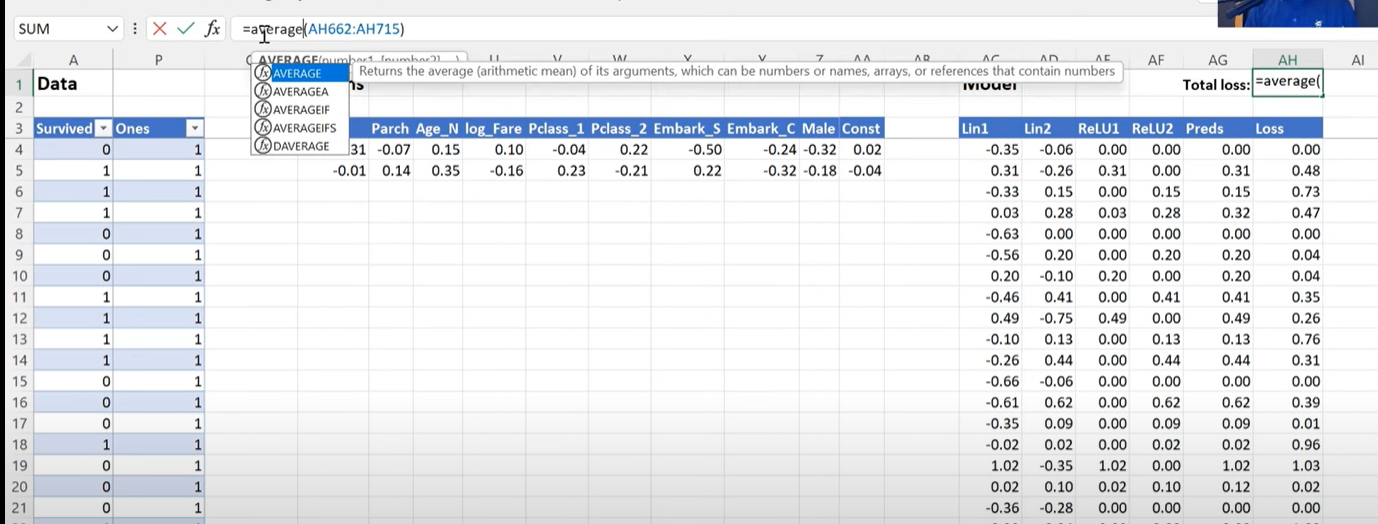
Above is Jermeys Code.. I guess either he made a mistake.. or im having a doubt.
Why is he taking only avg from 662-715, shldnt he like take the full loss collumn ?
It took 3 lessons for me to be compelled to write something in this forum.
Just a small contribution, since I am using AI assistance to learn about ML.
For those struggling to understand some concepts, I found this simple analogy absolutely brilliant:
" Imagine you’re trying to tune an old analogue radio to find a station. You have one knob (the weight). You turn it, listen to how much static there is (the loss), and decide which direction to turn it next. You keep adjusting until the music is clear. Now imagine a radio with a million knobs, all interacting with each other. That’s a neural network. The process of tuning is gradient descent."
I believe there’s piece missing from the quadratic gradient descent example. After calculating the gradient we must zero it or else the gradient accumulates. If we don’t do this the loss bounces up and down over many iterations no matter how small you make the learning rate.
with torch.no_grad(): abc -= abc.grad * alpha
should be
with torch.no_grad():
abc -= abc.grad * alpha
# --- THE FIX ---
abc.grad.zero_()
# ----------------
Interesting to note that not zeroing out the gradient is called out as a strategy to deal with training using large models on smaller GPUs (you actually do still have to zero out the gradient, but not after every batch).