Hi @ilovescience,
thanks, but are you referring to this?
learn.model = torch.nn.DataParallel(learn.model, device_ids=[0, 1])
or this
Learner.to_parallel(device_ids =[0,1])
Hi @ilovescience,
thanks, but are you referring to this?
learn.model = torch.nn.DataParallel(learn.model, device_ids=[0, 1])
or this
Learner.to_parallel(device_ids =[0,1])
Hi @jeremy,
Thanks, but nn.Distributed is not used to train when you have multiple computers?
I hit this problem going through the binder example from the 2020 course. Sorry to say I didn’t solve it. Since 2022 changed to HuggingFace, so I did I (but only half way through it before sleep overcame me).
p.s. a sometime useful principle… If you can’t solve the problem, change the problem! 
You can use torch.nn.parallel.DistributedDataParallel on both single computer as well as multiple computers. Check the Pytorch docs here.
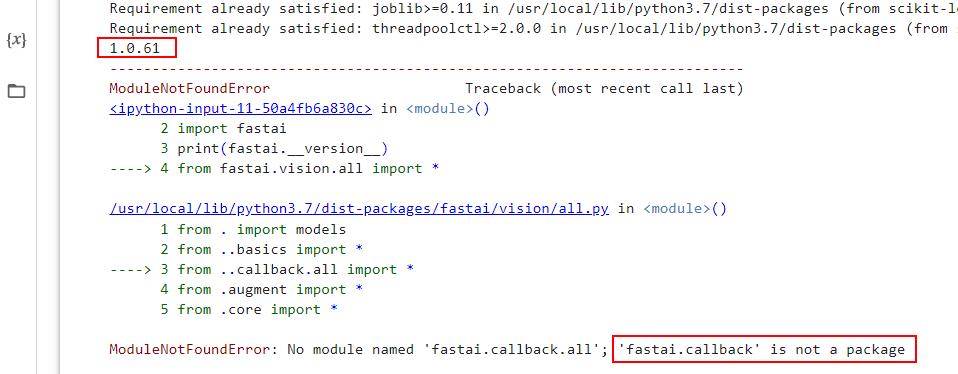
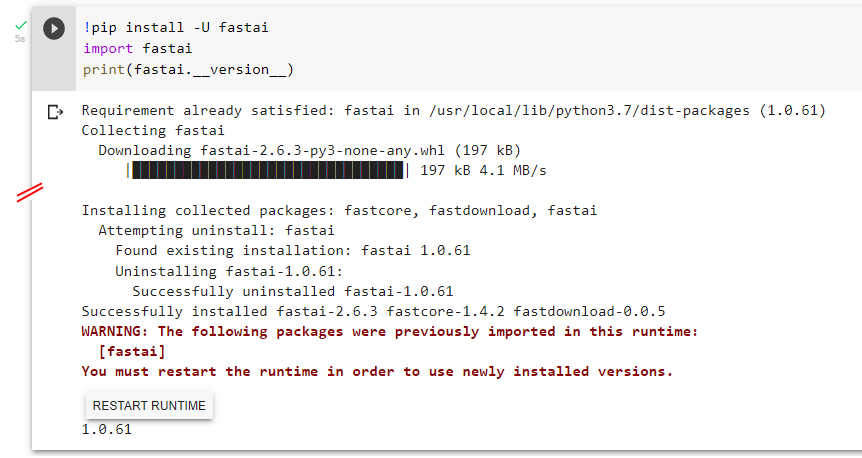
Okay, I bumped into this error again. This time I managed to solve it, but there is some residual strange behaviour subsequently stopping me from reproducing the error, so I don’t fully comprehend the system.
Sorry I lost the reference, but someone else had this error because they were using fast.ai.v1 and IIUC callbacks are part of fast.ai.v2.
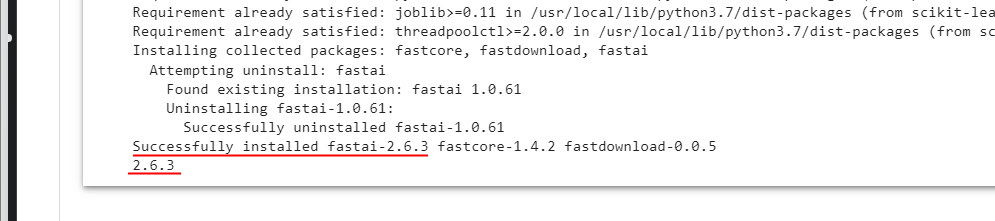
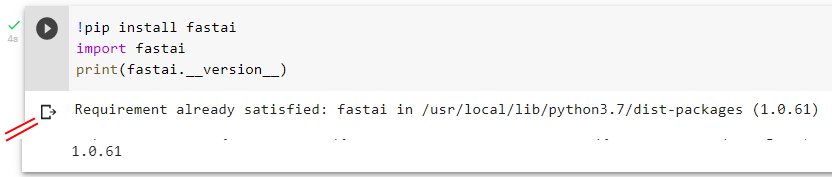
It turns out that !pip install -U fastai seems to only upgrade to latest minor revision, i.e. it doesn’t upgrade from v1 to v2.
