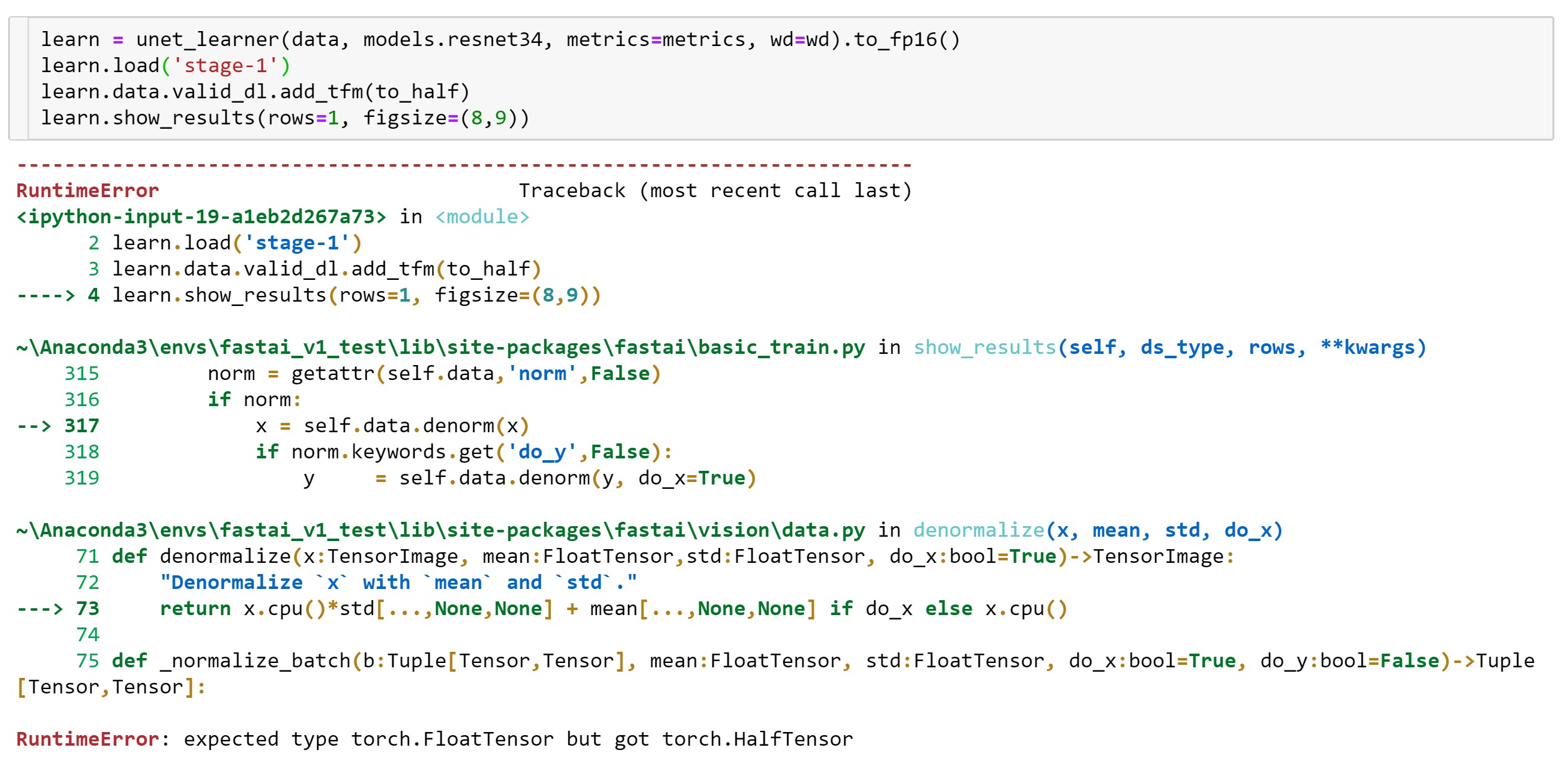
Hello,
When I try to run the Big version of images in lesson3-camvid.ipynb notebook in half-precision to avoid memory problems (as I am using 1080ti):
learn = Learner.create_unet(data, models.resnet34, metrics=metrics).to_fp16()
everything trains fine, and I get a pretty good 0.93 accuracy. But when I call learn.show_results(), I get the following error:
RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.cuda.HalfTensor) should be the same
Any suggestions on how to fix this?
