Hey guys this is Ajay, i have a doubt regarding the weights of a model. so basically the sources i came through including fast ai’s book says weights are some kind of parameters which says how important a feature is in the neural network, and an another sections says weights are tunable parameters which govern’s the model’s learning. so what weights are actually?
I don’t have excel and Apple’s numbers app doesn’t have the functionality needed for gradient descent so I tried doing this in Python.
Hello,
Can someone please explain this excerpt from the Jupyter notebook on gradient descent as -
The basic idea is this: if we know the gradient of our
mae()function with respect to our parameters,a,b, andc, then that means we know how adjusting (for instance)awill change the value ofmae(). If, say,ahas a negative gradient, then we know that increasingawill decreasemae(). Then we know that’s what we need to do, since we trying to makemae()as low as possible.
Specifically, I did not understand -
If, say,
ahas a negative gradient, then we know that increasingawill decreasemae().
How did we derive this conclusion? How can a have a negative gradient? a is just a fixed number in the quadratic right?
I did not understand how a negative sign of the gradient should intuitively mean that we need to increase our parameters. If anyone can provide an explanation, it would be really helpful!
Hi,
Here, when we say a’s gradient, we mean gradient of loss with respect to a. loss is calculated from calling mae. In Pytorch, we can type a.grad to get the gradient of loss with respect to a.
Also, negative gradient means negative slope, so we increase the parameter. If it doesn’t make sense, it might be helpful to watch videos on calculus on Khan Academy Unit 2, which covers derivatives.
1 Like
I’m struggling to figure out why Jeremy changed total loss function from sum of individual losses to average of them in the Titanic excel example. Does anyone know why?
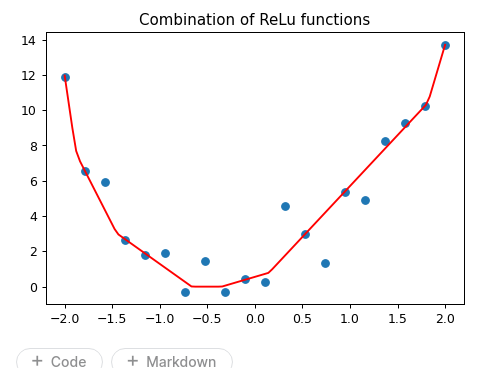
The “sum of ReLu” function made sense but I found it tricky to find combinations of parameters to demonstrate the point that Jeremy made that it can be used to create any arbitrary squiggly line. In the end I figured out a good set of parameters to approximate a quadratic function using a ReLu sum function and using this to initialize the parameters, I could fit a nice line to the quadratic using a sum of 100 ReLus. Code is here (bottom half of the notebook) and here’s what it looks like:
How familiar are you with derivatives? If you aren’t, I do recommend brushing up on how they function.
To answer your question about your confusion, when we take the gradient of a parameter, we are looking to see how much the value (here that would be mae()) would change each time we slightly increase a, b, or c separately (similar to how a derivative works). The conclusion is baked into the math itself. If ‘a’ had a positive gradient then we would decrease it to lower mae(). And the code also does this by subtracting the gradient times the learning rate.
Another syntax question:
I looked up res.max(a) and I found that it simply returns the maximum value of the input a. How is it that res.max(tensor(0.0)) doesn’t only return the max, but actually replaces any negative values?
How to call learn.predict() ?
Hello guys,
I created a learner following fastbook notebook 04_mnist_basics.ipynb to distinguish photo 3 and photo 7.
All the steps are good except calling learn.predict().
What data type should be sent to predict() ? A image or a file path ?
I tried all those, but both return error.
Here is my basic code.
# download data
path = untar_data(URLs.MNIST_SAMPLE)
Path.BASE_PATH = path
# generate paths
threes = (path/'train'/'3').ls().sorted()
sevens = (path/'train'/'7').ls().sorted()
seven_tensors = [tensor(Image.open(o)) for o in sevens]
three_tensors = [tensor(Image.open(o)) for o in threes]
stacked_sevens = torch.stack(seven_tensors).float()/255
stacked_threes = torch.stack(three_tensors).float()/255
valid_3_tens = torch.stack([tensor(Image.open(o))
for o in (path/'valid'/'3').ls()])
valid_3_tens = valid_3_tens.float()/255
valid_7_tens = torch.stack([tensor(Image.open(o))
for o in (path/'valid'/'7').ls()])
valid_7_tens = valid_7_tens.float()/255
# train data set
train_x = torch.cat([stacked_threes, stacked_sevens]).view(-1, 28*28)
train_y = tensor([1]*len(threes) + [0]*len(sevens)).unsqueeze(1)
dset = list(zip(train_x,train_y))
# valid data set
valid_x = torch.cat([valid_3_tens, valid_7_tens]).view(-1, 28*28)
valid_y = tensor([1]*len(valid_3_tens) + [0]*len(valid_7_tens)).unsqueeze(1)
valid_dset = list(zip(valid_x,valid_y))
# loss function
def mnist_loss(predictions, targets):
predictions = predictions.sigmoid()
return torch.where(targets==1, 1-predictions, predictions).mean()
# function to calculate our validation accuracy:
def batch_accuracy(xb, yb):
preds = xb.sigmoid()
correct = (preds>0.5) == yb
return correct.float().mean()
dl = DataLoader(dset, batch_size=256)
valid_dl = DataLoader(valid_dset, batch_size=256)
dls = DataLoaders(dl, valid_dl)
learn = Learner(dls, nn.Linear(28*28,1), opt_func=SGD,
loss_func=mnist_loss, metrics=batch_accuracy)
learn.fit(10, lr=lr)
# predict on filepath failed
learn.predict(threes[0])
> TypeError: object of type 'PosixPath' has no len()
# predict on image failed too
learn.predict(PILImage.create(threes[0]))
> TypeError: object of type 'PILImage' has no len()
How can I predict?