Here is my record of that…
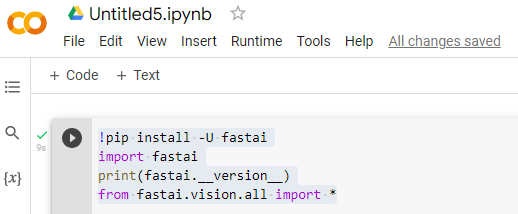
The reference I found used 2.0.19, so I did too, thus the following…
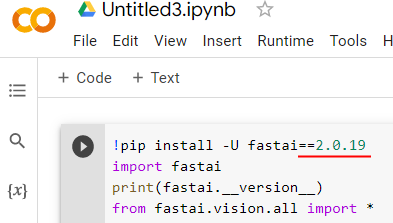
After clicking that RESTART RUNTIME button,
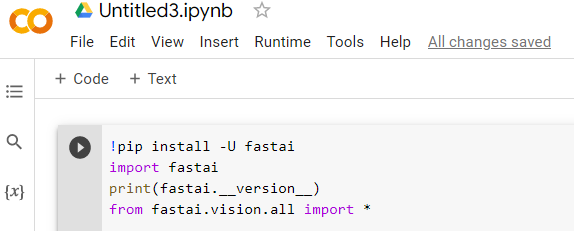
I no longer needed to specify the version to pip install…
Now, here is where it gets strange!
From my sysadmin days I carry the philosphy that "its not enough to solve the problem. You don’t really understand it until you can reliably re-break it.
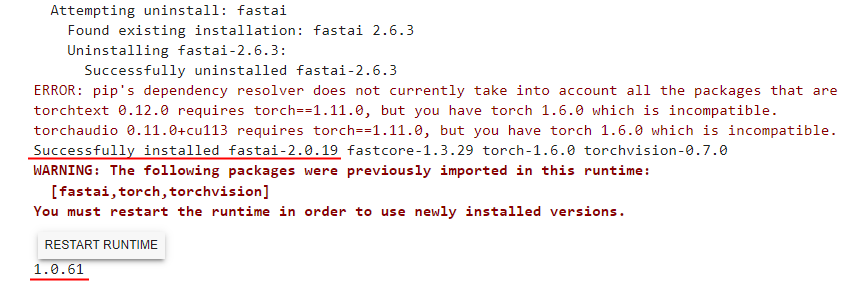
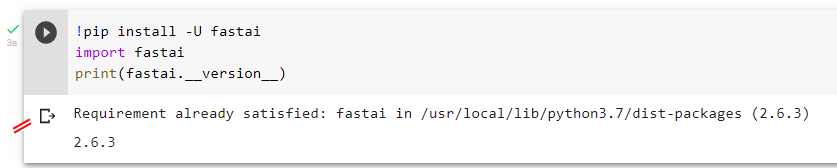
So I created a fresh new Notebook to rerun that last code, expecting to see 1.0.61 again, but nah!mate! The new notebook is already 2.6.3.
So perhaps my login is caching something? I started a new Chrome incognito window so that it would ask me to log in, which I did, and in a new notebook reran the last code, and… … …nah!mate! The notebook is already 2.6.3.
So perhaps my account is caching something? I got my daughter to log in, then reran the last code, and… The notebook is already 2.6.3.
btw, I use Chrome, so now I even started Microsoft Edge and logged into Colab again, and again its already 2.6.3.
So I’m stumped about that behaviour, but anyway it seems it wont matter going forward if my environment remains at 2.6.3.
As for the code used in the course, I think at minimum it they all need to include…
print(fastai.__version__)
to make any issues more visible.
Or maybe something like the following would work, but this is speculative since I was not able to experiment…
!pip install -U fastai>=2.0.0
[Edit…]
After I did Runtime > Change runtime type from None to GPU, when I reran code that had
!pip install -U fastai==2.6.3
the log indicated the session started on 1.0.61 and been successfully upgraded to 2.6.3.
But then
!pip install -U fastai
now retains 2.6.3 as its installed environment. Still annoying unclear, but I’ll move on.
Yes that’s the reason - all the notebooks in the book always start with some variant of this cell:
pip install -U fastai
It does upgrade from v1 to v2:
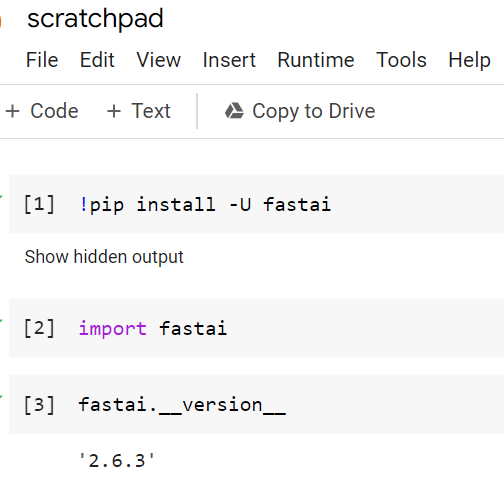
My guess is that you imported fastai before you did the pip install, which doesn’t work - python caches your imports. So you need to restart the runtime in colab if you accidentally import fastai before you pip install.
Excellent approach! ![]()
You can also just do Restart Runtime for it to override. I’ve never had to completely destroy it.
Yes good point - I’m probably being over-paranoid!
A question that came up while thinking through lesson 2…
Why do we even need item_tfms? If batch_tfms are a thing, and the GPU is so optimised for doing things in bulk, and faster etc, why would we ever use item_tfms?
Yes, Learner.to_parallel should do something very similar to what you were doing in your code. It adds the ParallelTrainer callback, here is the source code:
class ParallelTrainer(Callback):
"Wrap a model `DataParallel` automatically"
run_after,run_before = TrainEvalCallback,Recorder
def __init__(self, device_ids): self.device_ids = device_ids
def before_fit(self): self.learn.model = DataParallel(self.learn.model, device_ids=self.device_ids)
def after_fit(self): self.learn.model = self.learn.model.module
# Cell
@patch
def to_parallel(self: Learner, device_ids=None):
"Add `ParallelTrainer` callback to a `Learner`"
self.add_cb(ParallelTrainer(device_ids))
return self
I found this from a previous discussion:
Thanks! That is a great trick to know about.
I made one small change to Jeremy’s Kaggle NLP notebook from this:
model_nm = 'microsoft/deberta-v3-small'
To this:
model_nm = 'distilroberta-base'
The tokenizer with this model is different but was still working.
