3 posts were merged into an existing topic: Help: Basics of fastai, PyTorch, numpy, etc 
2 posts were merged into an existing topic: Help: SGD and Neural Net foundations
On default it will be pth. But you can specify that see learner.export docs here Learner, Metrics, and Basic Callbacks | fastai
2 Likes
The flags look different than those used in nbdev. I don’t remember seeing the pipe operator. Is that something new in nbdev?
5 Likes
I think Jeremy may be using a new version of nbdev which is under development right now…
3 Likes
For setting up with fastsetup, how much memory is required. Can it be used for CPU installation also?
1 Like
The Lex Fridman podcast with Travis Oliphant creator of Numpy and Conda is really interesting, re the topic of Conda (or Mamba) vs Pip. Opened my eyes to some of the issues using Pip with libraries that rely on non-Python dependancies.
Conda/Mamba is a sensible default for data science tooling in Python. Favour it over Pip if you want to keep your sanity imo.
10 Likes
For the code we have seen so far, CPU based setup is sufficient. This is because we are using small model (+ transfer learning), with small image size (224x224), so don’t acutally need an accelerator.
4 Likes
A handy fastai func for checking the installed versions. Creates a string for sharing when debugging or reporting issues.
from fastai.test_utils import show_install
show_install()
=== Software ===
python : 3.7.11
fastai : 2.5.4
fastcore : 1.3.27
fastprogress : 0.2.7
torch : 1.9.1
nvidia driver : 471.41
torch cuda : 11.1 / is available
torch cudnn : 8005 / is enabled
=== Hardware ===
nvidia gpus : 1
torch devices : 1
- gpu0 : NVIDIA GeForce RTX 3090
=== Environment ===
platform : Linux-5.10.43.3-microsoft-standard-WSL2-x86_64-with-debian-bullseye-sid
distro : #1 SMP Wed Jun 16 23:47:55 UTC 2021
conda env : fastaidev
python : /home/laplace/miniconda3/envs/fastaidev/bin/python
sys.path : /mnt/d/projects/blog/wip/
/home/laplace/miniconda3/envs/fastaidev/lib/python37.zip
/home/laplace/miniconda3/envs/fastaidev/lib/python3.7
/home/laplace/miniconda3/envs/fastaidev/lib/python3.7/lib-dynload
/home/laplace/miniconda3/envs/fastaidev/lib/python3.7/site-packages
/mnt/d/projects/fastcore
/mnt/d/projects/fastai
/home/laplace/miniconda3/envs/fastaidev/lib/python3.7/site-packages/IPython/extensions
/home/laplace/.ipython
19 Likes
One issue with github pages is now you need to make your repo public to use it for free. Is there any good alternatives for static website hosting which you have tried out?
1 Like
I also started with Jekyll and GitHub Pages for my personal website, but eventually migrated to a custom Go solution hosted on Digital Ocean. I didn’t mind keeping the source open; however, I found it a bit inconvenient and somewhat limited for my purposes. Still, a great way to start! You can rewrite it later. Especially, if you have a domain name that you can easily redirect to another platform.
5 Likes
Another great lesson! Thanks for the major shout-out Jeremy, was not expecting it 
13 Likes
5 posts were merged into an existing topic: Help: Creating a dataset, and using Gradio / Spaces
Hi all, really enjoyable lesson again today, all the gradio/streamlit chat is inspiring me to try and plan a project with fast.ai. so on to my main question:
Has anyone done any pose estimation with fast.ai before?
Tim
1 Like
5 posts were merged into an existing topic: Help: Using Colab or Kaggle
There is an example of head pose (see Computer vision | fastai Points).
This new approach is now supported in the latest nbdev and will be the default in the future. We’ll be integrating with Quarto, and that’s what they use.
5 Likes
Awesome lecture @jeremy, I know that this is a little ahead of the class but I already know what I wanted to work on and it partially involves segmentation and I found a great notebook from Zachary Mueller and thought I would give it a shot.
