You probably want to use the code and the search_images function listed in this notebook. Note that it’s part of step 1 and you might need to ‘unhide’ the specific code for the function.
Thanks @strickvl ! I was just trying the vanilla fastbook notebook. I should’ve looked at the birds notebook (in fact I did that whole notebook just the other day )
Sometimes because kaggle has so many packages installed they can clobber each other. In this case it looks like somehow typing-extensions is expected to be there, but isn’t, so try pip -Uqq install typing-extensions.
I’m having trouble getting my model to train properly. The training loss is low but validation loss is high (meaning if overfit if I remember corrrectly). Would love some advice!
In the mean time, I’ll try adding more data as each mineral species can have many different shapes and colors.
I go with option b.
During training for dog images snake and OTHER responses are driven down and similarly for snake images , dog and OTHER are driven down. For a house image both snake and dog have low response while OTHER which has not trained to be high or low for OTHER images will also have a low response. So all 3 low responses resulting in ~ [0.3,0.3,0.3]
Would love to see the actual answer revealed.
I guess that LR landscape isn’t great and the epochs look to just be getting worse.
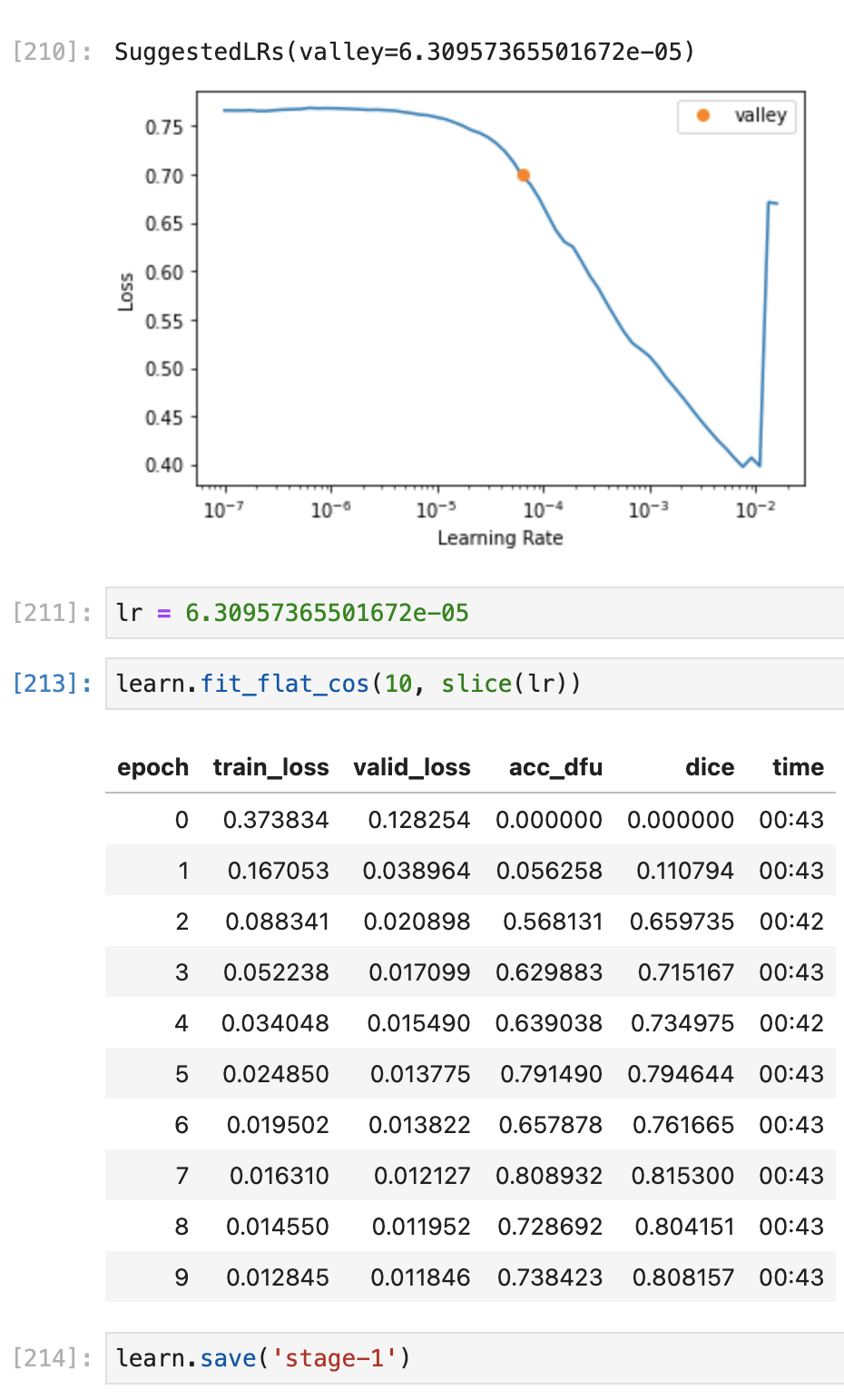
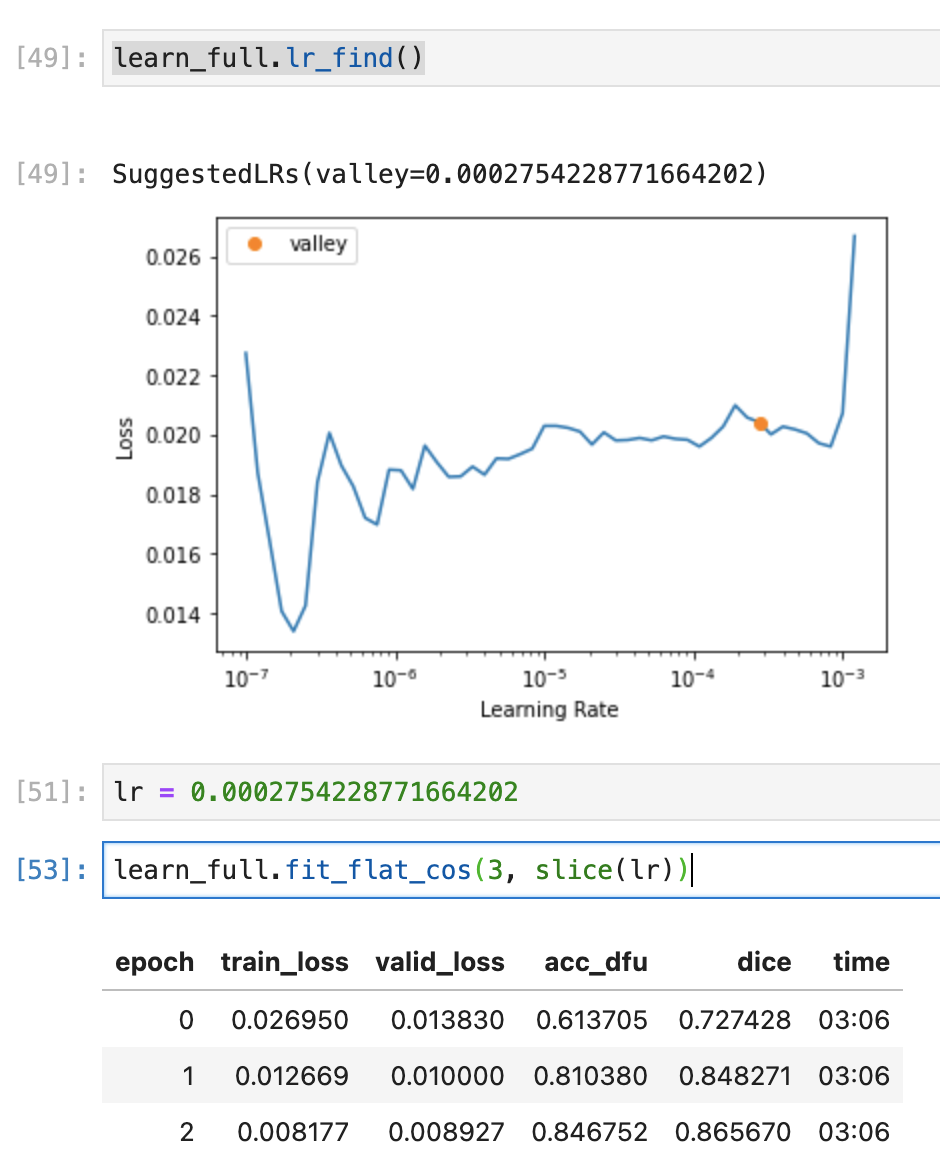
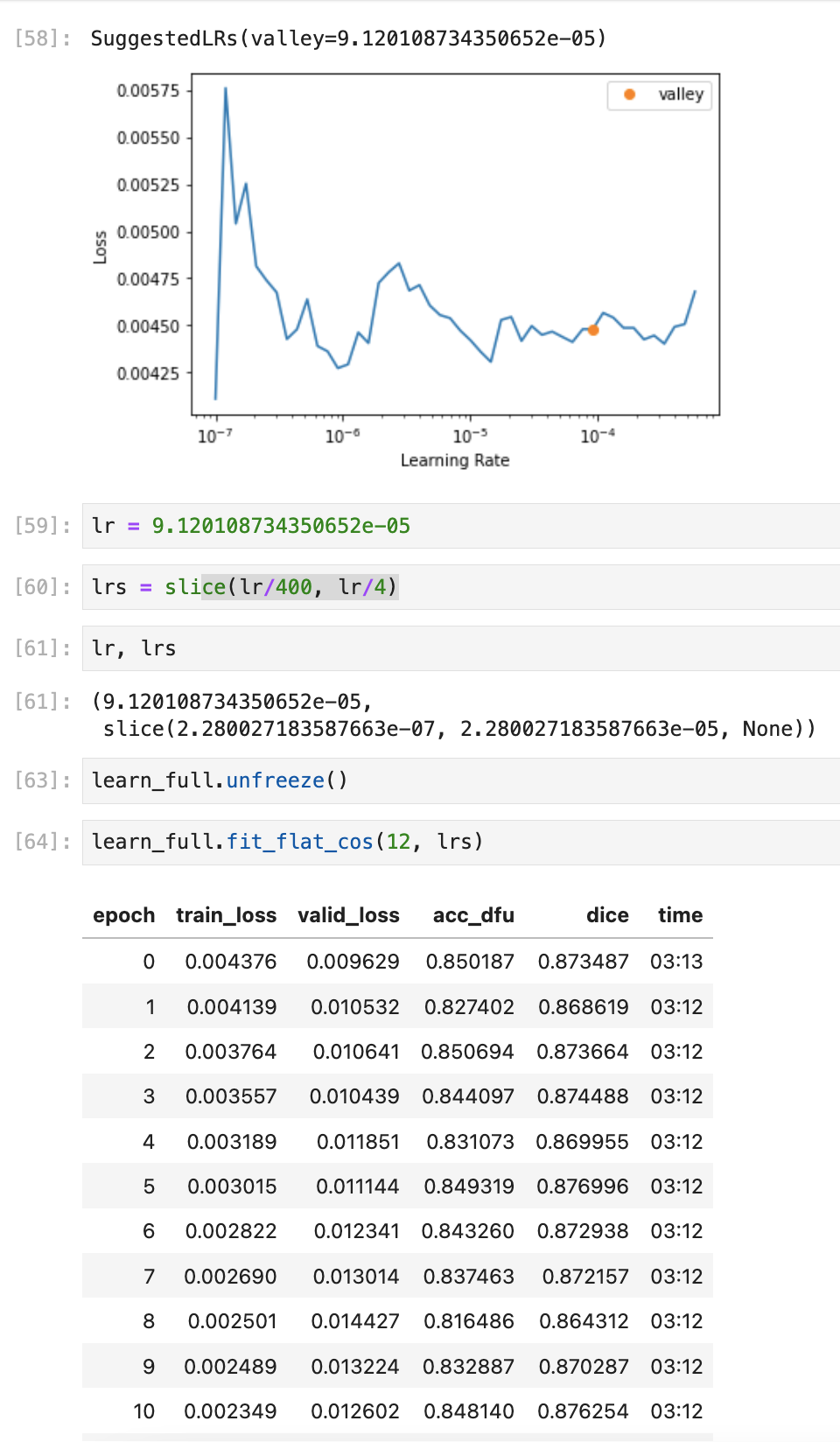
So, I guess im getting around 0.87 DICE on the Validation set which isn’t bad. Does anyone know how can I run this against the test images and calculate a Dice score against them all?
although only having a localhost url (127.0.0.1) is not much use.