But then I get the following error during the first epoch after running >> trainer.train();
My kaggle notebook with the complete saved error message is here: https://www.kaggle.com/code/mattrosinski/getting-started-with-nlp-for-absolute-beginners
Reverting to 'microsoft/deberta-v3-small' fixes the problem but why does the trainer fail when using 'distilroberta-base'?
Maybe. Hard to think back yesterday to the heat of battle.
So I tried again today, keeping a close log of events.
TLDR; my experimenting is part of the problem. In a new notebook doing
only “-U” upgrade just works.
I had left the web page open, so I clicked <Reconnect>, then executed the following “A” sequence.
A1. On Colab, File > New notebook.
A2. Copied these three lines into single cell, without upgrade, executed cell…
A3. Changed to upgrade, executed cell…
A4. No change to code, executed cell without restart to see what happens…
(noting it doesn’t redo the 197 kb download)
A5. Restarted runtime…
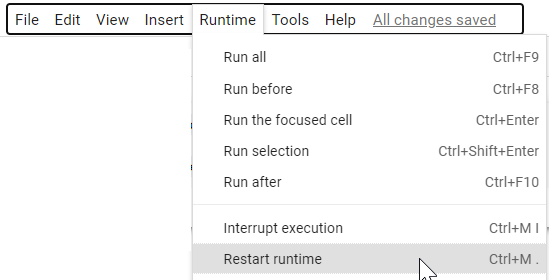
A6. Same code, executed cell…
Using only a single cell with the three lines shown, I’m sure import is never executed before the pip install within one run, but there is a subtle trap where pip install is influenced by the import of a previous run. This corner case may only happen to a few curious newcomers, who to observe the effect of different flags might experiment as follows…
B1. File > New notebook
B2. Execute this cell, “qq” flags without “U” flag, similar result to A2.
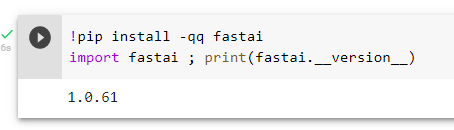
B3. Added “U” flag, executed cell, similar result to A3,
but no warning or button to restart runtime…
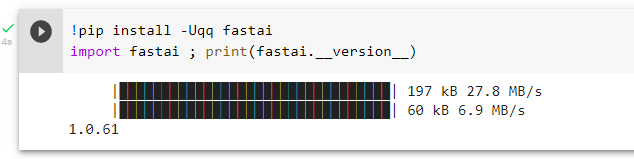
