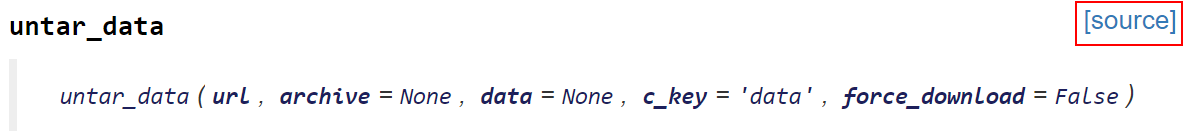BTW, when I import your notebook into Kaggle and run it, I get the following error for learn.lr_find() which is 3rd cell from the bottom of the notebook:
> /opt/conda/lib/python3.7/site-packages/torch/nn/functional.py in cross_entropy(input, target, weight, size_average, ignore_index, reduce, reduction)
> 2822 if size_average is not None or reduce is not None:
> 2823 reduction = _Reduction.legacy_get_string(size_average, reduce)
> -> 2824 return torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index)
> 2825
> 2826
>
> IndexError: Target 255 is out of bounds.
I did not see any GPU exhaustion at all, I think it dies before things get to the GPU (just a guess)
From that it seems you don’t “specify” dest. Its implied from the fixed base and the default c_key=‘data’ that produces the path for the documentation example…
If you look up to Line 115 you can see how fname is determined from url.
This is the first time of looked at this code, so I’m only guessing, but your options seem to be…
Use the data from the default download position.
Copy the untar_data() function into your code as my_untar_data() and play with the parameter values used with FastDownload and get (i.e. maybe base ??).
Unless there is a compelling reason, the Option 1 default is probably your path of least resistance.
From what I can tell it’s a wrapper around fastdownload and in the fastdownload docs it states that you can change ‘base’ to any directory you want. By default {base} points to ~/.fastdownload or something
EDIT: But I see what you’re saying, base can’t be reached from untar_data()
Instead of get, use download to download the URL without extracting it, or extract to extract the URL without downloading it (assuming it’s already been downloaded to the archive directory). All of these methods accept a force parameter which will download/extract the archive even if it’s already present.
You can change any or all of the base, archive, and data paths by passing them to FastDownload:
d = FastDownload(base=‘~/.mypath’, archive=‘downloaded’, data=‘extracted’)
Jeremy then showed the Image Classifier Cleaner, and Nick said it pays to visually inspect when using these “open” image searches by @JaviNavarro post.
I’m running into difficulty with ImageClassifierCleaner(learn).
delete() works as expected:
for idx in cleaner.delete(): cleaner.fns[idx].unlink()
change(), however, fails:
for idx,cat in cleaner.change(): shutil.move(str(cleaner.fns[idx]), path/cat)
---------------------------------------------------------------------------
Error Traceback (most recent call last)
/tmp/ipykernel_27738/4259621786.py in <module>
----> 1 for idx,cat in cleaner.change(): shutil.move(str(cleaner.fns[idx]), path/cat)
~/anaconda3/lib/python3.9/shutil.py in move(src, dst, copy_function)
810
811 if os.path.exists(real_dst):
--> 812 raise Error("Destination path '%s' already exists" % real_dst)
813 try:
814 os.rename(src, real_dst)
Error: Destination path 'four_seasons/summer/00000129.jpg' already exists
The problem appears to occurs because search_images_ddg() indexes each category independently, starting with 00000000.jpg. This results in duplicate fnames across categories. Accordingly, attempting to change an image from one category to another results in a collision and the code fails.
I can come up with a work around, but wonder if anyone has solved this particular problem?
Maybe there is a utility I missed in the fastai code base. I will look more closely.
Hi @mike.moloch sorry, I totally appreciate Jeremy must get a lot of @ mentions. Is there a better place to post this? I am taking the course in Brisbane and I don’t yet have an intuition with the library to know what common errors are caused by.
Interestingly I don’t see that IndexError.
My environment is a self provisioned VM on GCP.
Its 8 core, 32gb of ram, T4 with Fresh Ubuntu 22.04 and nvidia 470 drivers, python 3.10 and a virtualenv with a fresh install of fastbook and fastai in the directory. I pulled the example notebook mentioned and ran it and it works fine with this hardware and python environment. At first it looked like it was allocating to the MAX of the GPU but now that I have lowered the image size the memory looks well under the limit when the error occurs as per my screenshot above.
I included a full fresh run from top to bottom of my notebook in the git link I posted above to help debug the issue.