At least Colab provides a public-url (see below).
[Edit:] From poking around I discovered that in kaggle adding share=True to launch() caused a public-url to be generated. Interesting that flag wasn’t required for Colab.
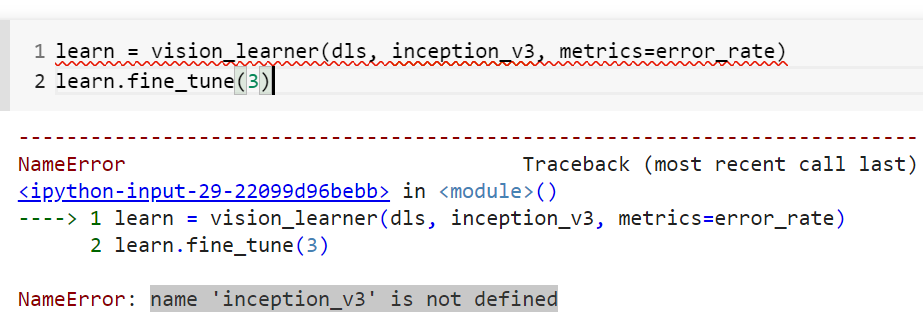
Do we have any resource where we can see all the pre-trained models that can be passed to fastai model API.
For e.g., here I am trying to pass inception_v3. it throws an error —
Hi all, I have a question. When should we use learn.save() and learn.export()? It seems to me that the latter is more convenient to use than the former.
You need to enclose the name of the model in quotes. You can also use wildcard to find the model by using the following command from timm: timm.list_models('*densenet*')
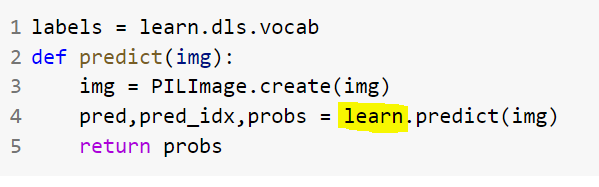