I think loading the pretrained weights fails, so I commented that out too.
Maybe it’s the Normalization function? I tried commenting that out and its the same error.
I got the images and labels to load but im getting a GPU error.
I made it so the notebook is easily re-runable and automatically downloads the dataset it uses:
Warning its medical so the images are a bit gross.
I played around with resnet sizes and image sizes and I dont think its an OOM. The CamVid notebook from Zachery can run lr_finder and fit fine, so I guess its my data / accuracy / optimization functions?
I think theres only 1 class which might be an issue, but I have no idea where you would configure that.
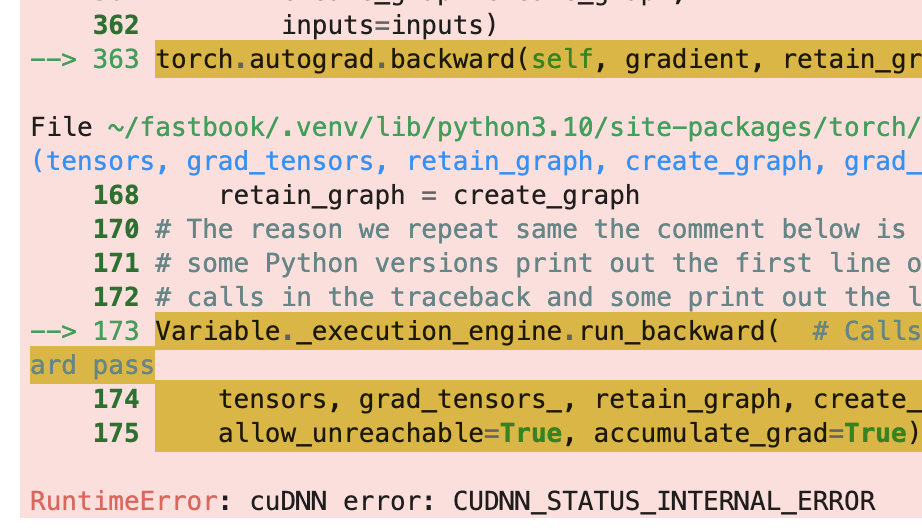
Does anyone know what this issue is with?
I have a T4 and it looks like the memory is fine.

import torch
torch.cuda.is_available()
True!!!
Wow GPU enabled WSL that easy. I’ve been battling with cuda enabled WSL with docker blah blah for ages but that method Jeremy showed us was easy as. For those doing it from scratch I did very close to what he showed us but had to git clone the repo from within my wsl (linux) so it didnt change the UNIX line endings (whatever that means). Then running
source setup-conda.sh
worked. Also I followed these CUDA WSL instructions (<=section 3). Which is exactly same except recommends to get the right cuda-wsl driver from nvidia. So then I cloned the books repo but also had to run sudo apt-get install graphviz in the wsl to get the graphs to display. BUT yeah local GPU accelerated fast.ai here we come! Thanks!
7 Likes
Please don’t get it the wrong way, and I’ve done this myself in the past, but just a quick reminder that Jeremy has indicated not to at-mention admins unless it’s an admin issue. If you just state the issue clearly, people would be more than happy to help.
Also, it would be really helpful if the screenshot gave some context of what it is that was being executed that gave that error. All I can tell from this error is that you got some kind of a generic error. As is the case in 90% of debugging situations, usually the generic error you get is not the issue.
You’ll find that most people on this forum are quite helpful, but they’d need the OP to give some kind of context, ie; “you need to help them help you”. For example, even if I try to reproduce your problem, here are the things I’d need to know:
- What cell are you trying to run that gives that error?
- Which environment were you running it in? (Kaggle notebook, Colab, your home machine?)
- what is your setup like?
These things would be helpful so that if someone tries to help you, they wouldn’t spend an inordinate amount of time asking follow up clarifying questions about specifics of the problem that can be very easily provided in the original question and so that their valuable time trying to help is also minimized.
HTH
1 Like