B4. Now, a naive user is stuck, with the following code never upgrading…
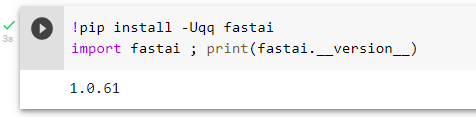
The worst thing of this trap is, it happens randomly to only a small number of newcomers, and without the visibility of loaded version the reported issue is not clear. When it randomly works again in a new notebook, there has still been frustration and eroding of confidence.
I think it may help if sample code displays the version, so newcomer error reports are clearer. Or even include a self-help comment…
!pip install -Uqq fastai
import fastai ; print(fastai.__version__) # if not v2, restart runtime.
.
btw, @houman.kargaran, did this help solve your problem, or did I just go off on a tangent?
Try changing the definition of corr to this:
def corr(x,y): return np.corrcoef(x.squeeze(),y)[0][1]
Then it should run.
I found this by running Python’s interactive debugger with %debug, and type up until I got to the code in this notebook. Then looking at the inputs I noticed x has shape (9919,1) whereas y is just (9919,).
We need a way to drop the extra dimension, and np.squeeze is nice because if x is already 1 dimensional it won’t change the value.
I have no idea why the shape of the model’s predictions (the x here) differs between models.
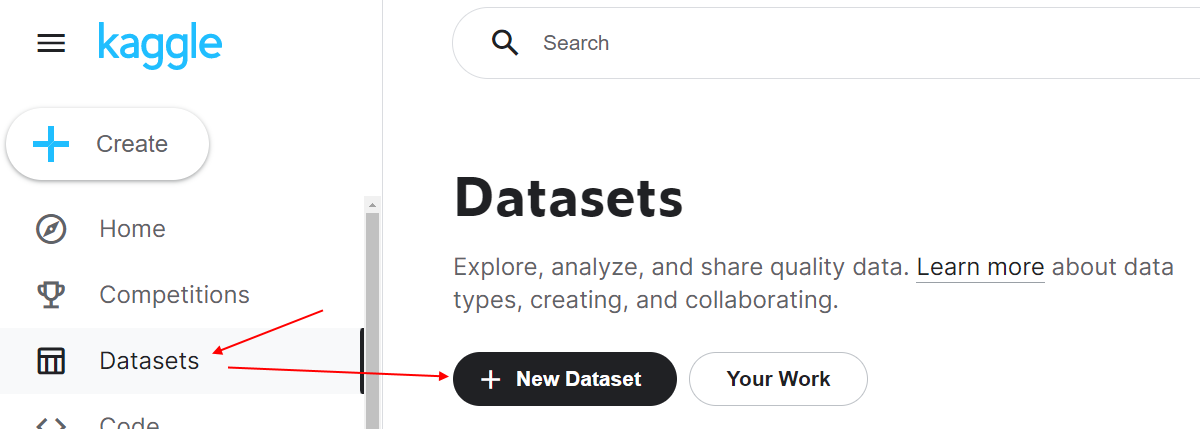
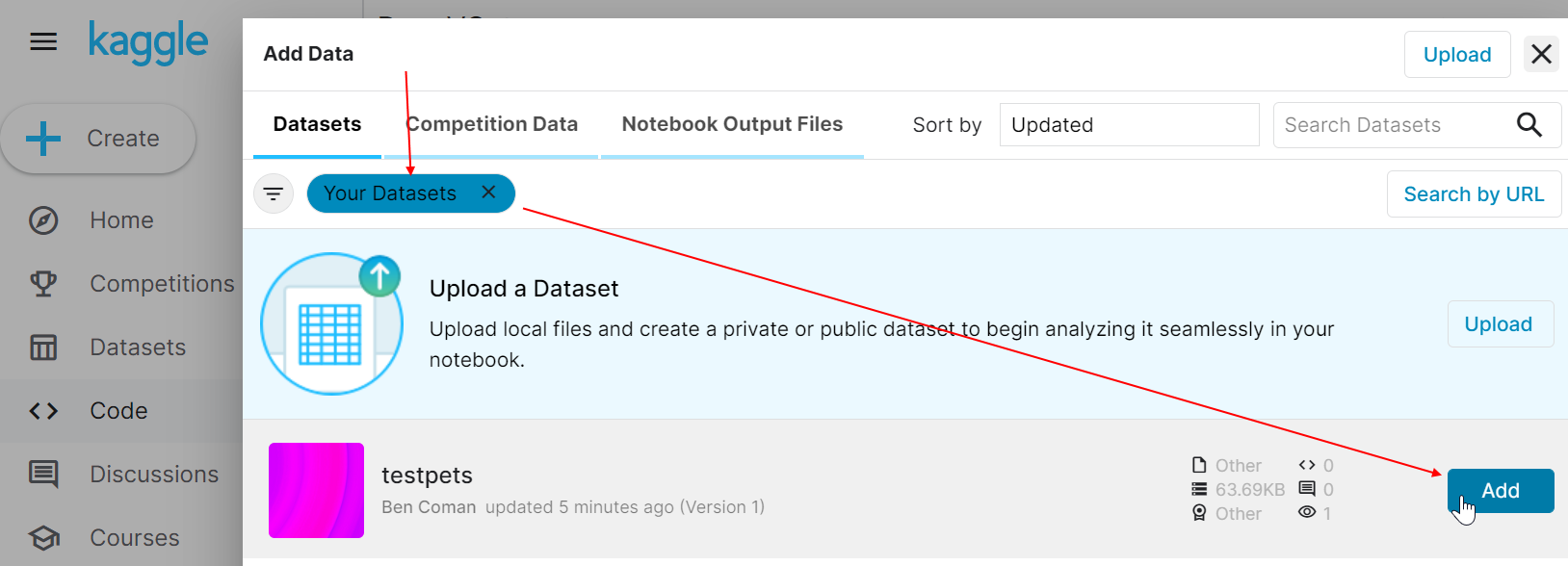
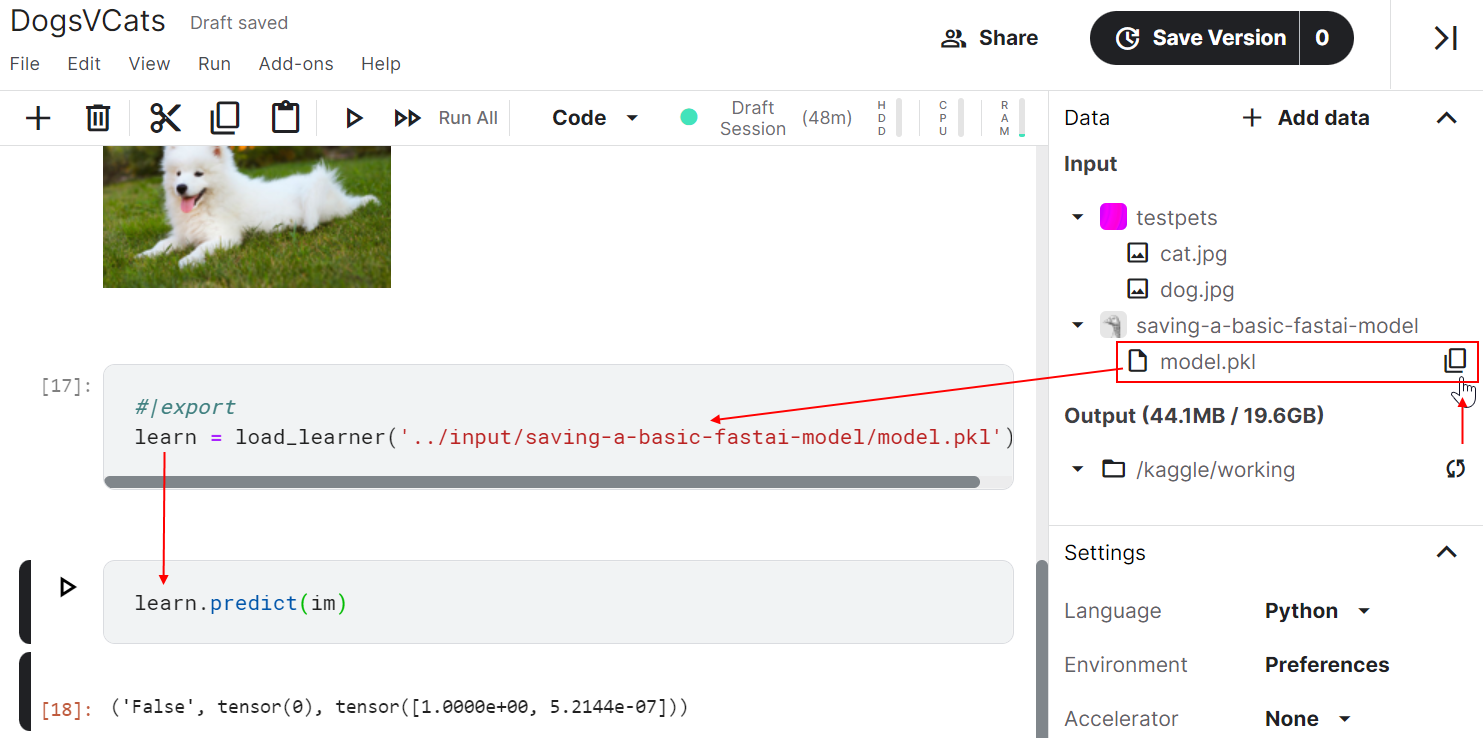
On Kaggle, I was trying to replicate the Dogs v Cats inferencing that Jeremy ran off his local machine - and had to muddle around to work out how to directly upload and reference individual test pics from my machine (rather than the web search code from Lesson 1). I’m sharing one way I found, in case its useful to others, or anyone can advise a better way.
