Questions and comments on lesson 3 here 
Wiki page: http://wiki.fast.ai/index.php/Lesson_3
Video: https://youtu.be/6kwQEBMandw
Questions and comments on lesson 3 here
Wiki page: http://wiki.fast.ai/index.php/Lesson_3
Video: https://youtu.be/6kwQEBMandw
When will the lesson3 notebook be in http://www.platform.ai/files/nbs/ ?
Tomorrow morning.
Thanks @jeremy One thing I noticed during class is your use of Adam as your optimizer (1:55:27 in the video). My understanding is that RMSProp, Adam and the other optimizers in Keras are basically “smarter” variants of gradient descent in that they adapt the learning rate based on the curvature of the loss function. Is my understanding correct? In fact, I used Nadam last week to help me achieve 17th (now 18th) place in the Cats vs. Dogs competition. It seemed to converge quite quickly.
I’ve also noticed the weights for for ResNet50 in http://www.platform.ai/files/ Is that a hint for us to try it?  I actually tried Keras’ ResNet50 implementation but it didn’t seem to help much, surprisingly.
I actually tried Keras’ ResNet50 implementation but it didn’t seem to help much, surprisingly.
Very timely questions - we’ll be learning about resnet and SGD improvements next week! Yes please do try them if you are interested…
PS: Nice Cats v Dogs result!
on lesson3 notebook, it seems that we need to create a new model class and save it in a python file 'vgg_ft.py’
If that is the case, i’m thinking that maybe I can copy the current vgg16.py and update it with some of the changes shown in lesson1 and lesson2ontebooks. Am I in the right track?
Thanks
The code in the notebook doesn’t work as given because the call to set_weights is copying from the last MaxPooling2D layer into the new Dense layer. I think somebody pointed this out in the class? Hopefully I can fix!
fc_model = get_fc_model()
---------------------------------------------------------------------------
Exception Traceback (most recent call last)
<ipython-input-21-e9cf85a7e40b> in <module>()
----> 1 fc_model = get_fc_model()
<ipython-input-20-976fc71a155c> in get_fc_model()
8 ])
9
---> 10 for l1,l2 in zip(model.layers, fc_layers): l1.set_weights(proc_wgts(l2))
11
12 model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
/home/ubuntu/anaconda2/lib/python2.7/site-packages/keras/engine/topology.pyc in set_weights(self, weights)
877 '" with a weight list of length ' + str(len(weights)) +
878 ', but the layer was expecting ' + str(len(params)) +
--> 879 ' weights. Provided weights: ' + str(weights)[:50] + '...')
880 if not params:
881 return
Exception: You called `set_weights(weights)` on layer "dense_5" with a weight list of length 0, but the layer was expecting 2 weights. Provided weights: []...
@mr.sarno2 vgg_ft() is a method I added to utils.py - grab the latest from platform.ai if you like, or better still, write your own version of the function (it should create a new fine-tuned vgg model with the requested number of output activations).
Good point. I’ve uploaded the fixed version. FYI it just needed these layers added to the front:
MaxPooling2D(input_shape=conv_layers[-1].output_shape[1:]),
Flatten(),
(Originally I included these layers in the saved features, but I later decided this was reducing the flexibility of what I could do with the saved features.)
From below, does that mean the validation accuracy is not derived from the same model (with dropouts) that the training data accuracy is measured from?
Dropout refers to a layer that randomly deletes (i.e. sets to zero) each activation in the previous layer with probability p
(generally 0.5). This only happens during training, not when
calculating the accuracy on the validation set, which is why the
validation set can show higher accuracy than the training set.
The utils.py was last updated on Oct 24 … I did not see vgg_ft() …
Check vgg16.zip
Apologies I put them in the wrong directory. They’re in the right spot now
The architecture and weights are the same between test and train, but it’s handled differently - during training the dropout is done, but during test it is not. So you’ll see you often have higher accuracy on your validation set than test set during training.
I guess
validation_data=(val_features, val_labels))```
does the switching on and off of dropouts automatically from training to validation phase?Yes that’s right. Keras only enables dropout during training.
I downloaded the latest utils.py, this seems to have taken a new dependency on openCV, this library is not installed in my image, has anyone else seen this problem too?
/home/ubuntu/as/dl/ai/nbs/utils.py in ()
9 import PIL
10 from PIL import Image
—> 11 import cv2
12 from numpy.random import random, permutation, randn, normal, uniform
13 from scipy import misc, ndimage
ImportError: No module named cv2
Feel free to remove that import and whatever is using it - or else just ‘conda install opencv’ would probably fix the problem.