Learn.export() is used to save the trained model in pickle or .pth format.
The saved model can be used for inference purpose on new/unknown test data with predict method.
I am not very clear on learn.save(). Can someone please answer this.
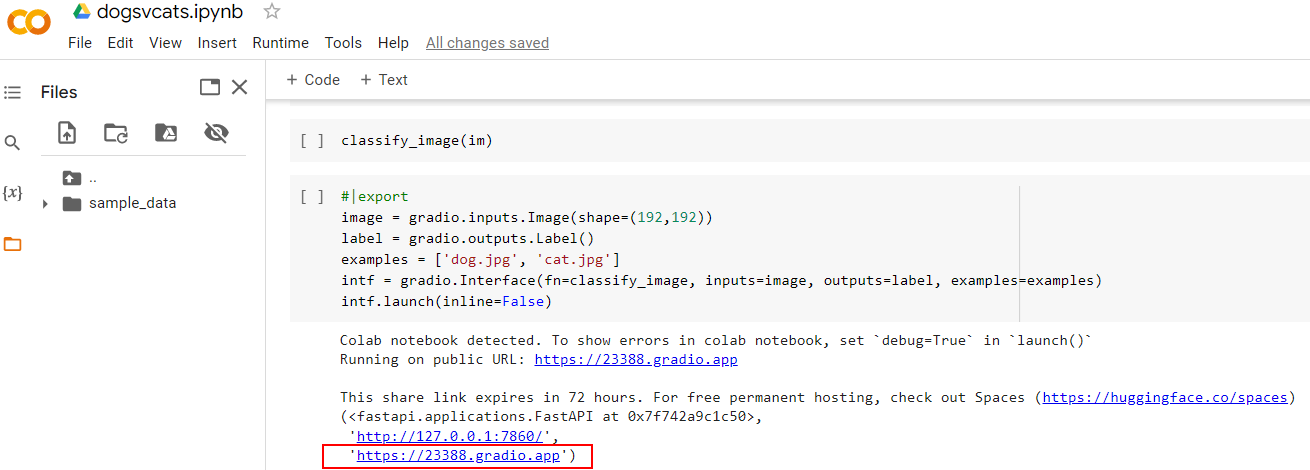
It wasn’t clear to me exactly how to run that, so pulling on that thread,
worked out from here, the following works well enough in a fresh notebook on kaggle…
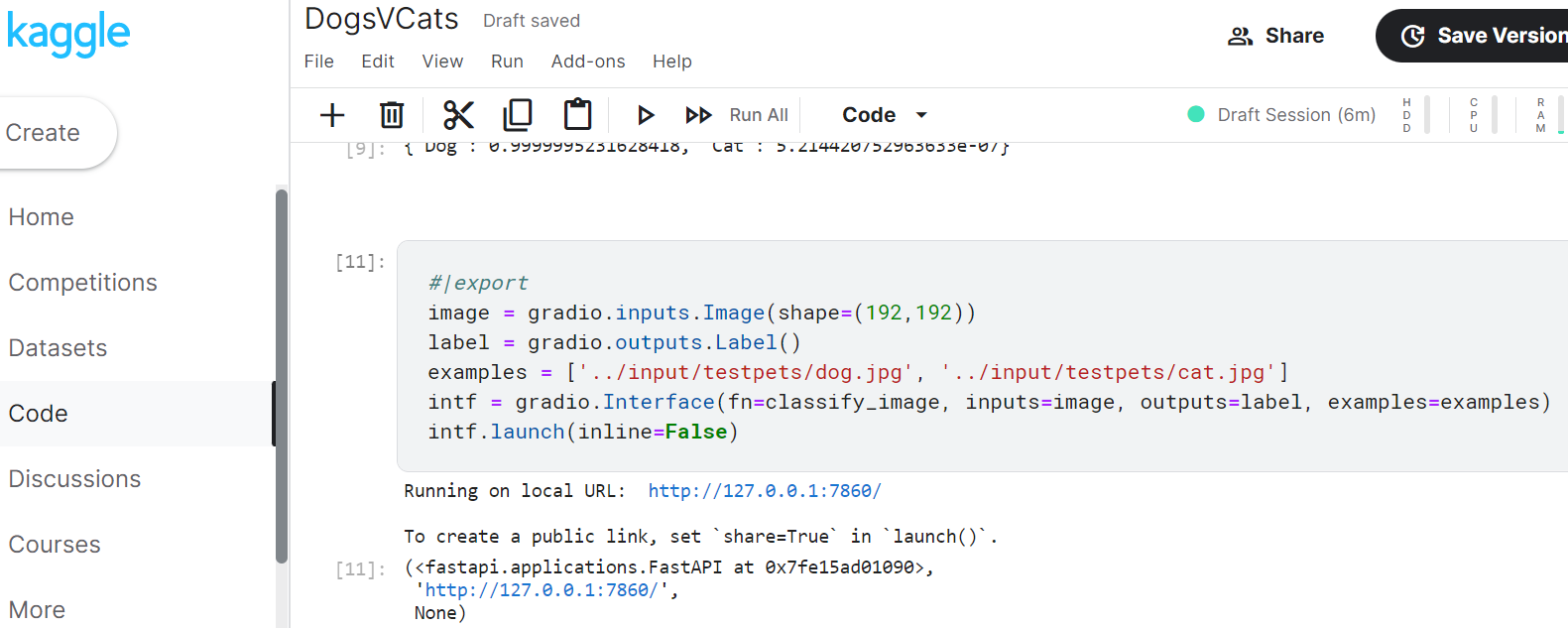
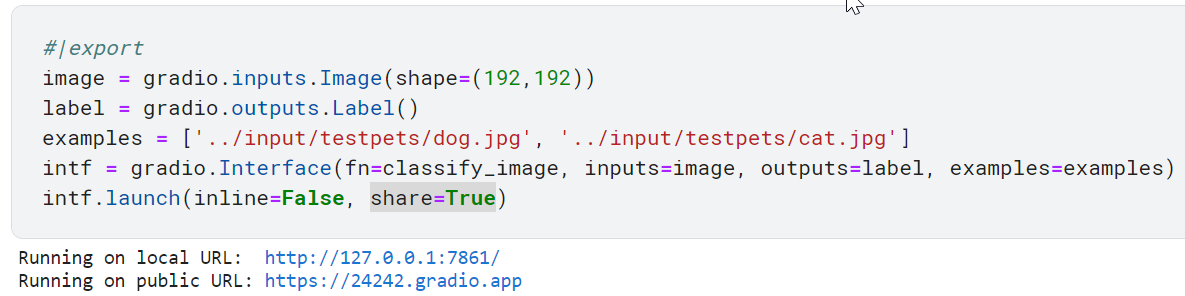
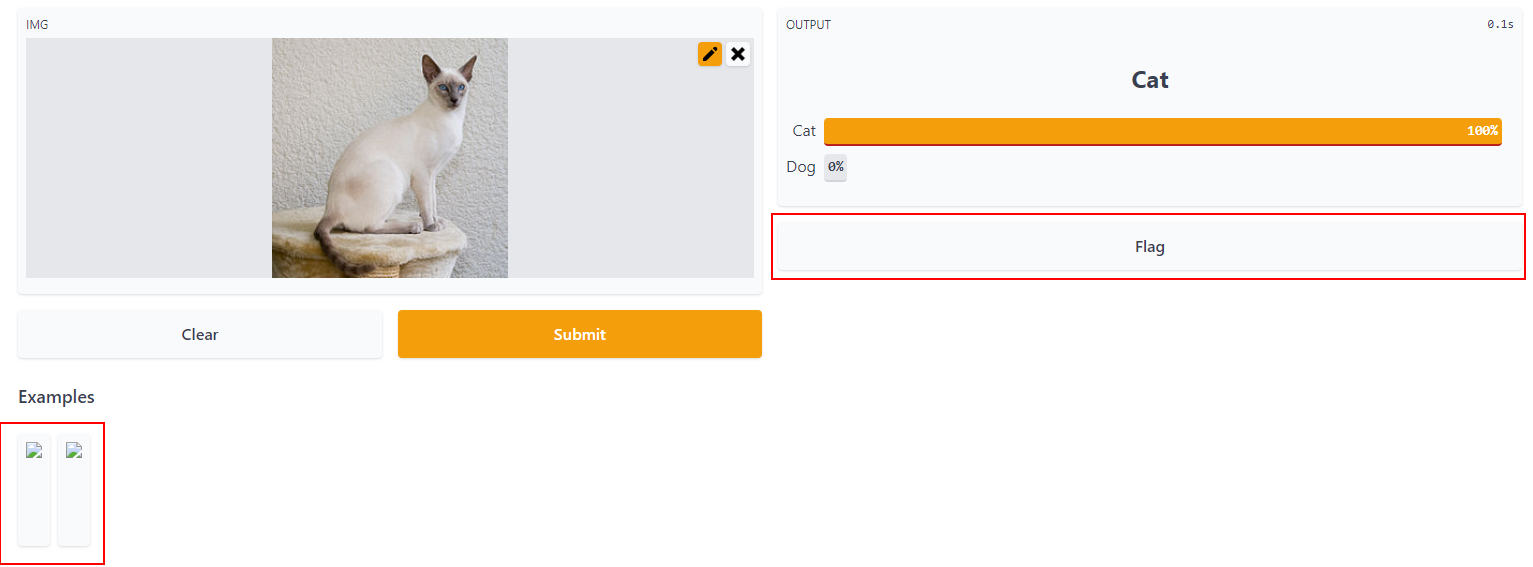
Yay! Here is my Cats V Dogs gradio app launched from kaggle.
But I can’t quickly determine why the Flag button is shown (i.e. where it is defined),
or why my two example photos don’t show.
Having a low training loss but high validation loss does not necessarily mean that your model is already overfitting. This is a point of confusion for most of us when starting out and trying to understand these ideas.
As mentioned in the book; when the validation set accuracy stops getting better, and instead goes in the opposite direction and gets worse, that is when you can start thinking that the model is starting to memorize the training set rather than generalize, and has started to overfit.
Taken straight from the book, Chapter 1 :
In other words, as you progress further on the training, once the validation loss starts getting consistently worse than what it was before, (and hence meaning that it’s not able to generalize as well to unseen data, while getting better on training data) then the model has started to overfit.
Not to be taken as an exact example, but I’ve tried to quickly sketch out what this could mean in practice.

 )
)