Click Datasets in left sidebar, then click New Dataset.
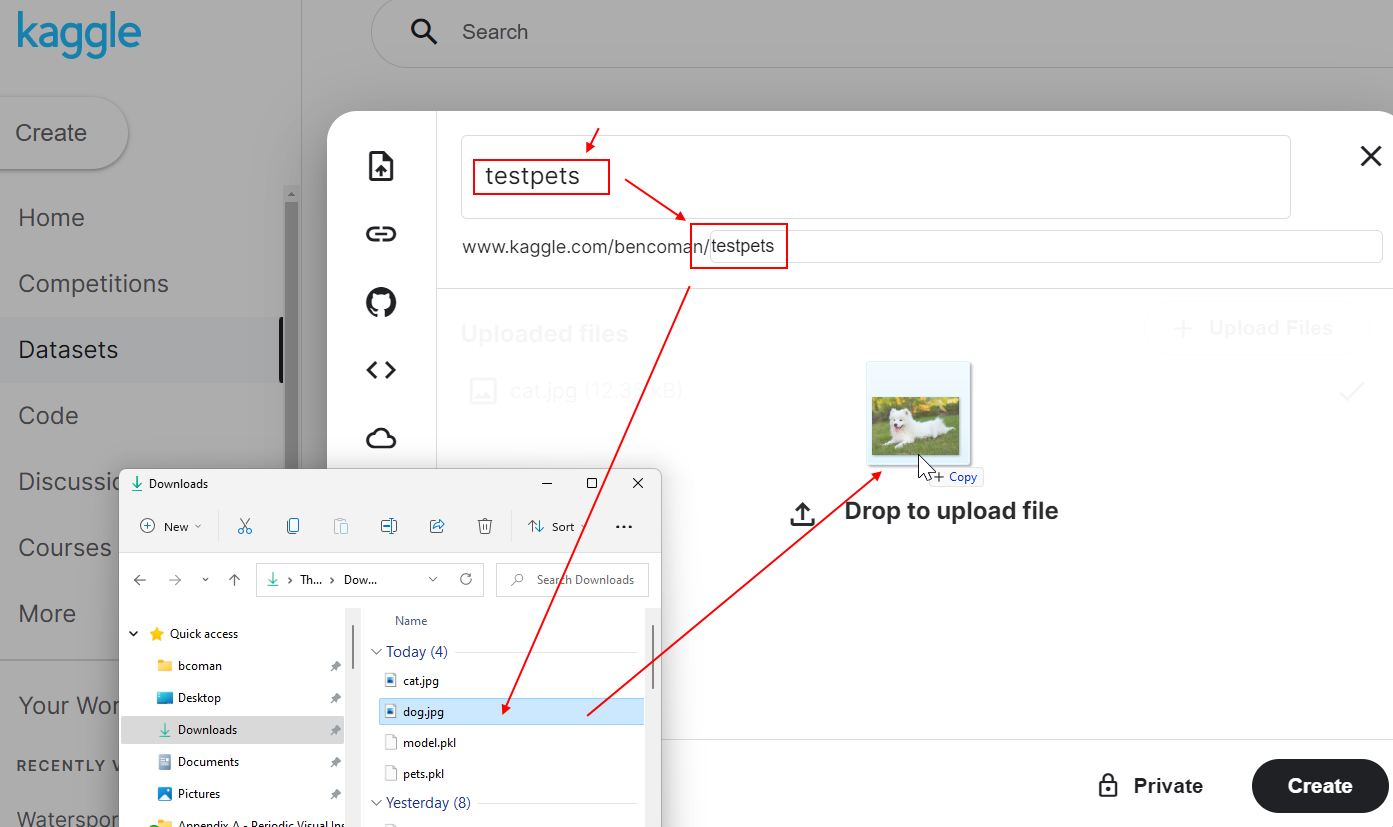
Give the dataset a name and url (like testpets), then drag files from Windows Desktop into the window…
Click Create in previous image.
Then back where we are coding, click Add data from the right sidebar.
Select Your datasets, then click Add.