We spent a bit of time in the last lecture talking about over-fitting. I made a wiki page with some of the topics we covered here. it’s not currently mentioned on the lesson 3 wiki page, so feel free to add a link if you think it’s relevant Jeremy!
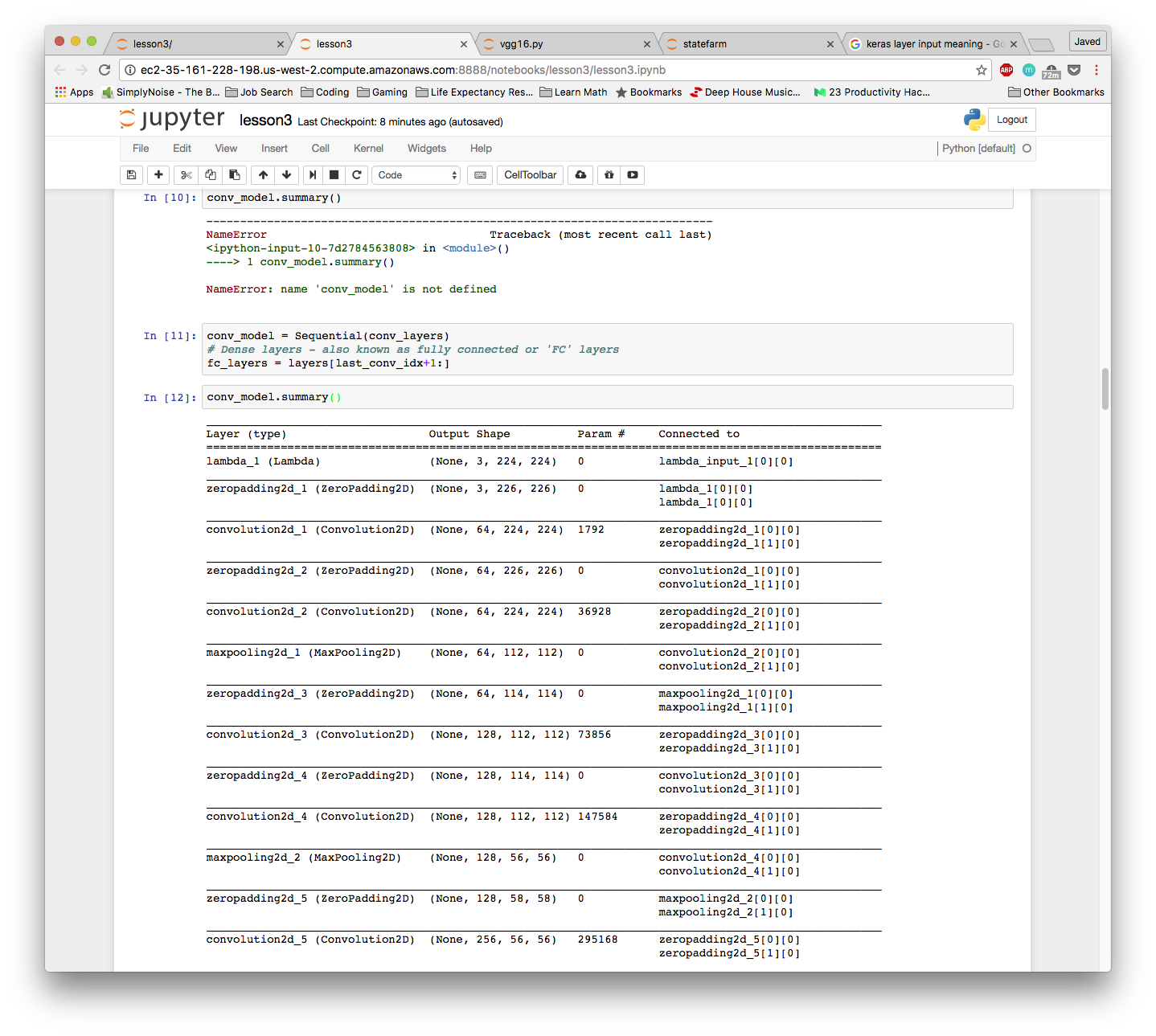
When I’m putting the convolution layers in their own model, for some reason, it keeps showing double layers under “connected to” Please see the screenshot. The whole thing seems to work ok, so not sure if this is a problem, but it seems wrong.
I shut down and reset the jupyter notebook, so I don’t think this is coming from adding the same layers multiple times. The screenshot is the first time I’ve run that cell since restarting the notebook. When I do summary on the original model, it single lines under ‘connected to’. When I print the conv_layers, it shows just a single copy of each layer as it should. Really not sure why this is happening.
Any idea why I could be getting double entries under “connected to” like this? Seems to work ok, so does it matter? Thanks.