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-46-c3b657dcc9ae> in <module>()
----> 1 learn.show_results()
~/anaconda3/envs/fastaiv1/lib/python3.7/site-packages/fastai/vision/learner.py in show_results(self, ds_type, rows, figsize)
47 def show_results(self, ds_type=DatasetType.Valid, rows:int=3, figsize:Tuple[int,int]=None):
48 dl = self.dl(ds_type)
---> 49 preds = self.pred_batch()
50 figsize = ifnone(figsize, (8,3*rows))
51 _,axs = plt.subplots(rows, 2, figsize=figsize)
~/anaconda3/envs/fastaiv1/lib/python3.7/site-packages/fastai/basic_train.py in pred_batch(self, ds_type, pbar)
216 nw = dl.num_workers
217 dl.num_workers = 0
--> 218 preds,_ = self.get_preds(ds_type, with_loss=False, n_batch=1, pbar=pbar)
219 dl.num_workers = nw
220 return preds
~/anaconda3/envs/fastaiv1/lib/python3.7/site-packages/fastai/basic_train.py in get_preds(self, ds_type, with_loss, n_batch, pbar)
209 lf = self.loss_func if with_loss else None
210 return get_preds(self.model, self.dl(ds_type), cb_handler=CallbackHandler(self.callbacks),
--> 211 activ=_loss_func2activ(self.loss_func), loss_func=lf, n_batch=n_batch, pbar=pbar)
212
213 def pred_batch(self, ds_type:DatasetType=DatasetType.Valid, pbar:Optional[PBar]=None) -> List[Tensor]:
~/anaconda3/envs/fastaiv1/lib/python3.7/site-packages/fastai/basic_train.py in get_preds(model, dl, pbar, cb_handler, activ, loss_func, n_batch)
36 "Tuple of predictions and targets, and optional losses (if `loss_func`) using `dl`, max batches `n_batch`."
37 res = [torch.cat(o).cpu() for o in
---> 38 zip(*validate(model, dl, cb_handler=cb_handler, pbar=pbar, average=False, n_batch=n_batch))]
39 if loss_func is not None: res.append(calc_loss(res[0], res[1], loss_func))
40 if activ is not None: res[0] = activ(res[0])
~/anaconda3/envs/fastaiv1/lib/python3.7/site-packages/fastai/basic_train.py in validate(model, dl, loss_func, cb_handler, pbar, average, n_batch)
49 for xb,yb in progress_bar(dl, parent=pbar, leave=(pbar is not None)):
50 if cb_handler: xb, yb = cb_handler.on_batch_begin(xb, yb, train=False)
---> 51 val_losses.append(loss_batch(model, xb, yb, loss_func, cb_handler=cb_handler))
52 if not is_listy(yb): yb = [yb]
53 nums.append(yb[0].shape[0])
~/anaconda3/envs/fastaiv1/lib/python3.7/site-packages/fastai/basic_train.py in loss_batch(model, xb, yb, loss_func, opt, cb_handler)
16 if not is_listy(xb): xb = [xb]
17 if not is_listy(yb): yb = [yb]
---> 18 out = model(*xb)
19 out = cb_handler.on_loss_begin(out)
20
~/anaconda3/envs/fastaiv1/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
477 result = self._slow_forward(*input, **kwargs)
478 else:
--> 479 result = self.forward(*input, **kwargs)
480 for hook in self._forward_hooks.values():
481 hook_result = hook(self, input, result)
~/anaconda3/envs/fastaiv1/lib/python3.7/site-packages/torch/nn/modules/container.py in forward(self, input)
90 def forward(self, input):
91 for module in self._modules.values():
---> 92 input = module(input)
93 return input
94
~/anaconda3/envs/fastaiv1/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
477 result = self._slow_forward(*input, **kwargs)
478 else:
--> 479 result = self.forward(*input, **kwargs)
480 for hook in self._forward_hooks.values():
481 hook_result = hook(self, input, result)
~/anaconda3/envs/fastaiv1/lib/python3.7/site-packages/torch/nn/modules/container.py in forward(self, input)
90 def forward(self, input):
91 for module in self._modules.values():
---> 92 input = module(input)
93 return input
94
~/anaconda3/envs/fastaiv1/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
477 result = self._slow_forward(*input, **kwargs)
478 else:
--> 479 result = self.forward(*input, **kwargs)
480 for hook in self._forward_hooks.values():
481 hook_result = hook(self, input, result)
~/anaconda3/envs/fastaiv1/lib/python3.7/site-packages/torch/nn/modules/conv.py in forward(self, input)
311 def forward(self, input):
312 return F.conv2d(input, self.weight, self.bias, self.stride,
--> 313 self.padding, self.dilation, self.groups)
314
315
RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.cuda.HalfTensor) should be the same