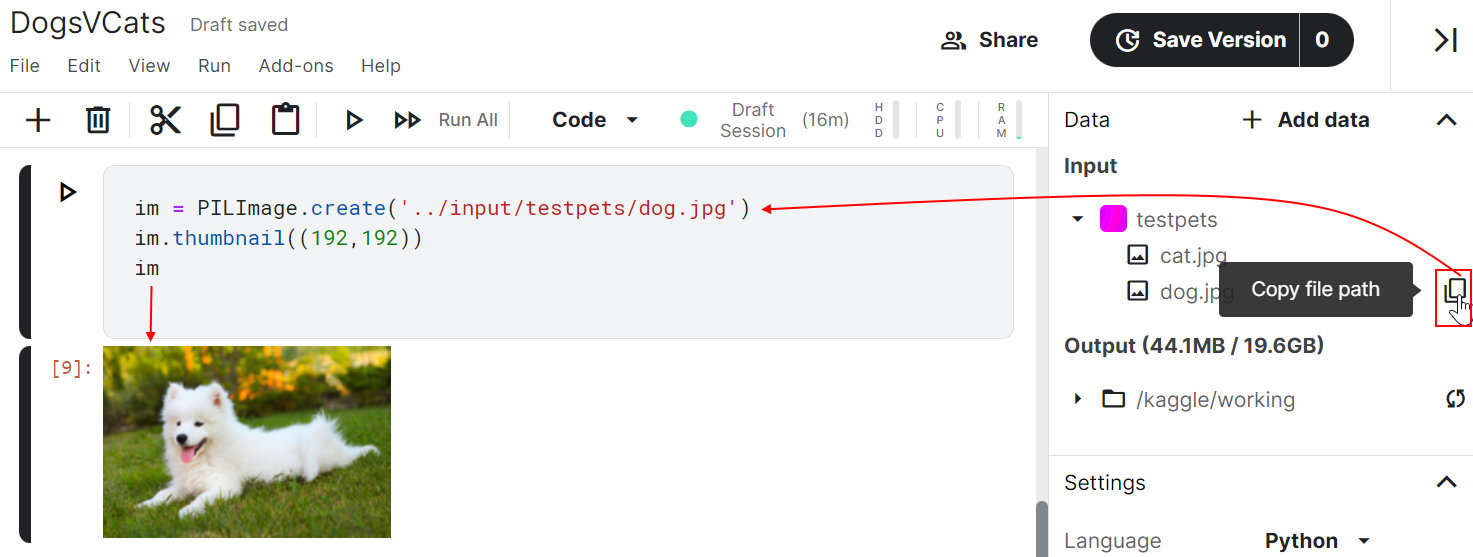
Now testpets appears as a pink square under Input.
Hover over file dog.jpg and click its Copy file path icon.
Paste that path into our code.
Execute the cell to see the pic.
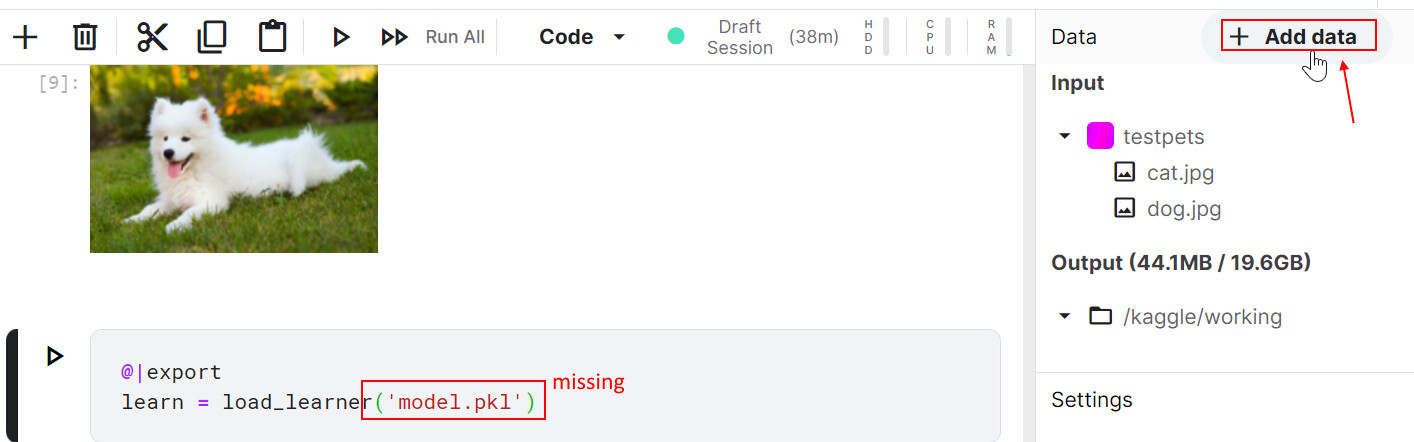
…and then I needed to do similar to reference the PKL file, so while I’m on a roll…
Click Add data in right sidebar.
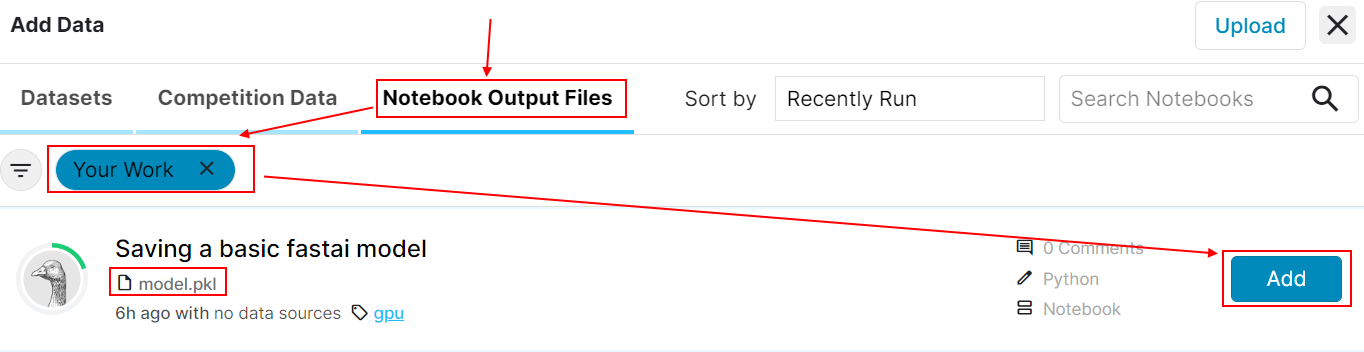
Select Notebook Output Files then Your Work.
Then click Add on the notebook that generated the model.pkl file.
Hover over file model.pkl and click its Copy file path icon.