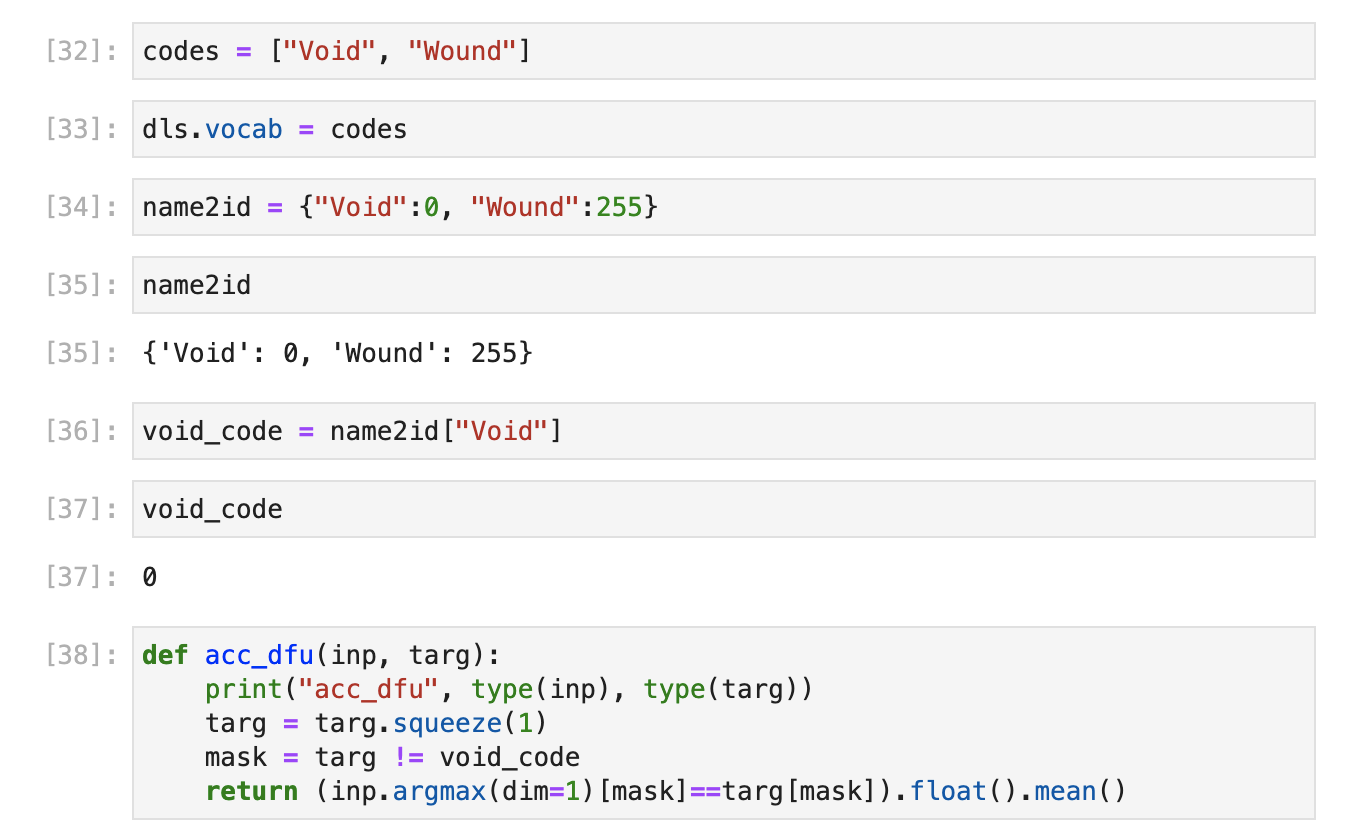
The original notebook has multiple classes and uses a few different functions to detect and set them against a dict of codes.
For mine there appears to be only 1 class and I think its represented by 255, while the void is 0.
Why would 255 be out of bounds, surely thats within 8 bit range?
Do I need to change the mask values so that they are say 0 for void and 1 for the first label or something?
I tried to run it without the Normalize function in the DataBlock (which probably uses the wrong stats but that didn’t change anything).
Here is the other code which relates to the mask and codes.
Any help would be greatly appreciated. I searched the notebooks and I can see its not part of fastbook so I understand im going a little off piste here.
Change download_images to include a new parameter start_idx and have download_images return next_idx so a subsequent call to download_images has a new start_idx
No breaking changes for existing users. Some added complexity for multiple categories, but with the return of next_idx, not too bad.
Create a new function to wrap around:
shutil.move(str(cleaner.fns[idx]), path/cat)
This function would check to see if fname exits and if so, created a unique fname. To the extent fnames are being used for labeling this could get complicated.
Create a utility function reindex_dir that would analyze an existing directory and recreate fnames as specified by the function. Perhaps a signature similar to this:
I never really used github desktop (only used to store my notebooks) nor console but I am assuming the github desktop is easier to use.
Can someone please help me create app.py file (I only used notebooks before) using github console? I followed the video but didn’t work.