1 Like
This is an interesting problem, I haven’t found a solution but here’s what I’ve found.
Here is the source code for learn.predict:
def predict(self, item, rm_type_tfms=None, with_input=False):
dl = self.dls.test_dl([item], rm_type_tfms=rm_type_tfms, num_workers=0)
inp,preds,_,dec_preds = self.get_preds(dl=dl, with_input=True, with_decoded=True)
i = getattr(self.dls, 'n_inp', -1)
inp = (inp,) if i==1 else tuplify(inp)
dec = self.dls.decode_batch(inp + tuplify(dec_preds))[0]
dec_inp,dec_targ = map(detuplify, [dec[:i],dec[i:]])
res = dec_targ,dec_preds[0],preds[0]
if with_input: res = (dec_inp,) + res
return res
I took that source code, pasted it into a cell and ran the following (I ran your provided code first which gives me train_x):
item = train_x[0]
dl = learn.dls.test_dl([item], rm_type_tfms=None, num_workers=0)
inp,preds,_,dec_preds = learn.get_preds(dl=dl, with_input=True, with_decoded=True)
i = getattr(learn.dls, 'n_inp', -1)
inp = (inp,) if i==1 else tuplify(inp)
dec = learn.dls.decode_batch(inp + tuplify(dec_preds))[0]
dec_inp,dec_targ = map(detuplify, [dec[:i],dec[i:]])
res = dec_targ,dec_preds[0],preds[0]
This gives the following error:
IndexError: too many indices for tensor of dimension 0
for the following line of code:
inp,preds,_,dec_preds = learn.get_preds(dl=dl, with_input=True, with_decoded=True)
I found this Forums post which although isn’t technically related to your situation, I thought I would give it a try (unsqueeze the train_x[0] value):
item = train_x[0].unsqueeze(dim=0)
dl = learn.dls.test_dl([item], rm_type_tfms=None, num_workers=0)
inp,preds,_,dec_preds = learn.get_preds(dl=dl, with_input=True, with_decoded=True)
i = getattr(learn.dls, 'n_inp', -1)
inp = (inp,) if i==1 else tuplify(inp)
dec = learn.dls.decode_batch(inp + tuplify(dec_preds))[0]
dec_inp,dec_targ = map(detuplify, [dec[:i],dec[i:]])
res = dec_targ,dec_preds[0],preds[0]
This resolved the initial error but gave a new error:
AttributeError: 'list' object has no attribute 'decode_batch'
Caused by the following line:
dec = learn.dls.decode_batch(inp + tuplify(dec_preds))[0]
Looking at your DataLoaders, it doesn’t have a decode_batch attribute (I’m not sure why):

Here is a colab notebook with the code.
Dropping a few more related links that I found—note the last link where they have had the same issue but no resolution:
- IndexError with Focal Loss
- Learn.model input? (Tabular)
- Chapter 4 - Further research MNIST
- Beginners guide to MNIST with fast.ai | Kaggle
- MNIST image learner predict with fastai
Not sure if any of this helps but hopefully you can find a solution to this.
2 Likes
Thank you!
although the problem still unresolved, I found a clue too.
looks like activation() and decodes() need to be created properly for loss_func().
1 Like
Hugging Face & Github Synchronization
I am able to push my app.py, requirement.txt and all other require files to my Hugging Face Space. But I want to know how can we push those file simultaneously to Github repo also. I am using Github Desktop.