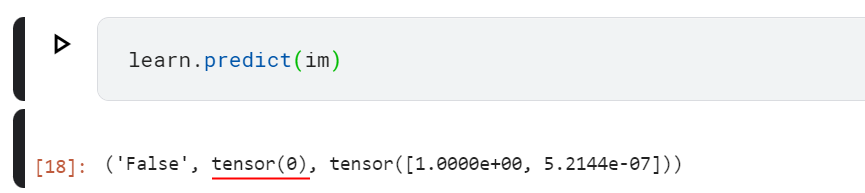
Paste that path into our code, execute that cell and then the next one to see the prediction.
A curiousity… Lesson 2 video at 44:27 shows TensorBase(0)…
but when I replicate the notebook on Kaggle it shows tensor(0)…
Conventions from my Smalltalk background have me reading the former as a class and the latter as an instance, but I think I’m reading too much into it.
I’ve got a couple of things packed in here…
Here is the my Cats v Dogs notebook in kaggle…
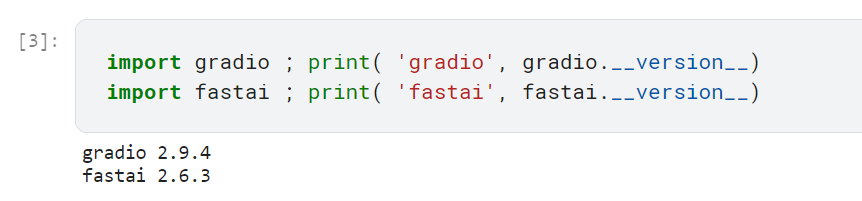
When I run the first two cells, I get a long error
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/opt/conda/lib/python3.7/site-packages/pkg_resources/__init__.py in _dep_map(self)
3030 try:
-> 3031 return self.__dep_map
3032 except AttributeError:
/opt/conda/lib/python3.7/site-packages/pkg_resources/__init__.py in __getattr__(self, attr)
2827 if attr.startswith('_'):
-> 2828 raise AttributeError(attr)
2829 return getattr(self._provider, attr)
AttributeError: _DistInfoDistribution__dep_map
During handling of the above exception, another exception occurred:
AttributeError Traceback (most recent call last)
/opt/conda/lib/python3.7/site-packages/pkg_resources/__init__.py in _parsed_pkg_info(self)
3021 try:
-> 3022 return self._pkg_info
3023 except AttributeError:
/opt/conda/lib/python3.7/site-packages/pkg_resources/__init__.py in __getattr__(self, attr)
2827 if attr.startswith('_'):
-> 2828 raise AttributeError(attr)
2829 return getattr(self._provider, attr)
AttributeError: _pkg_info
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
/tmp/ipykernel_34/1900315441.py in <module>
----> 1 import gradio ; print( 'gradio', gradio.__version__)
2 import fastai ; print( 'fastai', fastai.__version__)
/opt/conda/lib/python3.7/site-packages/gradio/__init__.py in <module>
13 from gradio.static import Button, Markdown
14
---> 15 current_pkg_version = pkg_resources.require("gradio")[0].version
16 __version__ = current_pkg_version
/opt/conda/lib/python3.7/site-packages/pkg_resources/__init__.py in require(self, *requirements)
889 included, even if they were already activated in this working set.
890 """
--> 891 needed = self.resolve(parse_requirements(requirements))
892
893 for dist in needed:
/opt/conda/lib/python3.7/site-packages/pkg_resources/__init__.py in resolve(self, requirements, env, installer, replace_conflicting, extras)
783
784 # push the new requirements onto the stack
--> 785 new_requirements = dist.requires(req.extras)[::-1]
786 requirements.extend(new_requirements)
787
/opt/conda/lib/python3.7/site-packages/pkg_resources/__init__.py in requires(self, extras)
2747 def requires(self, extras=()):
