In lesson 3’s planet notebook, Jeremy mentioned a way to resize the original images after training for some time to make use of the trained model like a pre-trained network, and then training further to improve results.
However, when the image is resized, how does the pre-trained model adjust for the different input size in the first layer? Looked at the source code for create_cnn but still don’t really understand how the first layer adapts to the change in input size.
I think fastai handles this for you through something called adaptive pooling that pytorch has.
Some intuition is when you think about the convolution operation (e.g. of a 2x2 filter), when the image size increases (e.g from 128x128 to 256x256) it simply has more strides to take.
The output of that conv layer then has more elements than before. What I understand is that adaptive pooling will cater for this so that the ‘size requirement’ of images is not really an artificial constraint.
@adi_pradhan Thanks for that answer, it makes sense. Do you know where the “magic” happens in the source code? So far, I’ve been unsuccessful in finding where fastai calls the adaptive pooling.
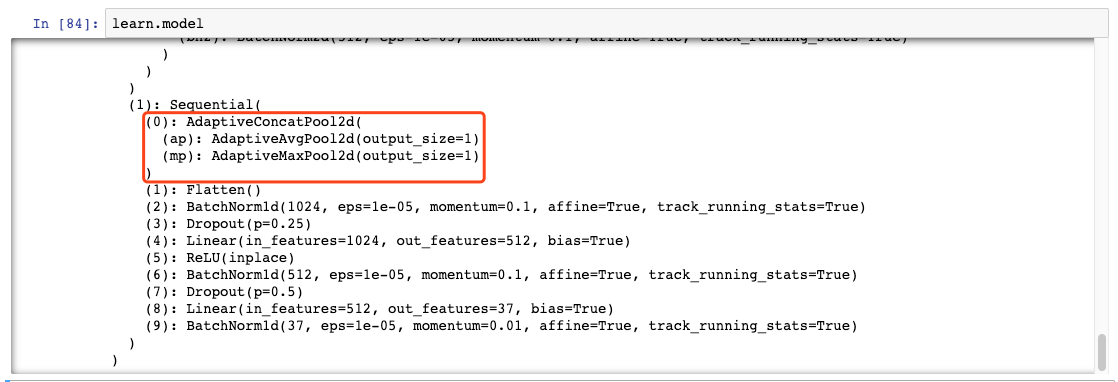
In addition, I found that there is an adaptive pooling layer at the end of ResNet model I believe is the key component that makes it adaptable to different size of input data.
No matter what size of input come through to the last sequential, these layers do the average pooling and maximum pooling to it and then concatenate them into a (1 x 1 x 1024) tensor. So it can follow the rest layers to generate output.