My apologies if this has been discussed earlier. I didn’t quite get why, to reduce the loss (when initial gradient values were negative in the video here, we subtract grad0.01:
abc -= abc.grad0.01
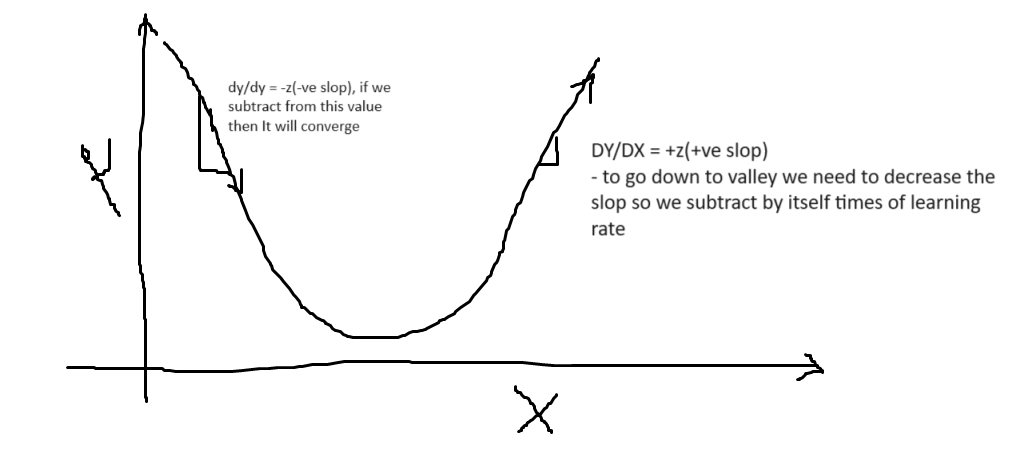
check this image this will help you to understand the point
you should check out algebra course, just check the basic topics
1 Like
People are quiet unactive on this course, not sure if anyone get this issue before or I am the first one, who get this,
when I check the timm there were change in names as of not it is
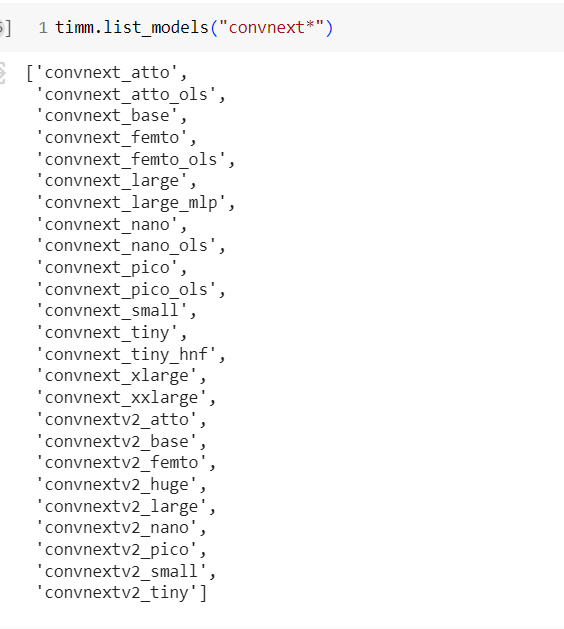
while I am trying to use “convnext_tiny”, but get some error,
but it says timm is not defined
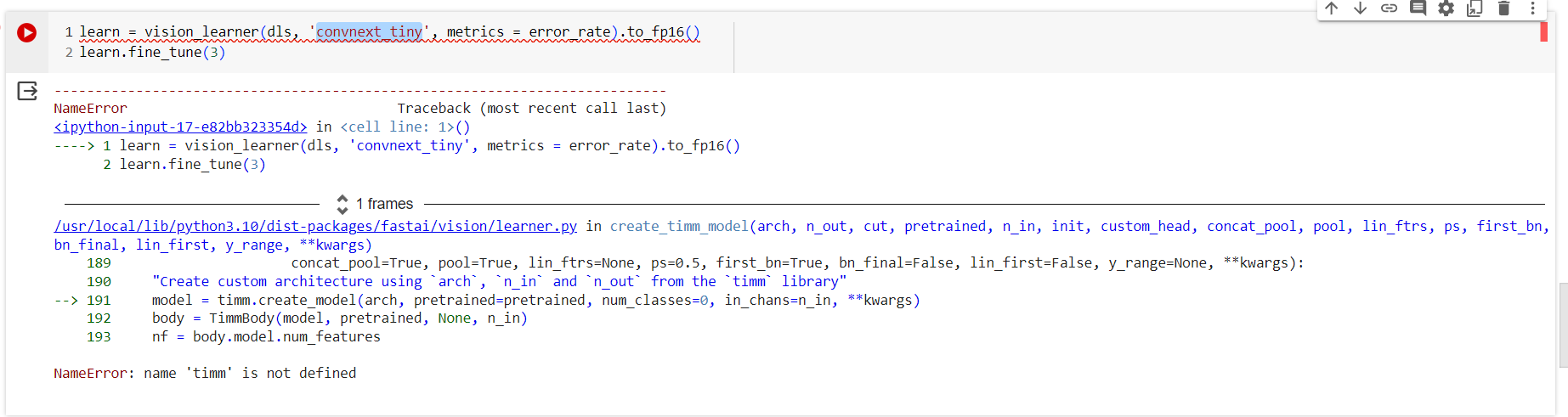
This forum post might help.
1 Like
I struggled with the same problem today and have just found the solution:
learn.model(valid_x[0])
1 Like
Hey, I struggled with the same problem today and have just found the solution:
learn.model(valid_x[0])
2 Likes
I’ve just complete the 4th chapter of the book. The final model there has the following structure:
simple_net = nn.Sequential(
nn.Linear(28*28,30),
nn.ReLU(),
nn.Linear(30,1)
)
We performed normalization on the input to the first linear layer by normalizing the image pixel data. However, there’s no normalization applied to the input of the second layer; values greater than 1 are present after the ReLU activation.
Can anyone explain the reasoning behind this?
Use learn.model(x)