2748 """List of Requirements needed for this distro if `extras` are used"""
-> 2749 dm = self._dep_map
2750 deps = []
2751 deps.extend(dm.get(None, ()))
/opt/conda/lib/python3.7/site-packages/pkg_resources/__init__.py in _dep_map(self)
3031 return self.__dep_map
3032 except AttributeError:
-> 3033 self.__dep_map = self._compute_dependencies()
3034 return self.__dep_map
3035
/opt/conda/lib/python3.7/site-packages/pkg_resources/__init__.py in _compute_dependencies(self)
3040 reqs = []
3041 # Including any condition expressions
-> 3042 for req in self._parsed_pkg_info.get_all('Requires-Dist') or []:
3043 reqs.extend(parse_requirements(req))
3044
/opt/conda/lib/python3.7/site-packages/pkg_resources/__init__.py in _parsed_pkg_info(self)
3022 return self._pkg_info
3023 except AttributeError:
-> 3024 metadata = self.get_metadata(self.PKG_INFO)
3025 self._pkg_info = email.parser.Parser().parsestr(metadata)
3026 return self._pkg_info
/opt/conda/lib/python3.7/site-packages/pkg_resources/__init__.py in get_metadata(self, name)
1410 return ""
1411 path = self._get_metadata_path(name)
-> 1412 value = self._get(path)
1413 try:
1414 return value.decode('utf-8')
/opt/conda/lib/python3.7/site-packages/pkg_resources/__init__.py in _get(self, path)
1614
1615 def _get(self, path):
-> 1616 with open(path, 'rb') as stream:
1617 return stream.read()
1618
FileNotFoundError: [Errno 2] No such file or directory: '/opt/conda/lib/python3.7/site-packages/typing_extensions-4.2.0.dist-info/METADATA'
If I then execute the second cell again, it works…
but I don’t trust that, since I wasn’t sure if it might have ended up partially loaded, and later I get the error…
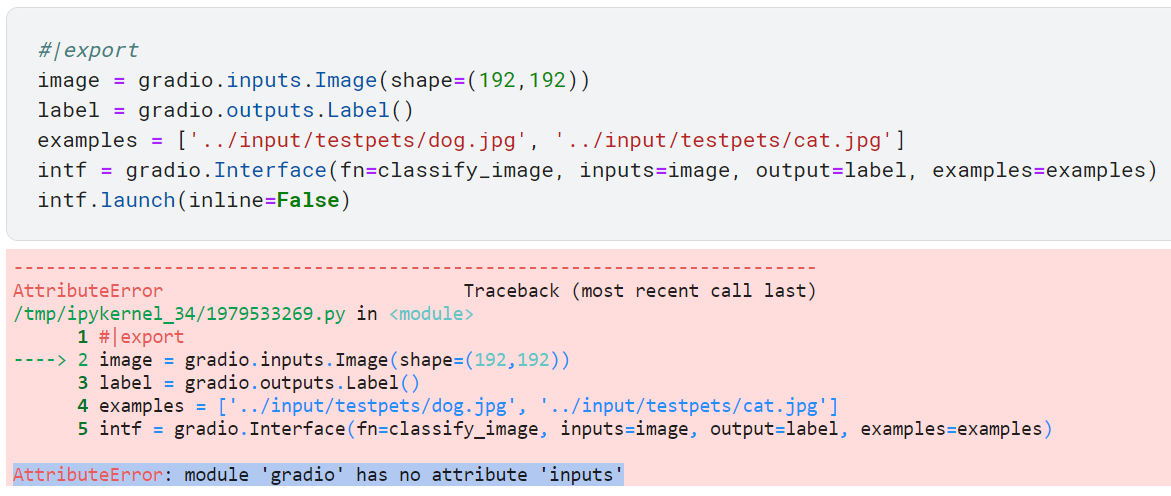
AttributeError: module ‘gradio’ has no attribute ‘inputs’
NEXT…
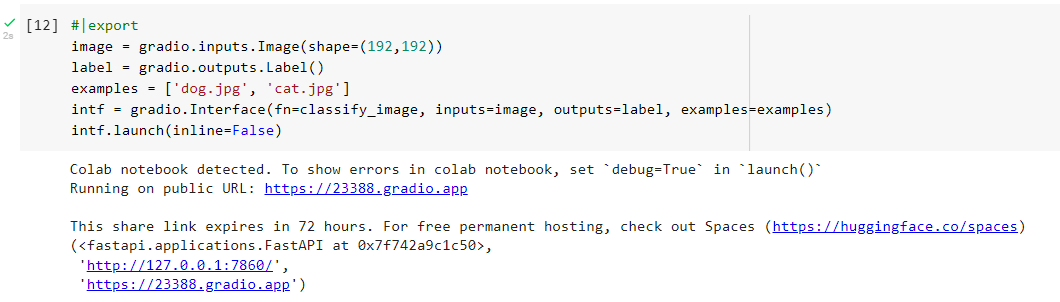
When I download that Kaggle notebook and upload to this Colab notebook, the gradio part works out of the box…
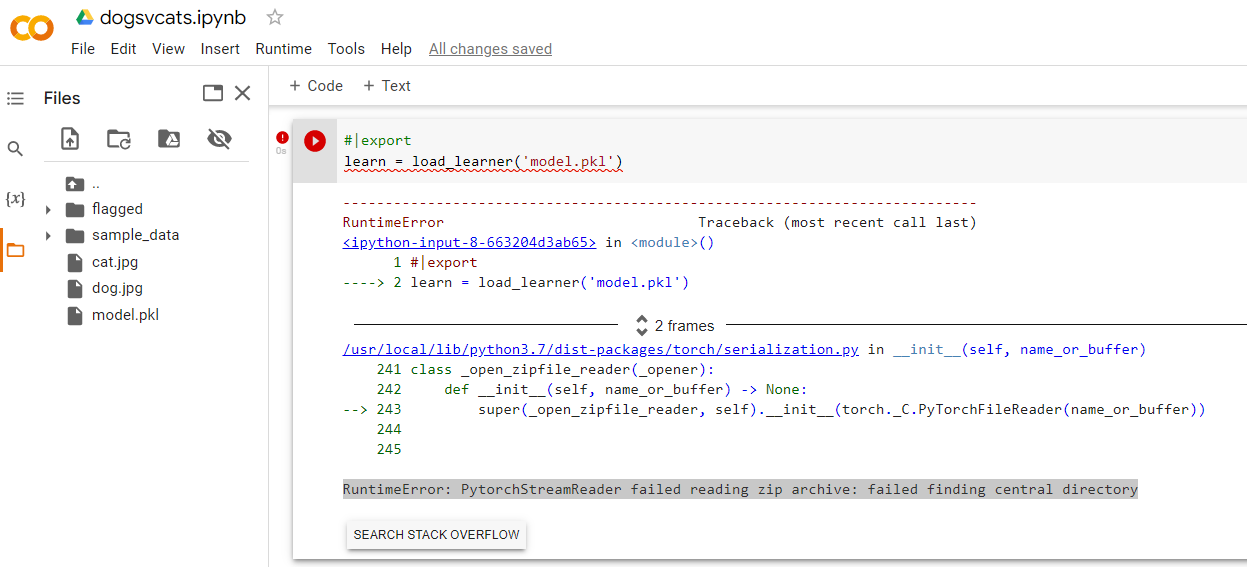
BUT, now load_learner() fails…
My google-fu fails me. This error message RuntimeError: PytorchStreamReader failed reading zip archive: failed finding central directory…
bcoman@OFI-PC-0004:~/huggingface/minima$ md5sum model.pkl
87a0336b796edbf0ffb62cacc66d7511 model.pkl
the pretrained model I used, had saved the model wholesomely ( saved it like torch.save({‘model’: model}) and as you know, this is very bad, since in order to use that model, you need to have the same module/file/dir heirarchy or else it will crash.
I tried to convert this model into torch script, it went fine, but upon using I faced this error.to solve this, I simply first saved the models state_dict() into a new checkpoint file, loaded from the new checkpoint and then converted my model.